
Khi Anthropic phát hành mẫu mới Mythos vào tháng 4, phòng thí nghiệm AI đã đồng loạt đưa ra cảnh báo mạnh mẽ đối với ngành phát triển phần mềm. Có thể nói, mô hình này có khả năng khai thác cực kỳ cao các lỗ hổng bảo mật phần mềm và đã phát hiện ra hàng nghìn lỗ hổng có nguy cơ cao. Mô hình không thể mở hoàn toàn với thế giới bên ngoài cho đến khi những vấn đề này được khắc phục.
Bây giờ, lần đầu tiên, các nhà nghiên cứu bảo mật trình duyệt Mozilla Firefox đã tiết lộ một cách có hệ thống các chi tiết về cách thức hoạt động của quy trình này trong kỹ thuật thực tế và cố gắng giải thích ý nghĩa của Mythos đối với hệ sinh thái bảo mật phần mềm tổng thể. Mozilla cho biết trong một bài đăng hôm thứ Năm rằng Mythos đã phát hiện ra một số lỗ hổng có mức độ nghiêm trọng cao trong Firefox, một số lỗ hổng này đã không hoạt động trong mã trong hơn một thập kỷ.
Chỉ trong nửa năm, đã có bước nhảy vọt đáng kể về tính hữu dụng của các công cụ bảo mật AI. Trước đây, nhiều công cụ kiểm tra lỗi tự động AI khác nhau thường rất ồn ào, thường xuyên khiến đội ngũ bảo mật phải nhận những báo cáo có chất lượng kém và số lượng lớn thông báo sai, khiến đội ngũ kỹ thuật phải chật vật đối phó. Các nhà nghiên cứu của Mozilla tin rằng thế hệ công cụ mới đã "đạt đến điểm uốn", đặc biệt là sau khi nó có khả năng "giống như tác nhân". Mô hình có thể thực hiện đánh giá thứ cấp và sàng lọc các kết quả phân tích của chính nó, từ đó lọc ra một số lượng lớn kết quả đầu ra không đáng tin cậy.
