AI lập trình mạnh mẽ nhất, có thực sự thông minh? Đầu tháng 2 năm nay, Anthropic đã phát hành Claude Opus 4.6. Với logic suy luận sâu sắc và khả năng thực thi chính xác các đặc tả mã phức tạp, Anthropic được ngành công nghiệp coi là vị thần mã. Tuy nhiên, thời gian tốt đẹp không kéo dài lâu. Chỉ vài tuần sau khi phát hành, người dùng tiếp tục phàn nàn trên mạng xã hội, nói rằng hiệu suất của nó đã giảm mạnh.

Nhiều người dùng tuyên bố rằng họ đã trả mức phí hàng tháng cao tương tự, nhưng đổi lại họ nhận được một phiên bản Opus giảm nước rõ ràng đã bị giảm bớt. 4.6 bắt đầu trở nên lười biếng và hay quên, thậm chí còn liên tục va vào tường ở logic cơ bản.
Trước sự lên án của toàn mạng, đội ngũ chính thức của Anthropic đã lên tiếng phản hồi. Họ lập luận rằng mô hình này chưa bao giờ bị suy yếu và các hoạt động bất thường khác nhau chỉ là sự tối ưu hóa cấu hình mặc định được thực hiện để giúp người dùng tiết kiệm Token.
Loại biện minh kỹ thuật đơn phương này rõ ràng không thể làm dịu đi sự tức giận của các nhà phát triển.
Đây có phải là ảo tưởng tâm lý tập thể của một số lượng lớn người dùng, hay là sự co rút vốn được pha chế cẩn thận dưới nút thắt của sức mạnh tính toán?
1. Phân tích chuyên sâu của các giám đốc điều hành AMD: Nhật ký 6852 cho thấy manh mối
Nếu những phàn nàn của người dùng thông thường chỉ là về cảm giác cơ thể, thì phân tích của Stella Lorenzo (Stella) Laurenzo đã đưa vấn đề này vào tầm nhìn thực tế.
Theo thông tin LinkedIn, Lorenzo là giám đốc cấp cao bộ phận AI của AMD và hiện đang lãnh đạo một nhóm lớn tại AMD để đóng góp vào việc phát triển trình biên dịch AI nguồn mở. Cô từng là kỹ sư phần mềm chính tại Google và sau đó gia nhập AMD với tư cách là cựu phó chủ tịch kỹ thuật tại Nod.ai.
Vào ngày 2 tháng 4, Lorenzo đã công bố báo cáo truy nguyên hiệu suất chi tiết trên GitHub.
Là một chuyên gia AI hàng đầu, cô ấy không chỉ phát biểu dựa trên trực giác mà còn phân tích chi tiết 6852 tệp phiên Claude Code, 17871 khối tư duy và hơn 230.000 bản ghi cuộc gọi công cụ, có thể gọi là nghiên cứu điển hình cấp cao chi tiết.
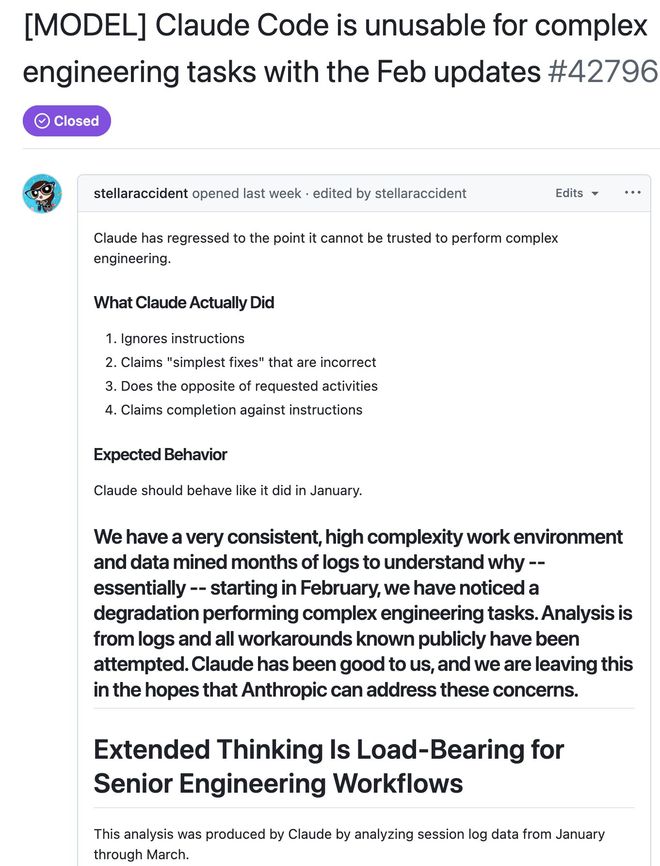
Phân tích dựa trên dữ liệu khổng lồ này đã tiết lộ một sự thật đáng lo ngại. Kể từ tháng 2 năm nay, chiều sâu lý luận của Claude đã giảm mạnh.
