Nhà nghiên cứu đa phương thức DeepSeek Chen Xiaokang đã đăng một tweet trên X đêm qua và công bố bài báo mới của DeepSeek về công nghệ đa phương thức "Suy nghĩ bằng hình ảnh nguyên thủy", có nghĩa là "Háo hức phát hành".

Sáng nay, dòng tweet đã bị xóa và bài viết trên GitHub cũng bị rút lại.

Nhưng APPSO đã đọc toàn bộ trước khi nó biến mất. Sau khi đọc, tôi cảm thấy bài viết này bị rút lại có thể không phải do vấn đề nội dung.
Ngược lại, có lẽ nó sẽ tiết lộ quá nhiều.
Chúng tôi vừa thử nghiệm xong chế độ nhận dạng hình ảnh của DeepSeek vào ngày hôm kia và yêu cầu nó đếm trên đầu ngón tay. Nó suy nghĩ một lúc rồi tự phàn nàn: “Mình thực sự choáng váng khi đếm,” và rồi trả lời sai. Lúc đó tôi tưởng đó là một vấn đề nhỏ trong giai đoạn grey testing.
Bài viết này cho chúng ta biết rằng có một nút thắt kỹ thuật mà GPT, Claude và Gemini cùng nhau giải quyết chưa tốt.
Giải pháp mà DeepSeek đưa ra gần như đơn giản đến mức nực cười: đặt ngón tay lên AI.
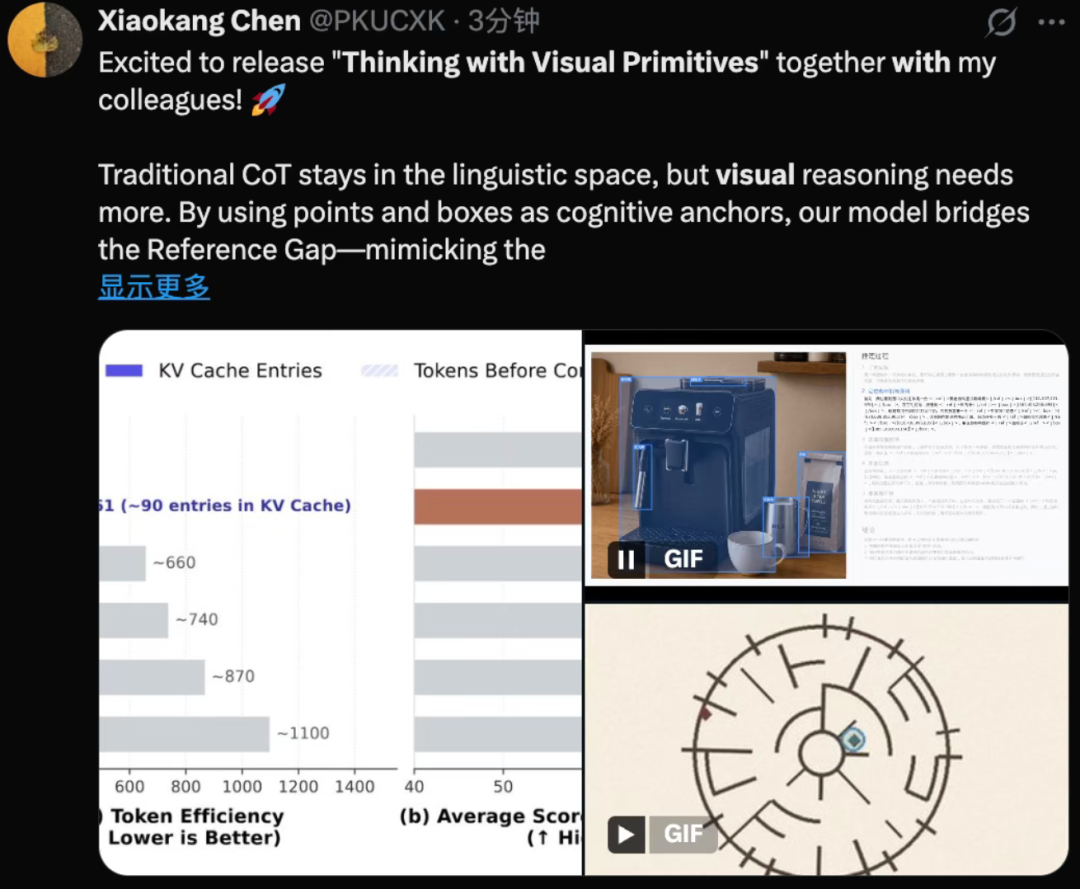
Chan Xiaokang đã viết trong tweet đó:
“CoT truyền thống vẫn nằm trong không gian ngôn ngữ, nhưng cần nhiều hơn thế. Bằng cách sử dụng điểm và hộp suy luận trực quan làm nhận thức neo, mô hình của chúng tôi thu hẹp Khoảng cách tham chiếu—bắt chước sức mạnh tổng hợp "từ điểm đến lý do" mà con người sử dụng."
