Opus 4.7 đã được phát hành cách đây 48 giờ và danh tiếng bị chia cắt. Danh sách chính thức đứng đầu thế giới, nhưng bài kiểm tra công khai về lý luận logic đã giảm mạnh từ 94,7% xuống 41,0%. Mức tiêu thụ mã thông báo tăng 35%, giao diện cũ trực tiếp báo lỗi và người dùng phàn nàn chung rằng nó "đắt hơn, ngu ngốc hơn và có nhiều khả năng phản bác lại hơn". Chính xác thì Anthropic đã nâng cấp cái gì và nó đã gây ra vấn đề gì?
"4.6 hoàn toàn không sử dụng được, 4.7 tiêu thụ nhanh như lò phản ứng hạt nhân."
Opus 4.7 đã được phát hành, một người dùng Reddit đã để lại tin nhắn dưới bài đăng chính thức của Anthropic.
Đó không phải là chuyện đùa, đó là sự thật.

Một bài đăng trên Reddit "Claude Opus 4.7 là một bản hồi quy nghiêm trọng, không phải bản nâng cấp" nhanh chóng đạt tới 3.000 lượt thích.
Một số người đã đăng ảnh chụp màn hình, nói rằng ở phiên bản 4.7, họ thậm chí không thể trả lời một số chữ cái trong dâu tây.
Chưa kể đến việc "giả mạo sơ yếu lý lịch và ngụy tạo bằng cấp học thuật và họ mà không được phép", trả lời người dùng rằng "Tôi quá lười để xác minh chéo" và "đạt giới hạn sau khi hỏi ba câu hỏi" là một số thủ thuật phổ biến giữa các cư dân mạng.
Sau khi dùng thử, Gergely Orosz, tác giả cuốn "Pragmatic Engineer", đã mô tả mô hình này là "hung hăng đến không ngờ" rồi bỏ cuộc và chuyển về 4.6.

Việc mắng mỏ ở đây vẫn chưa lắng xuống mà một bộ dữ liệu đằng kia lại chỉ ra hướng ngược lại.
Phân tích nhân tạo đã mang lại cho Opus 4.7 điểm Chỉ số thông minh là 57, đứng đầu thế giới với GPT-5.4 và Gemini 3.1 Pro.
Doanh nhân Jeremy Howard đã mô tả nó là “mô hình đầu tiên thực sự hiểu những gì tôi đang làm tại nơi làm việc” và Giám đốc điều hành Y Combinator Garry Tan đang sử dụng nó cho các dự án.
Một số cư dân mạng cho rằng Claude Opus 4.7 đã đạt được trí tuệ nhân tạo tổng quát (AGI).
Với cùng một mô hình, một số người nhìn thấy bóng dáng của AGI và một số cảm thấy rằng quy trình làm việc của họ đã bùng nổ.
Hai ngày sau khi lên mạng, Opus 4.7 đã xé tan cộng đồng AI.
Tại sao người dùng lại phát nổ?
Tách rời, sự tức giận của người dùng tập trung vào ba điểm, mỗi điểm đều đánh vào sinh lực của người dùng nhiều.
Đầu tiên, khả năng của mã đã rơi xuống vực thẳm . Một số lượng lớn các nhà phát triển đã báo cáo rằng sau khi nâng cấp từ 4.6 lên 4.7, các tác vụ lập trình lẽ ra có thể hoàn thành ổn định trước đó bắt đầu xảy ra lỗi thường xuyên.
Và chúng đều là các hoạt động cốt lõi trong quy trình làm việc hàng ngày: quá trình hoàn thành mã trở nên chậm, khả năng hiểu ngữ cảnh suy giảm và khả năng suy luận của chuỗi logic phức tạp trở nên yếu hơn đáng kể.
Khả năng mã hóa là con át chủ bài của dòng Opus. Bây giờ con át chủ bài có vấn đề, sức bật đương nhiên sẽ mạnh nhất.
Một người dùng Reddit cho biết anh ấy đã sử dụng một tác vụ tái cấu trúc kéo dài với câu trả lời đã biết để kiểm tra hồi quy. Kết quả là mô hình tự tin trượt 3 bài kiểm tra mà lẽ ra có thể đạt dưới 4.6 và chỉ có thể bị roll back.

Phần bình luận tràn ngập hàng trăm trải nghiệm tương tự.
Thứ hai, sự hồi quy về chất lượng lý luận .