Thông tin chi tiết hiển thị:
Số lượng từ lý luận đã giảm: độ dài suy nghĩ trung bình đã giảm từ 2200 ký tự xuống 600 ký tự.
Nghiên cứu xuống cấp: Trước đây, Claude sẽ tiến hành nhiều vòng nghiên cứu (Nghiên cứu) trước khi viết mã, nhưng bây giờ chế độ đã thay đổi thành sửa đổi trực tiếp (Chỉnh sửa), điều này khiến tỷ lệ đọc và chỉnh sửa giảm từ 6,6 lần xuống 2,0 lần.
Khởi hành nhiệm vụ sớm: Chỉ trong 17 ngày, Claude đã cố gắng từ bỏ nhiệm vụ hoặc hỏi tôi liệu tôi có nên tiếp tục 173 lần hay không, trong khi trước ngày 8 tháng 3, con số này là 0.
Mâu thuẫn: Tần suất phủ nhận bản thân trong quá trình lý luận (ví dụ: “Ồ chờ đã, thực ra…”) tăng gấp ba lần.
Kết luận của Lorenzo rất lạnh lùng. Đối với quy trình công việc kỹ thuật tiên tiến, lý luận sâu không phải là điều xa xỉ mà là điều kiện tiên quyết để có được mô hình. Giờ đây Claude không còn đáng tin cậy trong lĩnh vực kỹ thuật phức tạp nữa.
Tuy nhiên, cần lưu ý rằng phân tích của Lorenzo chỉ kết luận rằng thời gian suy nghĩ của Claude đã bị rút ngắn 67% vào cuối tháng 2 năm nay. Thật khó để nói một cách chặt chẽ rằng việc giảm lượng suy nghĩ tương đương trực tiếp với sự suy giảm trí thông minh trong dòng tweet.
2. Tường chứng thực trên mạng xã hội: 40 phút suy nghĩ và hóa đơn không hợp lệT AGPH108
Bài đăng của Lorenzo nhanh chóng làm bùng nổ mạng xã hội X và Reddit, và vô số nhà phát triển nhận thấy rằng các vấn đề họ gặp phải rất phù hợp với báo cáo này.
Nhà phát triển người nổi tiếng trên Internet Om Patel đã trực tiếp đăng kết luận về X. Có người đã đo xem Claude đã trở nên ngu ngốc đến mức nào và câu trả lời là 67%.
Lập luận của ông chủ yếu tập trung vào thực tế là lượng suy nghĩ trong Opus 4.6 ít hơn 2/3 so với trước. Anh ta viết một cách mỉa mai rằng Anthropic vẫn giữ im lặng cho đến khi các con số được công khai và nhóm của họ đã ra tay dập lửa.