"Chuỗi tư duy truyền thống vẫn tồn tại trong không gian ngôn ngữ, nhưng lý luận trực quan đòi hỏi nhiều hơn thế 》
Nhìn rõ ràng và chỉ ra chính xác là hai điều khác nhau. things
Hiện tại, tất cả các mô hình lớn đa phương thức đều thực hiện suy luận hình ảnh. Bản chất là chuyển đổi những hình ảnh bạn nhìn thấy thành văn bản, sau đó thực hiện suy luận chuỗi suy nghĩ trong không gian văn bản.
Trong hai năm qua, hướng cải tiến của OpenAI, Google và Anthropic đã tập trung vào một vấn đề: làm thế nào để mô hình nhìn rõ hơn.
Bạn có thể hiểu như sau: Trong một bức ảnh, 25 người đang đứng dày đặc với nhau. Nếu bạn dùng từ ngữ để mô tả "người bên cạnh người mặc áo xanh ở hàng thứ ba bên trái", bản thân mô tả sẽ rất mơ hồ khi đếm.
Con người giải quyết vấn đề này như thế nào? Nó đủ nguyên thủy: đưa các ngón tay của bạn ra và đếm từng ngón một.
Giải pháp của DeepSeek: để mô hình xuất trực tiếp tọa độ trên ảnh trong quá trình suy nghĩ.
Hãy tưởng tượng rằng mô hình nhìn thấy rất nhiều người trong một bức ảnh. người này" rồi gắn tọa độ của một ô để khoanh tròn những người. Hãy khoanh tròn một ô cho mỗi người bạn đếm và chỉ đếm số ô sau khi đã khoanh tròn.
Có hai định dạng tọa độ: một là hộp giới hạn, vẽ một hình chữ nhật để bao quanh đối tượng và phù hợp để hiệu chỉnh vị trí của đối tượng; cái còn lại là điểm, chỉ ra một vị trí trên bản đồ và phù hợp để theo dõi đường đi và mê cung đi bộ. DeepSeek gọi hai thứ này là "nguyên thủy trực quan", đơn vị tư duy nhỏ nhất.
Đây là thay đổi quan trọng: Trong đó trước đây tọa độ đầu ra của mô hình là câu trả lời cuối cùng (“mục tiêu ở đây”) thì bây giờ tọa độ được nhúng vào chính quá trình suy nghĩ. Tọa độ là điểm đánh dấu trên tờ giấy nháp, không phải đáp án trên phiếu trả lời.
Nén một hình ảnh 7056 lần và sau đó có thể đếm rõ ràng có bao nhiêu người trong đó
Cơ sở mô hình là DeepSeek-V4-Flash, mô hình MoE tham số 284B. MoE có nghĩa là: mô hình có bộ não lớn nhưng chỉ một phần nhỏ tế bào thần kinh được sử dụng để hoạt động mỗi khi trả lời một câu hỏi và chỉ có tham số 13B được kích hoạt trong quá trình suy luận. Tương tự như một đội 100 người, mỗi nhiệm vụ chỉ có 5 người được cử đi.
Bộ mã hóa hình ảnh có ba mức nén. Hãy sử dụng một phép tương tự: bạn có một bức ảnh muốn gửi cho bạn bè và tốc độ Internet rất chậm. Bước đầu tiên, bạn cắt ảnh thành những hình vuông nhỏ để sử dụng sau này; ở bước thứ hai, cứ 9 ô vuông nhỏ được ghép lại thành 1 (nén 3×3); ở bước thứ ba, thông tin dư thừa được sắp xếp hợp lý hơn trong quá trình truyền (nén KV Cache 4 lần).
Số thực: Hình ảnh 756×756, 570.000 pixel, được ép hết cỡ xuống 81 đơn vị thông tin. Tỉ số nén 7.056x.