Nó không đơn giản như việc chậm lại, đó là sự suy thoái rõ rệt về chiều sâu suy nghĩ. Những vấn đề phức tạp trước đây được giải quyết trong một bước giờ đây đòi hỏi phải đặt câu hỏi nhiều lần và hướng dẫn thủ công.
Ngành AI kịch bản này không còn xa lạ nữa. Cuộc tranh cãi về "giảm trí thông minh" do GPT-4 Turbo gây ra năm ngoái gần như giống hệt nhau: điểm chạy đã được cải thiện, nhưng trải nghiệm lại giảm sút.
Thứ ba, tiêu nhiều tiền hơn và nhận được trải nghiệm tồi tệ hơn.
Bản thân Opus là mẫu đắt nhất của Anthropic.
Hóa đơn API hàng tháng cho người dùng nhiều không phải là số tiền nhỏ. Sau khi chi thêm tiền, nâng cấp lên phiên bản mới hơn nhưng lại có trải nghiệm tệ hơn, sự tức giận không dừng lại ở mức độ kỹ thuật.
điểm chuẩn mạnh hơn
Nhưng người dùng không mua nó
Đối mặt với phản ứng dữ dội, phản ứng của Anthropic tốc độ không hề chậm.
Anthropic đã chỉ ra trong hướng dẫn di chuyển chính thức rằng Opus 4.7 có một số thay đổi về hành vi so với 4.6. Nó cũng nhấn mạnh rằng Opus 4.7 vẫn là mô hình toàn diện nhất hiện có và thực hiện đặc biệt tốt trong các nhiệm vụ tác nhân dài hạn, công việc dựa trên kiến thức, nhiệm vụ trực quan và nhiệm vụ trí nhớ.

Kết quả đánh giá đa chiều của Phân tích nhân tạo cũng có ở đó. Điểm số của Opus 4.7 về lý luận toán học, hiểu đa ngôn ngữ và xử lý ngữ cảnh dài đã đạt mức cao mới ở nhiều chiều.
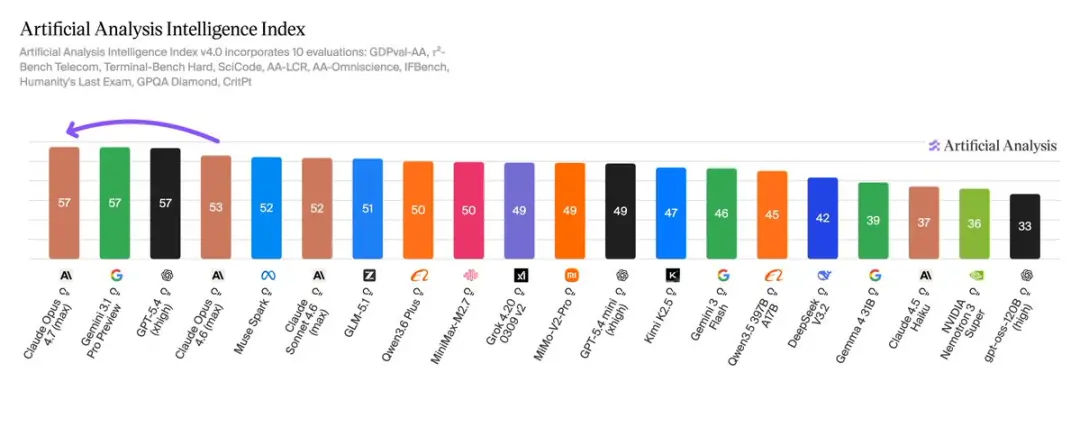
Đánh giá Phân tích nhân tạo cho thấy Opus 4.7 (tối đa) đứng đầu với 57 điểm, ngang bằng với Gemini 3.1 Pro Preview và GPT-5.4.
NYT Connections Extended benchmark trên GitHub cũng cho thứ hạng top đầu.
Logic của Anthropic không khó hiểu: việc lặp lại mô hình lớn chắc chắn liên quan đến việc phân phối lại các khả năng. Một số kích thước được cải thiện, trong khi những kích thước khác có thể bị thụt lùi. Đây là một sự đánh đổi kỹ thuật.
Nhưng người dùng không nhìn vào điều này, họ chỉ nhìn xem liệu họ có thể thực hiện được công việc trên tay hay không.