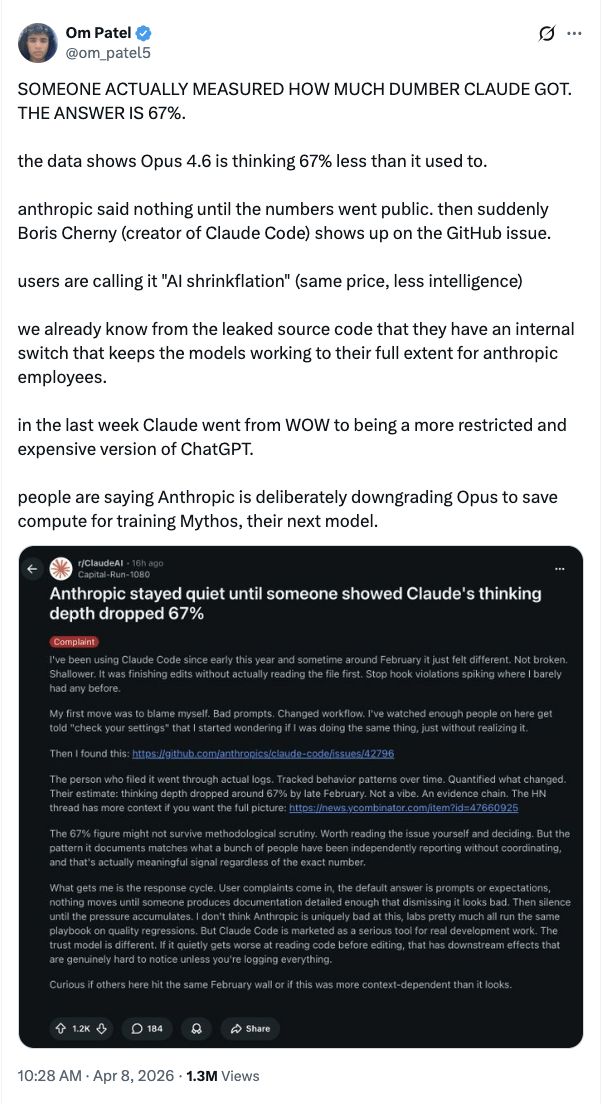
Patel cũng tiết lộ trong tweet rằng mã nguồn bị rò rỉ cho thấy họ có một công tắc bên trong giúp giữ mô hình ở trạng thái tối ưu khi nhân viên Anthropic sử dụng. Tuy nhiên, tuyên bố này chưa được xác minh độc lập và Anthropic không đáp ứng yêu cầu này.
Ông cũng thẳng thắn nói rằng một số người cho rằng Anthropic đã cố tình giảm hiệu suất của Opus để tiết kiệm tài nguyên máy tính để đào tạo mô hình tiếp theo của họ, Mythos. Nhưng suy đoán này cũng thiếu bằng chứng trực tiếp.
Trên Reddit, những lời phàn nàn của người dùng cụ thể hơn và bất lực:
Suy nghĩ về phương trình: Người dùng D tức giậnSetOfBewbs nói rằng anh ấy đã từng yêu cầu Claude xử lý một tệp 500 dòng. Kết quả là Claude rơi vào trạng thái suy nghĩ suốt 24 phút, chỉ ngồi đó. Một số cư dân mạng lặp lại điều này và yêu cầu nó tiến hành nghiên cứu. Hầu như không có token nào được sử dụng trong 40 phút nên không rõ nó đã làm gì trong 40 phút đó.
Hãy làm ngơ trước các quy tắc: Nhiều nhà phát triển đã quen với việc thiết lập các thông số kỹ thuật của dự án trong CLAUDE.md, nhưng giờ đây Claude dường như đang mắc chứng mất trí nhớ. Một người dùng giận dữ nhận xét rằng nếu bạn không để mắt đến đầu ra của nó, nó có thể phá hủy cơ sở mã của bạn trong vài phút.
Giá không thay đổi. Suy thoái trí tuệ: Đây là lạm phát co rút điển hình. Người dùng Reddit Firm_Meeting6350 cho biết, hôm nay tôi đã hủy đăng ký Claude Max 20 và chuyển sang Codex Pro. Claude bây giờ cảm thấy như tôi đang sử dụng một mô hình lỗi thời.