“Thật khó để nói quá mức độ ảnh hưởng của sự thay đổi này đến chúng ta trong vòng vài tháng,” các nhà nghiên cứu viết. "Trước hết, bản thân khả năng của các mô hình đã được cải thiện đáng kể; thứ hai, công nghệ của chúng tôi về cách điều khiển các mô hình này cũng đã được cải thiện nhanh chóng."
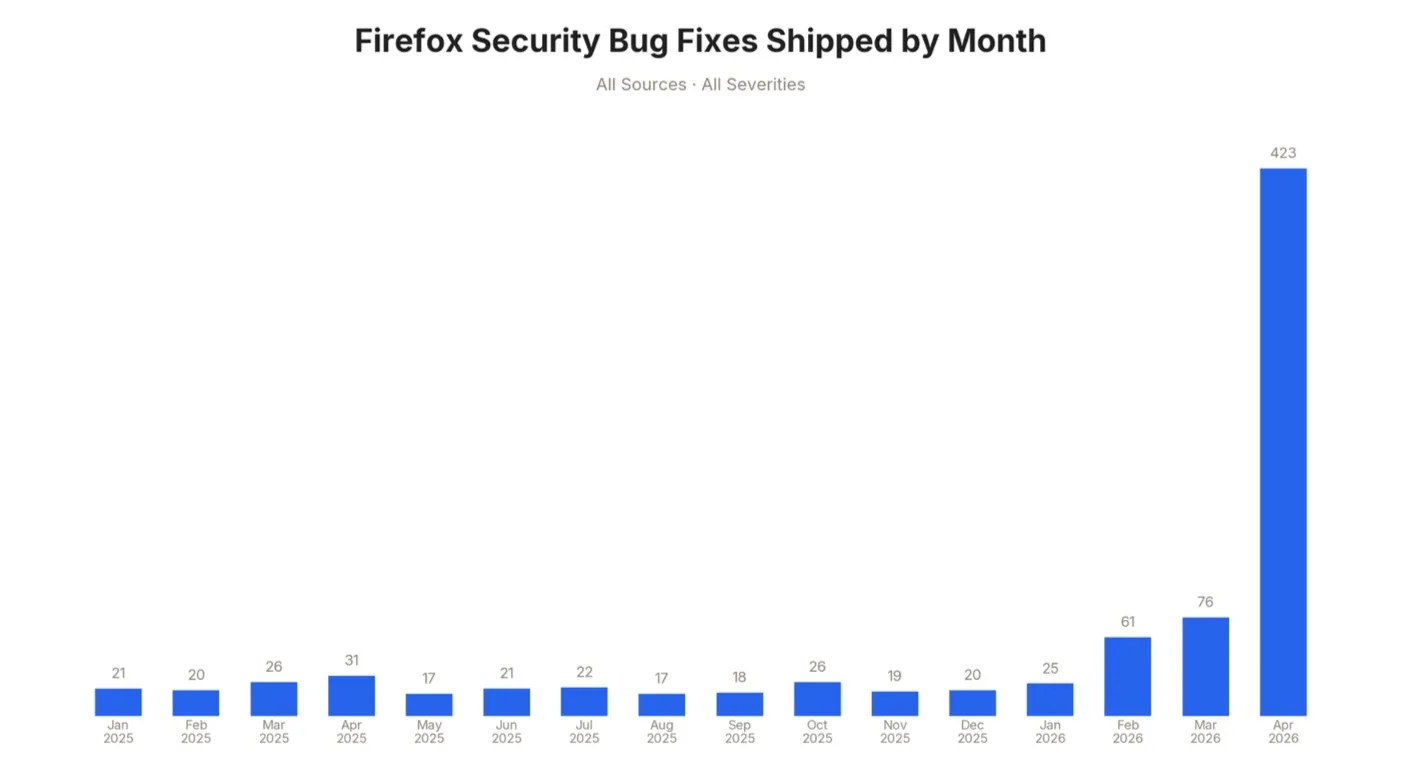
Cụ thể ở cấp độ kết quả, những thay đổi đặc biệt trực quan: Vào tháng 4 năm 2026, Firefox đã phát hành tổng cộng 423 bản vá sửa lỗ hổng, trong khi cùng tháng năm ngoái, con số này chỉ là 31. Nhóm nghiên cứu cũng tiết lộ chi tiết kỹ thuật của 12 lỗ hổng, bao gồm hai lỗi cơ chế bảo mật sandbox hiếm gặp và một lỗi phân tích thành phần HTML 15 năm tuổi.
“Những công cụ này thực sự đột nhiên trở nên rất hữu ích,” Kỹ sư xuất sắc của Mozilla, Brian Grinstead cho biết trong một cuộc phỏng vấn với TechCrunch. “Chúng tôi thấy điều này trên hệ thống quét nội bộ của mình, chúng tôi thấy xu hướng tương tự trong các báo cáo về lỗ hổng được gửi bên ngoài và trên toàn ngành.”
Một trong những điểm nổi bật nhất là Mythos đã giúp phát hiện ra một số lỗ hổng liên quan đến cơ chế "sandbox" của trình duyệt. Trong ngành, loại lỗ hổng này luôn được coi là một trong những lỗ hổng khó phát hiện và có hại nhất: để tìm và xác minh thành công các lỗ hổng sandbox, mô hình không chỉ có khả năng viết một bản vá với những thay đổi độc hại mà còn phải quản lý để tấn công các phần được bảo vệ nhất của trình duyệt sau khi giới thiệu mã mới này. Quá trình này đòi hỏi phải duy trì tính logic chặt chẽ và đủ tính sáng tạo giữa các hoạt động gồm nhiều bước và khó khăn hơn nhiều so với việc khai thác lỗi thông thường.