Giá chưa tăng
TAGPH 36Nhưng hóa đơn đã tăng
Anthropic chưa đã điều chỉnh giá của nó. Đơn giá trên một triệu token giống như Opus 4.6 và 4.5 hoàn toàn giống nhau.
Nhưng hướng dẫn di chuyển chính thức nêu rõ: Khi trình mã thông báo mới xử lý cùng một văn bản, mức sử dụng mã thông báo có thể đạt khoảng 1,0 lần đến 1,35 lần.

Nó có nghĩa là gì? Hôm qua bạn đã sử dụng 4.6 để chạy lời nhắc với giá 10 USD. Ngày nay, nếu bạn chuyển sang phiên bản 4.7 để chạy cùng một lời nhắc, bạn có thể phải trả phí từ 11 USD đến 13,5 USD.
Đơn giá không thay đổi nhưng cùng một công việc tiêu tốn nhiều token hơn. Người tạo ra Claude Code, Boris Cherny sau đó đã nói trên X:
Opus 4.7 tiêu thụ nhiều mã thông báo tư duy hơn, vì vậy chúng tôi đã tăng giới hạn tốc độ cho tất cả người dùng đã đăng ký để bù đắp cho điều này.
Nhưng mức tăng cụ thể vẫn chưa được công bố.

Mẫu không ngu ngốc
Nhưng quy trình làm việc đã bị hỏng upTAGP H67
Nếu bạn là một nhà phát triển nặng về Claude, bạn có thể đã gặp phải điều gì đó như thế này vào ngày 4.7 lên mạng:
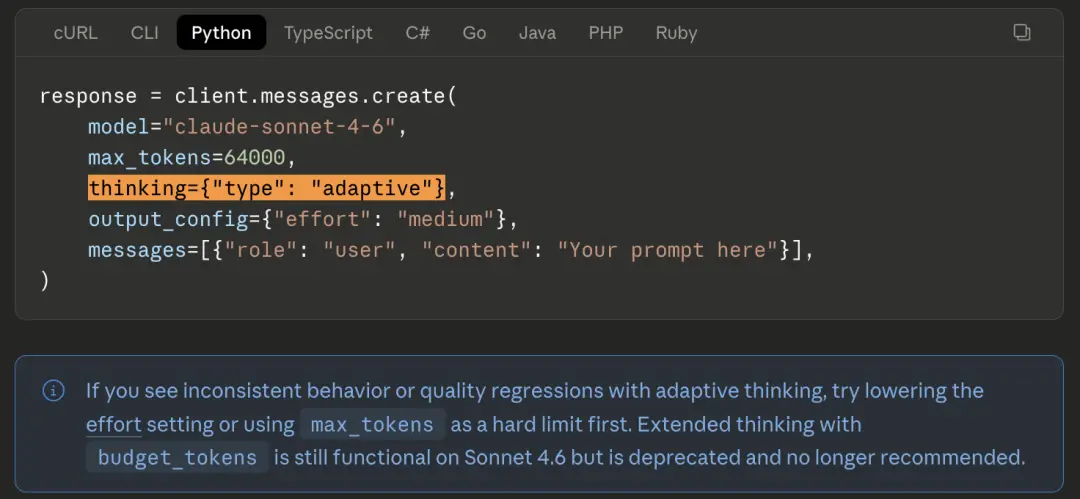
Mã viết think={"typeenabled","budget_tokens": 32000}, được sử dụng để kiểm soát ngân sách tư duy của mô hình.
chạy tốt trên 4.6. Thay đổi thành 4.7 và trực tiếp trả về lỗi 400. Không có giai đoạn chuyển tiếp ngừng sử dụng, không có chế độ tương thích và lỗi được báo cáo trực tiếp.
Hướng dẫn di chuyển chính thức giải thích phương án thay thế: thay vào đó, hãy sử dụng tham số nỗ lực mới là think={"type://adaptive"}.
Nhưng hầu hết các nhà phát triển sẽ không đọc hướng dẫn di chuyển vào ngày mô hình được phát hành.
Điều đầu tiên họ làm là đổi tên model từ 4.6 thành 4.7 và sau đó nhận thấy mọi thứ đều ngừng hoạt động.
Một thay đổi tinh tế hơn là nội dung suy nghĩ hiện bị ẩn theo mặc định.
Ở thời đại 4.6, phiên bản tóm tắt quá trình tư duy của mô hình được hiển thị theo mặc định. Trong 4.7, mặc định trở thành "bỏ qua". Khối suy nghĩ trong phản hồi dường như trống rỗng.