3. Điểm sương mù: từ thứ 2 đến thứ 1 giảm 0
Nếu khiếu nại của người dùng có thể được giải thích là cảm xúc chủ quan, thì bài kiểm tra điểm chuẩn dường như sử dụng dữ liệu thực để thảo luận.
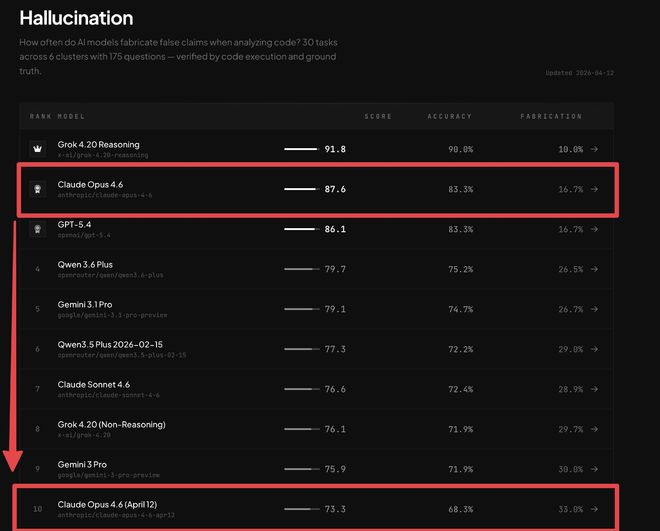
Vào ngày 12 tháng 4, BridgeMind, một tổ chức chuyên kiểm tra điểm chuẩn ảo giác, đã đưa ra một dòng tweet, trực tiếp đẩy cuộc tranh cãi lên đến đỉnh điểm.
Tweets tuyên bố rằng Claude Opus 4.6 đã bị giảm sức mạnh và BridgeBench vừa chứng minh điều đó. Tuần trước nó đứng thứ 2 với độ chính xác là 83,3%. Hôm nay nó đã được kiểm tra lại và tụt xuống vị trí thứ 10 với độ chính xác chỉ 68,3%. Tỷ lệ ảo giác tăng 98%.
Tuy nhiên, kết quả kiểm tra này đã bị bác bỏ. Nhà nghiên cứu AI bên ngoài Paul Calcraft sau đó đã chỉ ra rằng thử nghiệm này đã gây hiểu lầm và hai thử nghiệm của BridgeMind không phải là một so sánh táo với táo. Bài kiểm tra đầu tiên chỉ bao gồm 6 nhiệm vụ, trong khi bài kiểm tra thứ hai được mở rộng lên 30 nhiệm vụ.
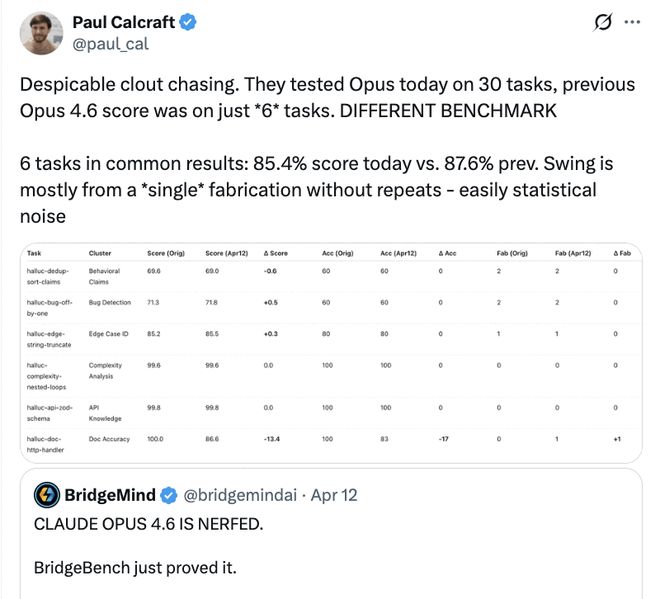
Calcraft chỉ ra rằng nếu chỉ nhìn vào 6 nhiệm vụ thông thường thì điểm của Claude chỉ dao động nhẹ từ 87,6% đến 85,4%. Sự sai lệch lớn nhất gần như đến từ một kết quả hư cấu duy nhất. Sự khác biệt này có thể được phân loại theo thống kê là tiếng ồn.