Phản ứng đầu tiên của tôi khi nhìn thấy con số này là: Tôi vẫn có thể nhìn rõ chứ? Nhưng kết quả trong bài báo cho thấy điều đó thực sự có thể. Tôi không chỉ có thể nhìn rõ mà còn có thể đếm chính xác 25 người trong ảnh.
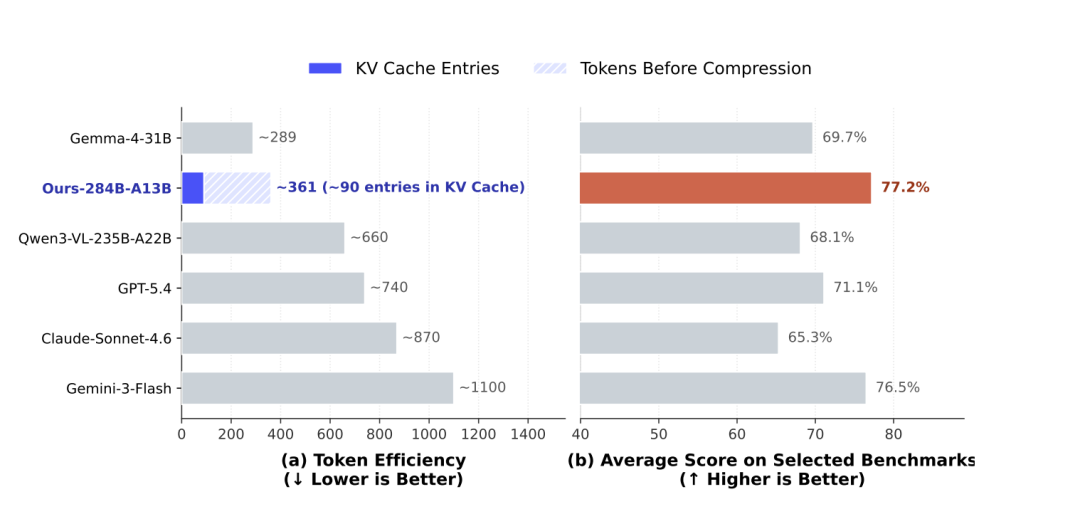
Để so sánh: đối với cùng một hình ảnh 800×800, Gemini-3-Flash tiêu thụ khoảng 1100 mã thông báo. Để thể hiện biểu đồ này, Claude-Sonnet-4.6 có khoảng 870 và GPT-5.4 có khoảng 740. DeepSeek chỉ sử dụng 90 đơn vị thông tin trong phép tính cuối cùng. Những người khác sử dụng hơn một nghìn lưới để ghi nhớ một bức ảnh, nhưng DeepSeek chỉ sử dụng 90 lưới, sau đó sử dụng toàn bộ sức mạnh tính toán được giải phóng đến "ngón tay".
Cách lưu 40 triệu mẩu dữ liệu đào tạo
DeepSeek đã thu thập dữ liệu tất cả các tập dữ liệu có nhãn "phát hiện mục tiêu" từ các nền tảng như Huggingface và bước đầu sàng lọc 97.984 nguồn dữ liệu.
Sau đó chúng tôi thực hiện hai vòng sàng lọc.
Lần kiểm tra chất lượng nhãn đầu tiên. Sử dụng AI để tự động xem xét ba loại câu hỏi: nhãn là những số vô nghĩa (danh mục có tên "0" và "1"), nhãn là các thực thể riêng tư ("MyRoommate") và nhãn là những chữ viết tắt mơ hồ ("OK" và "NG" trong thử nghiệm công nghiệp, một quả táo "OK" và một bảng mạch "OK" trông hoàn toàn khác nhau và AI không thể học được chúng). Vòng này chứng kiến mức cắt giảm 56%, còn lại 43.141.
Chất lượng của đợt kiểm tra khung thứ hai. Ba tiêu chí: Thiếu quá nhiều dấu (đánh dấu một nửa dấu sẽ không được đánh dấu), khung bị cong và một nửa đối tượng bị cắt, và khung quá lớn đến mức đóng khung toàn bộ hình ảnh (có nghĩa là dữ liệu gốc là dữ liệu phát hiện được chuyển đổi cứng từ phân loại hình ảnh, không có thông tin định vị). Cắt thêm 27%, còn lại 31.701.