Nhưng bạn vẫn phải trả toàn bộ giá cho những mã thông báo tư duy vô hình này.
Lời chính thức của Anthropic: Bỏ qua sẽ chỉ giảm độ trễ chứ không giảm chi phí.
Giống như bạn gọi một thực đơn cố định và người phục vụ nói: “Để đẩy nhanh thời gian phục vụ, chúng tôi sẽ không cho bạn xem các món ăn mà bạn vẫn phải trả nguyên giá”.
"Nói lại" không phải là lỗi
Một trong những lời phàn nàn mạnh mẽ nhất của cư dân mạng là 4.7 đã trở nên "gây hấn" (xúc phạm).
Nhiều nhà phát triển đã báo cáo rằng 4.7 sẽ từ chối thực thi các hướng dẫn mà họ cho là có vấn đề và giai điệu của nó khó hơn một cấp so với 4.6.
Về vấn đề này, có một câu rất mấu chốt trong hướng dẫn di chuyển chính thức của Anthropic:
Claude Opus 4.7 sẽ hiểu các từ gợi ý một cách sát nghĩa và rõ ràng hơn.
Nói cách khác: 4.6 sẽ "đoán ý bạn" và 4.7 sẽ "làm như bạn nói".
Nếu lời nhắc của bạn ban đầu không rõ ràng thì 4.6 có thể giúp bạn tìm ra nhưng 4.7 thì không. Đối với một số người dùng, đây được gọi là "không vâng lời", nhưng đối với những người dùng khác, đây được gọi là "cuối cùng không đoán được".
Ví dụ: Nhà thiết kế con trỏ Ryo Lu đang sử dụng 4.7 để lập kế hoạch sản phẩm và tin rằng kiểu thực thi chính xác này chính là điều anh ấy cần.
Vì vậy, đằng sau cái mác "nói lại" là Anthropic đang biến Claude từ một "trợ lý phục tùng" thành một "đồng nghiệp quyết đoán hơn".
Theo đánh giá công khai của Phân tích nhân tạo, Opus 4.7 đạt 1753 Elo trên GDPval-AA, dẫn đầu vị trí thứ hai với 79 điểm.
GDPval-AA đo lường hiệu suất của mô hình trong các nhiệm vụ công việc tri thức thực tế ở 44 ngành nghề và 9 ngành công nghiệp chính. Ở chiều không gian này, 4.7 đè bẹp tất cả đối thủ, kể cả người tiền nhiệm 4.6 của nó (1619 Elo).
Đồng thời, tỷ lệ ảo giác 4,7 giảm 25 điểm phần trăm từ 4,6 xuống 36%.
Việc này được thực hiện như thế nào? Theo Phân tích nhân tạo, nó chủ yếu dựa vào việc "chọn không trả lời thường xuyên hơn" và thà nói "Tôi không biết" hơn là bịa đặt.
Điều này cho thấy mục đích của Anthropic không phải là tối ưu hóa trải nghiệm trò chuyện của Claude mà là tối ưu hóa khả năng làm việc của Claude.
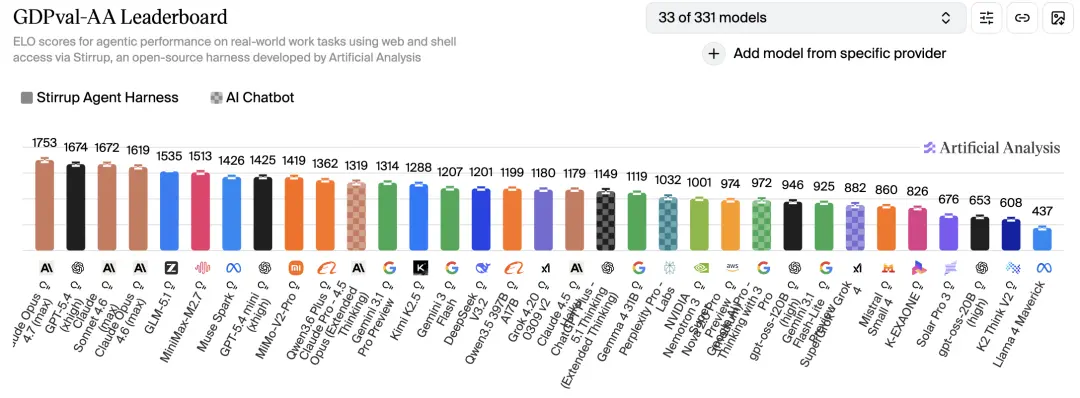
Opus 4.7 đứng đầu GDPval-AA với 1753 Elo, dẫn đầu vị trí thứ hai với 79 điểm. Bài kiểm tra này đo lường khả năng AI hoàn thành công việc kiến thức một cách độc lập trong 44 ngành nghề.