Bản thân tranh cãi về điểm chạy cũng cho thấy ngành này hiện thiếu một tiêu chuẩn kiểm tra điểm chuẩn hiệu suất AI thống nhất và có thể tái tạo. Nhiều bài kiểm tra có phong cách đưa ra kết luận trước rồi tìm kiếm lập luận sau, khiến người dùng khó có được câu trả lời xác định từ dữ liệu kiểm tra.
Tuy nhiên, dữ liệu tụt xuống vị trí thứ 10 đã lan truyền trên mạng xã hội. Tác động trực quan của ảnh chụp màn hình khiến nó trở thành bằng chứng mạnh mẽ nhất cho tuyên bố của Claude rằng anh ta bị bệnh tâm thần.
4. Phản hồi chính thức: Có Biến đổi thay vì suy yếu
Đối mặt với dư luận gay gắt, cốt lõi của Anthropic các thành viên trong nhóm đã phải trả lời công khai.
Người đứng đầu Claude Code, Boris Cherny đã giải thích cẩn thận nó dưới văn bản GitHub gốc của Lorenzo và đăng một số câu trả lời trên X. Chỉ có một điểm cốt lõi. Họ không làm suy yếu mô hình mà chỉ hạ thấp mức nỗ lực mặc định để đáp lại phản hồi của người dùng.
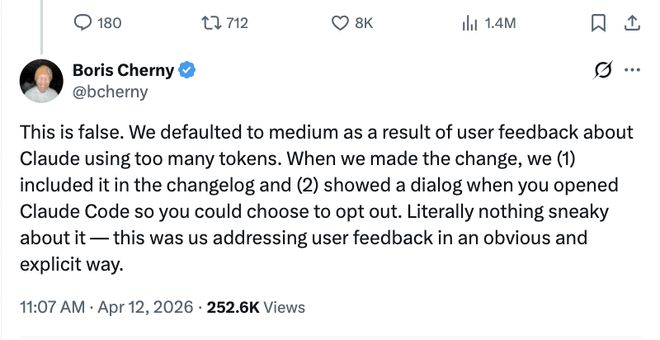
Cerny cho biết nhiều người dùng trước đây đã báo cáo rằng Claude đã tiêu thụ quá nhiều token. Để đáp lại phản hồi của người dùng, Anthropic đã thực hiện những thay đổi sau:
Hạ cấp nỗ lực mặc định: Vào ngày 3 tháng 3, nỗ lực suy luận sẽ được đặt ở mức trung bình theo mặc định. Nếu muốn suy luận sâu, bạn cần nhập thủ công các hướng dẫn nâng cao tương ứng.
Quy trình tư duy ẩn ở mặt trước: Màn hình hiển thị ở mặt trước đã thay đổi và các khối tư duy không còn được hiển thị đầy đủ, giúp giảm độ trễ nhưng điều này không ảnh hưởng đến ngân sách tư duy hoặc lý luận sâu sắc của mặt sau.
Cơ chế tư duy thích ứng: Cơ chế điều chỉnh năng động được giới thiệu vào ngày 9 tháng 2.
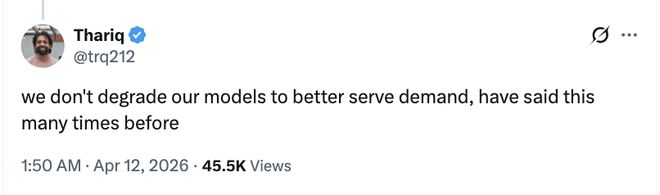
Thành viên nhóm Claude Code, Thariq Shihipar cũng ủng hộ sếp bộ phận của mình. Ông đã gửi một số dòng tweet để trấn an người dùng bằng những giải thích kỹ thuật và nhấn mạnh rằng công ty sẽ không giảm hiệu suất của mẫu máy để đáp ứng nhu cầu tốt hơn.