Cuối cùng, việc lấy mẫu và loại bỏ trùng lặp được thực hiện theo danh mục, tạo ra hơn 40 triệu mẫu chất lượng cao.
DeepSeek Chọn phóng to dữ liệu khung trước và thêm dữ liệu điểm sau. Lý do cũng đơn giản: nếu bạn yêu cầu AI đánh dấu vào một ô thì câu trả lời về cơ bản là duy nhất (chỉ cần khoanh tròn đối tượng); nhưng nếu bạn yêu cầu AI đánh dấu một điểm, mọi vị trí trên đối tượng sẽ được coi là chính xác, không có câu trả lời đúng duy nhất và tín hiệu huấn luyện quá mờ. Hơn nữa, bản thân khung chứa hai điểm (góc trên bên trái và góc dưới bên phải). Sau khi học cách vẽ khung, dấu câu là một thao tác giảm kích thước.
Cách dạy khả năng "ngón tay" cho người mẫu
Chiến lược sau đào tạo là "đào tạo riêng trước, sau đó hợp nhất".
DeepSeek trước tiên sử dụng dữ liệu khung để đào tạo mô hình chuyên gia chuyên về khung ảnh, sau đó sử dụng một số dữ liệu để đào tạo mô hình chuyên gia chuyên về dấu câu. Sở dĩ phải huấn luyện riêng biệt là vì lượng dữ liệu không đủ lớn, hai năng lực này rất dễ gây nhiễu lẫn nhau khi trộn lẫn với nhau.
Sau đó thực hiện học tăng cường tương ứng trên hai chuyên gia. Làm thế nào để đánh giá mô hình “vẽ đúng khung” hay “đi đúng đường”? DeepSeek đã thiết kế một hệ thống tính điểm đa chiều: định dạng có đúng không (cú pháp tọa độ có đúng không), tính logic không hợp lý (quá trình suy nghĩ có mâu thuẫn không) và câu trả lời có chính xác không (kết quả cuối cùng khác với câu trả lời tiêu chuẩn như thế nào).
Việc sàng lọc dữ liệu của học tăng cường cũng rất đặc biệt: đầu tiên hãy để mô hình thực hiện cùng một câu hỏi N lần. Những câu hỏi đúng đều quá dễ và không có giá trị đào tạo, còn những câu hỏi sai thì quá khó để học được gì. Chỉ còn lại những câu hỏi “một số đúng và một số sai” để thực hành.
Bước cuối cùng là kết hợp khả năng của hai chuyên gia vào một mô hình. Cách tiếp cận cụ thể: Cho mô hình thống nhất học theo đầu ra của hai chuyên gia, tương tự như một học sinh học các môn học khác nhau từ hai giáo viên cùng một lúc.
Sau khi đưa ngón tay thì tính như thế nào
Đếm 25 Cá nhân

Đưa cho người mẫu Nhập ảnh của một đội bóng đá và hỏi "Có bao nhiêu người trong ảnh?"
Quá trình suy nghĩ: Đầu tiên hãy xác định "Đây là ảnh của đội, đếm tất cả mọi người, kể cả các cầu thủ và huấn luyện viên." Sau đó xuất ra 25 tọa độ khung hình cùng một lúc và khoanh tròn một khung hình trên mỗi người. Sau đó đếm theo số hàng: 4 người ngồi hàng trước + 9 người ngồi hàng giữa + 8 người hàng sau + 2 huấn luyện viên bên trái + 2 huấn luyện viên bên phải = 25.
“Có bao nhiêu con gấu ở hàng ghế đầu? mặt đất?”

Có ba con gấu trong hình. Mô hình đưa ra từng khung hình một và xác định vị trí của nó: khung đầu tiên leo thẳng đứng trên thân cây và loại trừ nó; người thứ hai đi trên mép tảng đá và đếm; cái thứ ba trong số gỗ và đất vỡ, đếm. Trả lời: 2.
Thay vì đếm ba rồi trừ đi một, mỗi phán đoán được đánh giá là "có ở trên mặt đất hay không" và có một neo tọa độ cụ thể đằng sau mỗi phán đoán. Thực sự là đang kiểm tra từng thứ một chứ không phải đoán mò.
Suy luận không gian nhiều bước nhảy

A 3D Có rất nhiều hình học màu trong cảnh được kết xuất. Câu hỏi: Có vật cao su màu tím nào to bằng vật kim loại màu xám không?