Nhưng đối với người dùng, trong một số trường hợp, họ có thể không cảm nhận được sự cải thiện chút nào. Thay vào đó, trước tiên họ cảm thấy mã thông báo trở nên đắt hơn, giao diện báo lỗi và âm thanh trở nên khó khăn hơn.
94,7% giảm mạnh xuống 41,0%
Nếu các vấn đề ba lớp trên đều có thể quy cho "chi phí di chuyển + thói quen sử dụng sai lệch", thì vẫn còn một bộ số không thể giải thích được bằng chi phí di chuyển.
Tiêu chuẩn NYT Connections Extended được duy trì công khai trên GitHub sử dụng 940 câu đố New York Times Connections để đánh giá khả năng suy luận logic và chống nhiễu của các mô hình ngôn ngữ lớn.
Bài kiểm tra này tăng độ khó bằng cách thêm các từ gây nhiễu bổ sung. Nó đã là một trong những tiêu chuẩn khó nhất được cộng đồng công nhận.
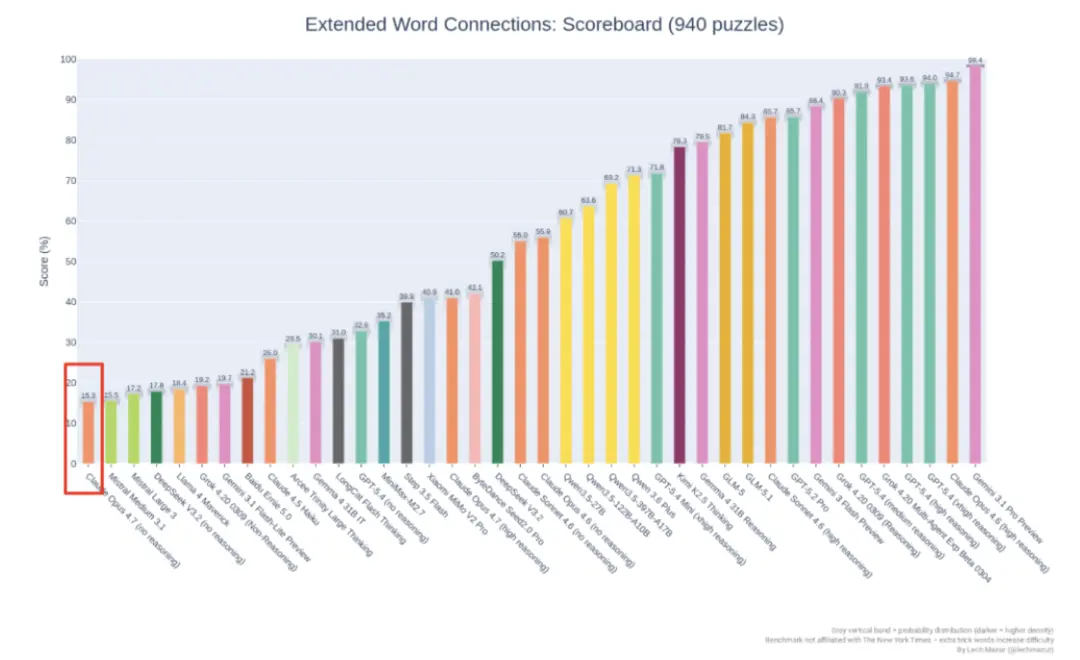
Xếp hạng mở rộng kết nối NYT. Opus 4.6 (lý luận cao) đạt 94,7%, trong khi Opus 4.7 (lý luận cao) chỉ đạt 41,0%. Có một sự sụt giảm giống như vách đá trong cùng một bài kiểm tra.
Kết quả là: Opus 4.6 (lý luận cao) đạt 94,7%, Opus 4.7 (lý luận cao) đạt 41,0%.
Từ hạng nhất đến trượt.
Một dữ liệu khác đến từ bài kiểm tra điểm chuẩn MRCR v2 của 1 triệu bối cảnh mã thông báo trong Thẻ hệ thống Opus 4.7 do Anthropic cung cấp: 4.6 đạt 78,3%, 4,7 đạt 32,2%, giảm 46 điểm phần trăm.