Điều đáng chú ý là Cherny đã đề cập đến việc hạ cấp nỗ lực mặc định có thể giải thích chính xác thời gian suy nghĩ bị rút ngắn, hành vi nghiên cứu giảm và tần suất bỏ nhiệm vụ tăng lên trong báo cáo phân tích của Lorenzo. Điều này rất phù hợp với cài đặt mặc định của lý luận trung bình.
Tuy nhiên, lời giải thích chính thức không thể xoa dịu được sự phẫn nộ của dư luận. Nhiều người dùng trên mạng xã hội tin rằng nếu hiệu suất giảm hoặc câu trả lời sai được đưa ra nhằm giúp người dùng tiết kiệm tiền thì kiểu tiết kiệm này là vô nghĩa.
Hơn nữa, công ty đã trực tiếp điều chỉnh mà không cần thông báo, điều này đã trực tiếp làm tổn hại đến quyền được biết của người dùng.
5. Trận chiến hậu trường: thời gian tồn tại của bộ đệm và tắc nghẽn năng lượng tính toán
Ngoài những thay đổi về độ sâu suy luận, nhiều người dùng cũng nhận thấy rằng Claude đã trở nên đắt hơn.
Số phản hồi 46829 trên GitHub chỉ ra rằng thời gian tồn tại của bộ đệm từ nhắc nhở của Claude Code đã được rút ngắn từ 1 giờ xuống còn 5 phút như ban đầu.

Điều này có nghĩa là đối với những lập trình viên làm việc lâu năm, những gì bạn vừa nói với Claude sẽ bị lãng quên sau 5 phút. Để tiếp tục làm việc, bạn cần tải lại ngữ cảnh lên.
Điều này không chỉ làm tăng độ trễ mà còn tăng mức tiêu thụ mã thông báo của người dùng, khiến một số người đăng ký bắt đầu đạt đến giới hạn sử dụng mà họ chưa từng gặp phải trước đây.
Kỹ sư nhân chủng học Jarred Sumner đã thừa nhận sự thay đổi này vào ngày 6 tháng 3, nhưng lập luận rằng đó là để thực hiện công việc tối ưu hóa bộ đệm đang diễn ra chứ không phải hạ cấp bí mật. Trong mắt các nhà phát triển, điều này tương đương với việc xác nhận rằng quan chức thực sự đang tích cực điều chỉnh hành vi bộ đệm trong nền và đây là khoảng thời gian mà mọi người phàn nàn rằng hạn ngạch bị tiêu thụ quá nhanh.
Cho dù Claude trở nên ngu ngốc hơn hay đắt giá hơn, cư dân mạng Reddit raven2cz đã đánh trúng đầu.
Hai vấn đề lớn này là giới hạn hạn ngạch và suy giảm khả năng tư duy có liên quan mật thiết đến tình trạng quá tải cơ sở hạ tầng. Chỉ cần vào GitHub và bạn sẽ biết. Hàng nghìn người dùng hiện đang phải đối mặt với vấn đề tương tự. Tình trạng này giống như khi GPT tung ra mẫu xe mới cách đây một năm rưỡi.
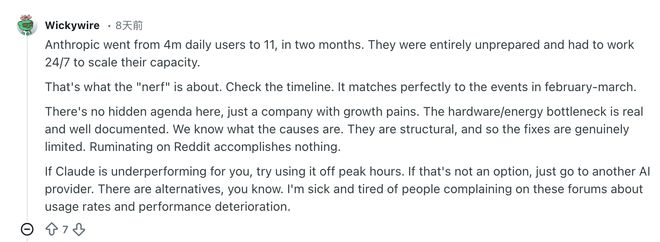
Netizen Wickywire đã phân tích lý do cơ bản là số người dùng hoạt động hàng ngày của Anthropic đã tăng từ 4 triệu lên 11 triệu trong hai tháng. Họ hoàn toàn không có sự chuẩn bị và phải làm việc suốt ngày đêm để mở rộng công suất. Đây là sự thật của cái gọi là sự suy yếu. Nếu bạn kiểm tra dòng thời gian, nó khớp chính xác với những gì đã xảy ra vào tháng Hai và tháng Ba.