Đầu tiên, mô hình sẽ đóng khung quả cầu kim loại màu xám để xác nhận rằng đó là một vật thể nhỏ. Sau đó đóng khung lần lượt các vật thể nhỏ khác trong khung cảnh: hình trụ kim loại màu nâu, hình vuông kim loại màu xanh lam, hình vuông cao su màu xanh lam, hình trụ cao su màu vàng... Sáu vật thể được kiểm tra từng cái một và ba thuộc tính về màu sắc, chất liệu và kích thước được kiểm tra từng cái một. Kết luận: Không có thứ gọi là cao su màu tím.
Sáu lần định vị và sáu lần phán đoán. Mỗi bước đều được neo theo tọa độ nên sẽ không có câu "chờ một chút, bạn tìm thấy nó ở đâu?" tình huống.
Thêm tài liệu tham khảo về trường hợp trong bài báo:

Điều hướng mê cung: Ai đó tung đồng xu, DeepSeek Thực sự đang tìm kiếm
Bài báo đã thử nghiệm bốn nhiệm vụ và mê cung là mê cung có khoảng cách rộng nhất.
Nhiệm vụ rất đơn giản: đưa ra một bản đồ mê cung, hỏi xem có đường đi nào từ điểm bắt đầu đến điểm cuối không và nếu có thì hãy vẽ đường đi đó. Có ba hình dạng mê cung: hình vuông, hình tròn và hình tổ ong.
Cách mô hình di chuyển trong mê cung cũng giống như khi bạn dùng bút chì để vẽ trên giấy khi còn nhỏ: chọn một con đường nhánh và đi đến cuối. Nếu nó không hoạt động, hãy quay lại và thử cái khác. Điểm khác biệt là mỗi bước thực hiện đều đánh dấu một điểm tọa độ trên bản đồ và để lại bản ghi.
Bài viết trình bày toàn bộ quá trình của một mê cung hình tròn: đầu tiên mô hình đánh dấu điểm bắt đầu và điểm kết thúc, sau đó bắt đầu khám phá. Sau khi đi được 18 bước, tôi vào ngõ cụt hai lần rồi thoát ra. Cuối cùng, tôi đã tìm thấy một đường dẫn và kết nối các điểm tọa độ của toàn bộ đường dẫn đó với đầu ra.
DeepSeek cũng thiết kế một loạt mê cung bẫy: thoạt nhìn thì có một con đường, nhưng một đoạn nào đó ở giữa đã bị bí mật chặn lại. Loại mê cung này thử thách sự kiên nhẫn. Mô hình không thể đưa ra kết luận chỉ bằng cách nhìn vào xu hướng gần điểm bắt đầu. Nó phải thử tất cả các đường dẫn có thể để xác nhận rằng nó không hoạt động.
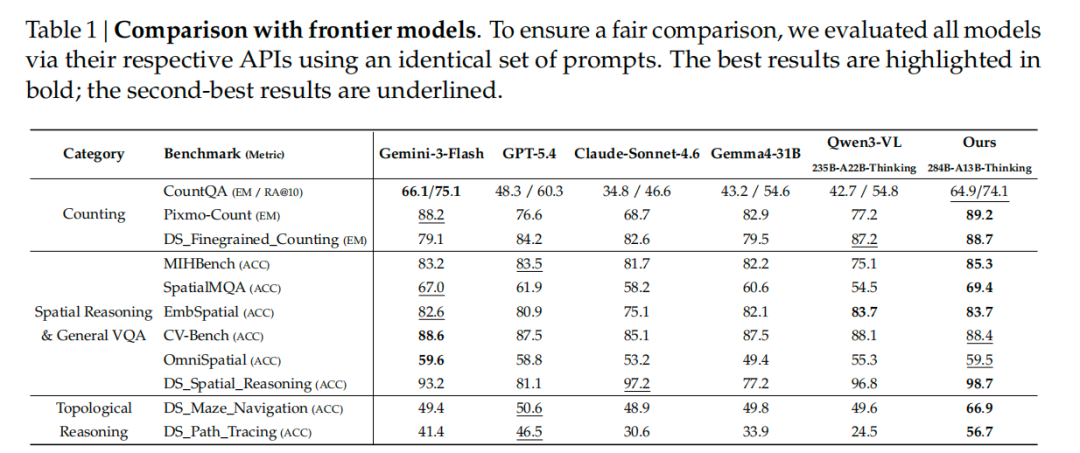
So sánh độ chính xác:
- DeepSeek: 66,9%
- GPT-5.4: 50,6%
- Claude-Sonnet-4.6: 48,9%
- Gemini-3-Flash: 49,4%
- Qwen3-VL: 49,6%
Mê cung chỉ có hai câu trả lời: có đường đi, hoặc không có đường đi. Tỉ lệ đoán ngẫu nhiên chính xác là 50%. GPT, Claude, Gemini và Qwen đều dao động quanh mức 50%, không khác gì việc tung đồng xu. Tỷ lệ 66,9% của DeepSeek không cao nhưng thực sự đây là cách tiếp cận từng bước chứ không phải là việc làm ngu ngốc.