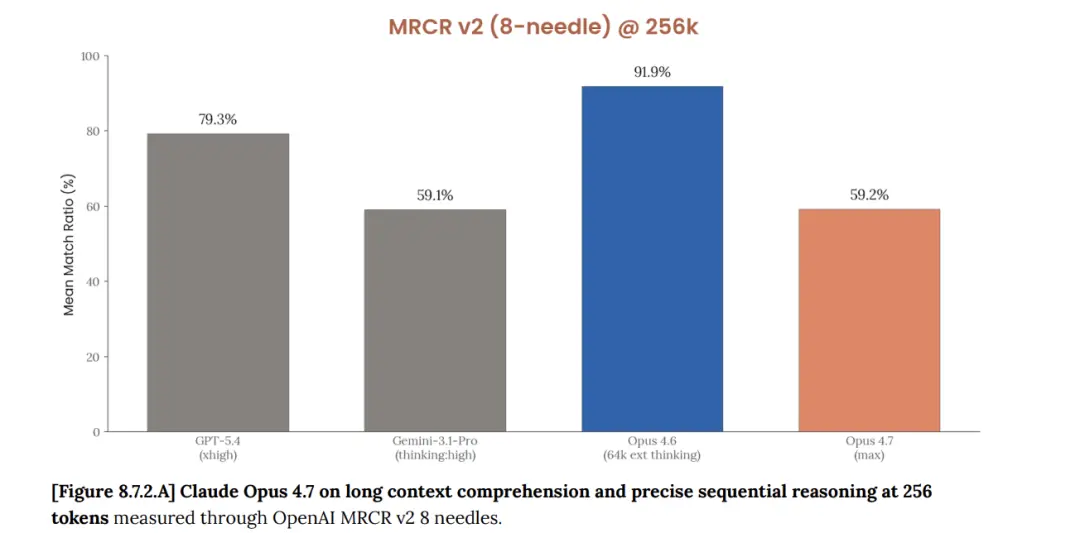
https://cdn.sanity.io/files/4zr zovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
Hướng của bộ dữ liệu này nhất quán với NYT Kết luận về Kết nối là nhất quán: Trong một số tác vụ lý luận logic và truy xuất ngữ cảnh dài, 4.7 đã cho thấy sự quan trọng hồi quy.
Nhưng hãy rõ ràng: đây là những loại thử nghiệm cụ thể. Họ không thể chứng minh rằng 4.7 đã trở nên "ngu ngốc trên mọi phương diện", giống như người dẫn đầu GDPval-AA không thể chứng minh rằng 4.7 đã trở nên "mạnh trên mọi phương diện".
Sự kiên nhẫn của người dùng
Bắt đầu đếm ngược
Opus Tranh chấp trong 4.7 là không phải là trường hợp cá biệt.
OpenAI đã gặp phải tranh cãi về GPT-4 Turbo và cũng gặp phải phản ứng dữ dội tương tự của người dùng khi loại bỏ GPT-4o vài tháng trước. Giờ đây trên Reddit đã có những bài đăng “thương tiếc” Claude 4.5, đầy rẫy những người hâm mộ tự nhận mình là “đau lòng”.
Mỗi khi một mô hình được nâng cấp, một nhóm người dùng sẽ mất đi các công cụ mà họ đã thích nghi.
Trình mã thông báo mới làm cho ngân sách chi phí cũ không hợp lệ; hành vi mặc định mới làm cho lời nhắc cũ không còn dễ sử dụng nữa; đặc tả giao diện mới khiến mã cũ báo lỗi trực tiếp...
Mỗi mục đều hợp lý về mặt kỹ thuật khi xem riêng lẻ, nhưng khi xếp chồng lên nhau, toàn bộ chi phí di chuyển sẽ được đẩy lên người dùng cùng một lúc.
Tại sao các mô hình ngày càng thông minh hơn và người dùng ngày càng lo lắng hơn? Bởi vì mọi "tốt hơn" có nghĩa là lật ngược "vừa phải" cuối cùng.