Không có ý định ẩn giấu nào ở đây, chỉ là một công ty đang trải qua những khó khăn ngày càng tăng và những tắc nghẽn về phần cứng và năng lượng là có thật và được ghi chép rõ ràng.
Chúng tôi biết lý do và chúng mang tính cấu trúc, vì vậy các giải pháp thực sự rất hạn chế và chẳng ích gì khi phải đau đầu tìm kiếm chúng trên Reddit.
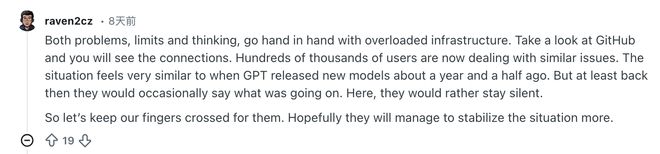
Giải pháp mà cư dân mạng này đưa ra là ngay lập tức và khả thi. Nếu bạn cho rằng hiệu suất của Claude không tốt, bạn có thể thử sử dụng nó trong giờ thấp điểm. Nếu cách đó không hiệu quả, bạn cũng có thể sử dụng nhà cung cấp dịch vụ AI khác. Dù sao đi nữa, không phải là bạn không có lựa chọn. Tôi thực sự chán ngấy những người phàn nàn về việc sử dụng và suy giảm hiệu suất trên diễn đàn.
6. Kết luận: Khủng hoảng niềm tin còn đáng sợ hơn trở nên ngu ngốc
Tình hình hiện tại là người dùng đang mô tả cảm giác cơ thể, trong khi Anthropic đang mô tả các thông số.
Người dùng cảm thấy rằng nó đã trở nên ngu ngốc và nhiệm vụ đã thất bại. Các quan chức cho biết họ không thay đổi trọng lượng mà chỉ thay đổi giá trị nỗ lực mặc định, rút ngắn bộ nhớ đệm và điều chỉnh màn hình giao diện người dùng đã được tiết lộ công khai.
Hai mô tả này thực ra không hề mâu thuẫn nhau. Trong lĩnh vực AI, ngay cả khi công ty tin rằng họ không làm suy yếu mô hình ở cấp độ thấp nhất, những thay đổi cài đặt tinh vi và hạn chế hạn ngạch sẽ khiến trải nghiệm không khác gì việc trở nên ngu ngốc đối với các nhà phát triển dựa vào nó suốt ngày đêm.
Khi các nhà phát triển bắt đầu nghi ngờ về tính ổn định của một công cụ thì sự rạn nứt trong lòng tin này cực kỳ khó sửa chữa.
Đặc biệt hiện nay khi những kẻ thù hùng mạnh đang rình rập, Codex của OpenAI sắp kết thúc. Nó dựa vào công suất tính toán ổn định hơn, đăng ký cấp trung linh hoạt và các chức năng tương tác mới để thu thập chính xác các nhà phát triển đang thất vọng.
Các công cụ nghiên cứu của nhà phát triển bên thứ ba cho thấy kể từ khi có tin đồn về trí thông minh của Claude vào cuối tháng 3 năm nay, số lượng người dùng Codex mới hàng tuần và các plugin liên quan của nó đã tăng khoảng 22% so với tháng trước.
Nếu Anthropic không thể tìm ra sự cân bằng thực sự giữa việc tiết kiệm chi phí điện năng tính toán và duy trì lý luận sâu sắc, thì danh tiếng mà Claude đã dày công xây dựng có thể bị thử thách trong cơn bão này.
Một số người dùng cũ nói rằng tôi thà trả số tiền gấp đôi cho một Claude thông minh còn hơn là chi số tiền tương tự cho một kẻ ngốc chỉ xin lỗi và hỏi thêm thông tin.
Màn trình diễn kéo co trong thế giới AI này vừa mới bắt đầu.