Theo dõi đường dẫn: Phiên bản cuối cùng của Tìm sự khác biệt
Nhiệm vụ này trực quan hơn: một loạt các chuỗi đan xen với nhau, mỗi chuỗi dẫn từ điểm đánh dấu này sang điểm đánh dấu khác. Dây tai nghe của bạn trông như thế nào khi bạn lấy nó ra khỏi túi sẽ trông như thế nào trong hình. Câu hỏi hỏi bạn: Đường này dẫn đến điểm cuối nào? Mô hình
dùng để xuất ra các điểm tọa độ dọc theo đường thẳng, giống như ngón tay lướt qua tờ giấy. Nơi đường cong sắc nét, các điểm được đánh dấu dày đặc và các đoạn thẳng được đánh dấu thưa thớt. Điều này cũng đúng khi mọi người nhìn theo một đường thẳng. Họ giảm tốc độ ở những khúc cua và lướt qua những đường thẳng.
Bài viết còn bổ sung thêm một phiên bản thử nghiệm khó: tất cả các đường kẻ đều có cùng màu sắc và độ dày. Bạn không còn có thể phân biệt đó là đường nào bằng màu sắc, bạn chỉ có thể dựa vào tính liên tục của xu hướng của chính đường cong để xác định giao điểm sẽ đi theo đường nào.
- DeepSeek: 56,7%
- GPT-5.4: 46,5%
- Claude-Sonnet-4.6: 30,6%
- Gemini-3-Flash: 41,4%
30,6% của Claude là hơi bất ngờ. Nhìn chung có bốn hoặc năm lựa chọn cho điểm cuối và khả năng đoán ngẫu nhiên phải lớn hơn 20% và 30,6% chỉ tốt hơn một chút so với đoán mù. Có lẽ quán tính của lý luận bằng lời nói không hữu ích trong loại nhiệm vụ theo dõi không gian thuần túy này.
Cách dạy AI Đi qua mê cung mà không gian lận
Có một vấn đề thực tế trong việc huấn luyện mê cung: nếu bạn chỉ cho điểm dựa trên câu trả lời cuối cùng có đúng hay không thì mô hình sẽ học nhanh. Thay vì cố gắng tìm kiếm và có thể nhận được câu trả lời sai, tốt hơn hết bạn chỉ nên đoán một câu. Dù sao đi nữa, nếu bạn đi cẩn thận và trả lời sai, điểm sẽ bằng 0.
Giải pháp của DeepSeek là đưa quy trình vào điểm số. Điểm được thưởng cho mỗi bước khám phá pháp luật, điểm bị trừ khi đi xuyên tường và bạn càng đi xa thì càng tốt. Ngay cả khi cuối cùng bạn không về đích, chỉ cần bạn tìm kiếm cẩn thận hầu hết các khu vực, bạn vẫn có thể nhận được kết quả tốt. Bằng cách này, người mẫu không có động cơ để lười biếng.
Mê cung không thể giải được có yêu cầu cao hơn: bạn không thể chỉ nói “nó không hoạt động”, bạn còn phải chứng minh rằng bạn thực sự đã ghé thăm tất cả những nơi bạn có thể đến. Phạm vi tìm kiếm cũng được tính.
Một quả trứng Phục sinh, ba giới hạn
Không có tiếng Trung Quốc trong dữ liệu sau đào tạo. Nhưng mô hình này có thể thực hiện lý luận nguyên thủy bằng hình ảnh bằng tiếng Trung.