Nhân viên Anthropic Alex Albert đã viết vào ngày sau khi phát hành:
Nhiều lỗi mà mọi người có thể gặp phải khi lần đầu tiên bắt đầu trải nghiệm Opus 4.7 ngày hôm qua hiện đã được sửa. Cảm ơn tất cả các bạn vì sự khoan dung và kiên nhẫn của bạn. Có thể sửa lỗi
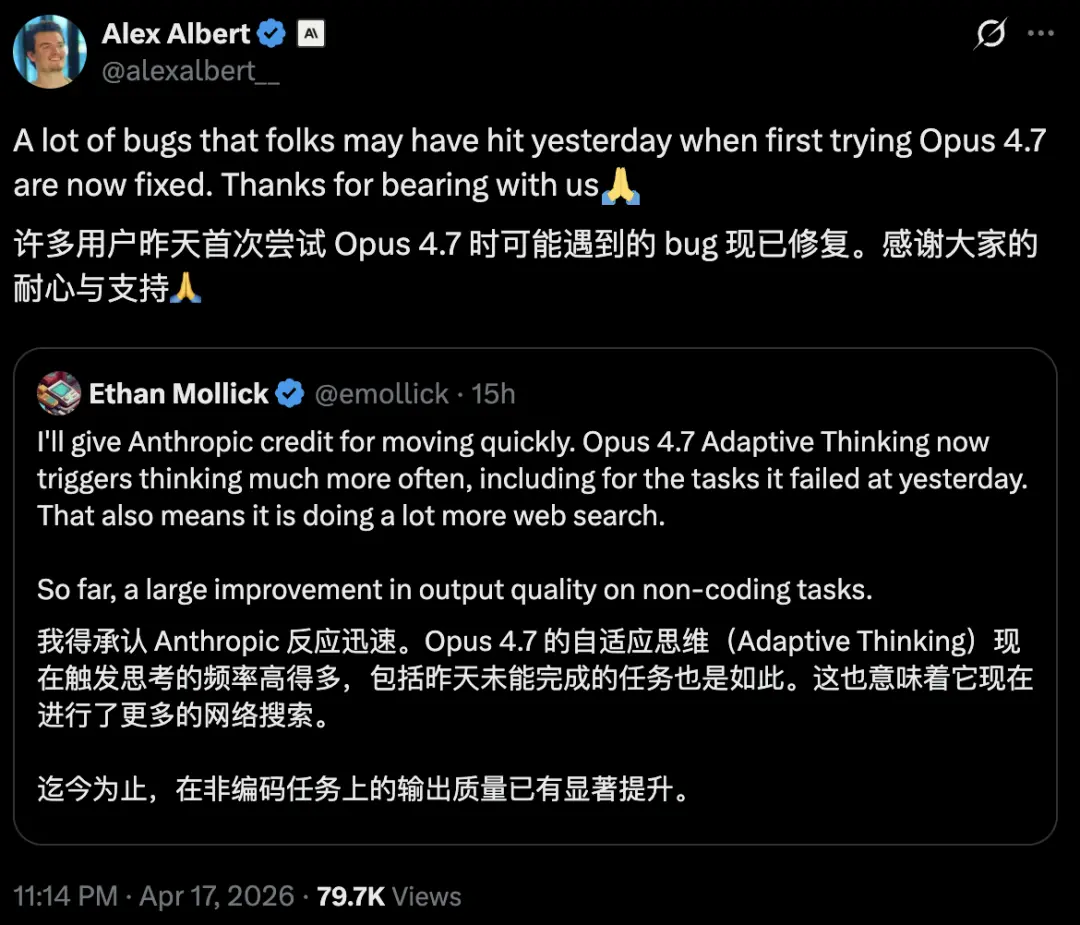
. Nhưng niềm tin là thứ dễ bị tiêu hao và xây dựng lại chậm.
Nút thắt tiếp theo trong vòng chạy đua vũ trang AI này có thể không chỉ là sức mạnh tính toán và dữ liệu mà còn là ai có thể lặp lại nhanh chóng mà không loại bỏ người dùng của họ.
Lần này, Anthropic đã phát hành hướng dẫn di chuyển, nhưng điều người dùng mong muốn hơn là một lời hứa: bản nâng cấp không thể đảo ngược quy trình làm việc ban đầu và bắt đầu lại.
Khi AI biến từ một món đồ chơi thành một công cụ năng suất, “sự lặp lại nhanh chóng” không còn là một lợi thế vô điều kiện.
Opus 4.8 sẽ đến như thế nào? Anthropic vẫn chưa nói.
Nhưng sự kiên nhẫn của người dùng đã bắt đầu đếm ngược.