Giá trị còn có thể được nhìn thấy ở khía cạnh khuyến khích kinh tế. Chương trình tiền thưởng lỗi của Mozilla cung cấp phần thưởng tối đa 20.000 USD cho các lỗ hổng hộp cát của Firefox, giới hạn phần thưởng cao nhất trong bất kỳ danh mục lỗ hổng nào. Tuy nhiên, Grinstead cho biết Mythos hiện đã tìm thấy nhiều vấn đề liên quan đến hộp cát hơn những gì mà các nhà nghiên cứu bảo mật con người đã phát hiện ra thông qua các khoản tiền thưởng trước đây cộng lại. Ông nói: “Chúng tôi nhận được báo cáo về các lỗ hổng sandbox, nhưng khối lượng không bằng những gì chúng tôi chủ động khám phá bằng công nghệ mới này.”
Điều đáng chú ý là mặc dù ngành đã có tiến bộ rõ ràng trong các công cụ tạo mã AI, nhóm Firefox hiện không dựa vào AI để trực tiếp khắc phục các lỗ hổng này. Nhóm sẽ yêu cầu mô hình cố gắng tạo các bản vá dựa trên từng lỗ hổng, nhưng những mã được tạo tự động này thường không thể được tích hợp trực tiếp vào xương sống và chỉ có thể được sử dụng làm mẫu tham chiếu để các kỹ sư con người viết các bản sửa lỗi.
“Đối với mỗi lỗ hổng được đề cập trong bài viết này, một kỹ sư đã hoàn thành việc viết bản vá và một kỹ sư khác đã hoàn thành việc xem xét mã.” Grinstead nhấn mạnh. “Chúng tôi vẫn chưa tìm ra cách đáng tin cậy để tự động hóa hoàn toàn quá trình này.”
Ở cấp độ vĩ mô hơn, vẫn chưa rõ sự phát triển nhanh chóng của khả năng AI sẽ thay đổi cán cân quyền lực giữa tấn công và phòng thủ mạng như thế nào. Đã hơn một tháng kể từ khi phiên bản xem trước của Mythos được phát hành, hầu hết các lỗ hổng được phát hiện vẫn đang trong quá trình sửa chữa, điều này cũng có nghĩa là thế giới bên ngoài khó có thể đánh giá đầy đủ về tác động lâu dài của nó. Anthropic đã tuân thủ nghiêm ngặt các biện pháp tiết lộ có trách nhiệm và dần dần truyền đạt thông tin chi tiết về lỗ hổng bảo mật với các dự án liên quan, nhưng có lý khi suy đoán rằng một số tác nhân độc hại cũng đang thử các kỹ thuật tương tự một cách riêng tư, ngay cả khi các mô hình mà chúng sử dụng vẫn kém hơn về khả năng.
Tại một sự kiện công cộng gần đây, Giám đốc điều hành Anthropic Dario Amodei tương đối lạc quan về xu hướng này. Theo quan điểm của ông, nếu ngành này quy định hợp lý cách sử dụng những công cụ như vậy, những người bảo vệ có thể sẽ ở vị trí tốt hơn hiện nay. Amodei cho biết: “Nếu chúng tôi làm đúng, chúng tôi hy vọng sẽ đạt được tình huống an toàn hơn so với lúc đầu vì chúng tôi sẽ sửa từng lỗ hổng này”. “Tổng số lỗ hổng là có hạn nên có thể mở ra một thế giới tốt đẹp hơn sau này.”
Ngược lại, Grinstead, người đã giải quyết các lỗ hổng ở tuyến đầu trong một thời gian dài, lại thận trọng hơn. Ông nói: “Công cụ này hữu ích như nhau cho cả người tấn công và người phòng thủ, nhưng sự phổ biến của nó ít nhất đã phần nào nghiêng lợi thế về phía người phòng thủ”. "Một tuyên bố thực tế hơn là không ai có thể thực sự đưa ra câu trả lời cuối cùng cho câu hỏi này vào lúc này."