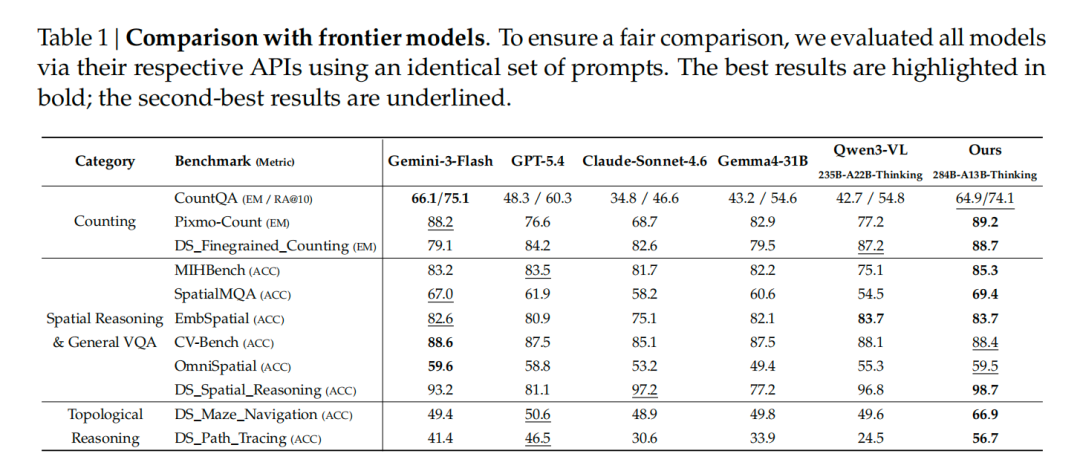
Cho nó một bức ảnh về máy pha cà phê và hỏi "Cách pha cà phê latte" bằng tiếng Trung. Nó đánh dấu tọa độ vị trí của vòi hơi, bình sữa, hạt cà phê và nút latte bằng tiếng Trung, sau đó đưa ra các bước vận hành. Khả năng đa ngôn ngữ được kế thừa từ mô hình cơ sở và không bị phá hủy khi đào tạo về hình ảnh nguyên thủy.
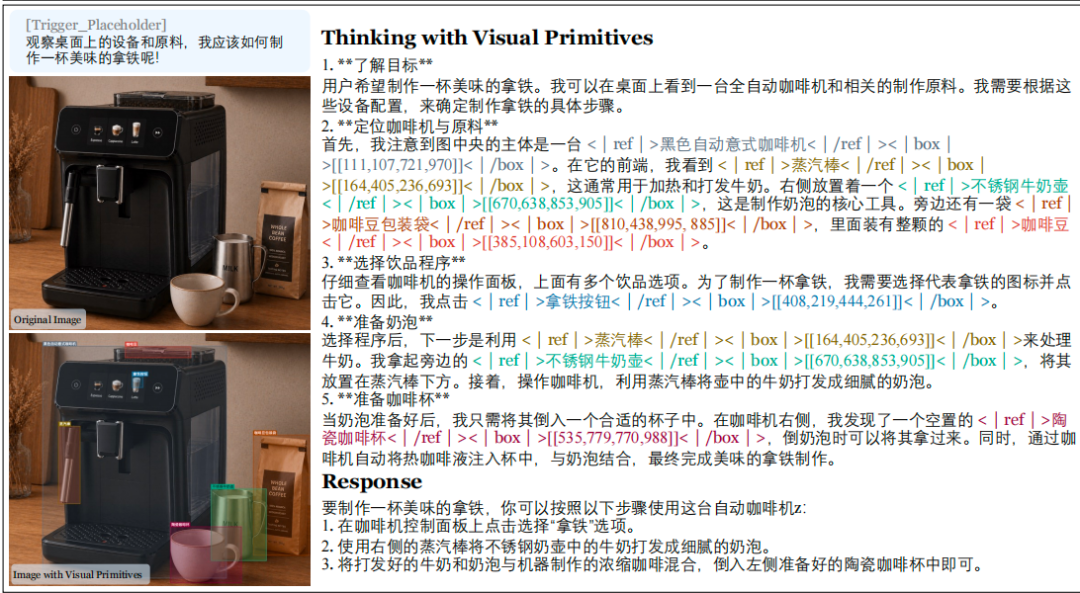
Nó cũng có thể kết hợp việc xem hình ảnh với kiến thức thế giới: đưa ra một bức ảnh về Cầu Cổng Vàng và hỏi "Có đội NBA nào ở gần đây không?" Đầu tiên nó đóng khung Cầu Cổng Vàng, suy luận rằng đây là San Francisco, sau đó trả lời Golden State Warriors.

Có thể hiểu được sự hài hước: những đốm tự nhiên trên bề mặt cắt của một miếng trái cây tạo nên khuôn mặt của một con mèo buồn bã và người mẫu có thể chỉ ra những điểm tương đồng và giải thích lý do tại sao nó buồn cười.

Hướng dẫn thoát khỏi phòng: Đóng chìa khóa lên cao, ghế kê trên sàn, cửa có khóa. Nên "di chuyển ghế dưới chìa khóa → dẫm lên để lấy chìa khóa → mở cửa."

Bài báo thẳng thắn viết về những điều mà hiện tại là không thể.
Độ phân giải đầu vào bị hạn chế. Đầu ra ViT bị kẹt giữa 81 và 384 đơn vị thông tin hình ảnh. Khi gặp những cảnh quá chi tiết (như đếm ngón tay) thì độ chính xác tọa độ là không đủ. Đây có thể là nguyên nhân trực tiếp khiến xe bị lật khi đếm trên đầu ngón tay trong buổi chạy thử thực tế ngày hôm kia.
Hiện tại cần có một từ kích hoạt cụ thể để kích hoạt chế độ nguyên thủy trực quan. Người mẫu chưa thể tự mình phán xét “Mình nên duỗi ngón tay ra để giải quyết vấn đề này”, phải có người nhắc nhở.
Lý luận tôpô có khả năng khái quát hóa hạn chế. Hiệu ứng này tốt đối với loại mê cung đã được huấn luyện, nhưng nó có thể bị rơi ra khi chuyển sang cấu trúc không gian mới. Chen Xiaokang cũng cho biết trong dòng tweet đã bị xóa đó:
"Chúng tôi vẫn đang ở giai đoạn đầu; việc khái quát hóa trong các nhiệm vụ lý luận tôpô phức tạp vẫn chưa hoàn hảo, nhưng chúng tôi cam kết sẽ giải quyết nó."
“Chúng tôi vẫn đang ở giai đoạn đầu và việc khái quát hóa các nhiệm vụ lý luận tôpô phức tạp vẫn chưa hoàn thiện, nhưng chúng tôi sẽ tiếp tục giải quyết it.”
Trong quá trình thử nghiệm thực tế ngày hôm kia, các khả năng được thể hiện qua chế độ nhận dạng hình ảnh của DeepSeek (yêu cầu danh tính nhà xuất bản, logo cá voi Lenovo), tự sửa lỗi, tự tạo cho mình một "cuộc họp phòng thủ nhỏ"), phù hợp với lối suy nghĩ được mô tả trong bài viết này. Nó thiết lập một điểm neo trực quan trong não, đưa ra lý luận xung quanh điểm neo đó và quay lại sửa chữa nó khi gặp phải xung đột.
Và việc đếm ngón tay khiến tôi choáng váng, đây là minh chứng sống động cho Reference Gap. Trong hình ảnh các ngón tay chồng lên nhau, chỉ dựa vào mô tả bằng lời nói để phân biệt “người thứ ba từ bên trái” và “người thứ hai từ bên phải” cũng giống như việc đếm một nhóm người chen chúc nhau mà không duỗi ngón tay ra thì sẽ hỗn loạn.
Phương hướng mà bài viết này hướng tới là: bước phát triển tiếp theo của lý luận đa phương thức nằm ở cơ chế neo đậu. DeepSeek sử dụng 90 đơn vị thông tin để cân bằng hiệu quả của những đơn vị khác sử dụng hàng nghìn mã thông báo và tất cả sức mạnh tính toán tiết kiệm được sẽ được sử dụng để cho phép mô hình "suy nghĩ và chỉ ra cùng một lúc".
Cuộc chạy đua vũ trang về độ phân giải có thể bị chậm lại một chút bằng cách dạy người mẫu đưa ngón tay ra thay vì đeo một cặp kính đắt tiền hơn.
Sau khi cá voi mở mắt, nó cũng mọc ra các ngón tay. Tỷ lệ chính xác trong mê cung là 66,9% còn lâu mới hoàn hảo, nhưng ít nhất nó cũng được xem xét một cách nghiêm túc, không giống như những người hàng xóm đang tung đồng xu.