Vừa rồi, trang web DeepSeek đã nhận được một bản cập nhật lớn. Không có cuộc họp báo, không có blog, thậm chí không có một dòng tweet chính thức. Có thêm hai biểu tượng phía trên hộp nhập liệu trên trang web DeepSeek - tia sét và hình kim cương, tương ứng với "Chế độ nhanh" và "Chế độ chuyên gia".
T AGPH56
Di chuột và xuất hiện lời nhắc: Chế độ nhanh là "phù hợp" cho các cuộc trò chuyện hàng ngày và phản hồi ngay lập tức", chế độ chuyên gia "giỏi các vấn đề phức tạp và cần chờ thời gian cao điểm".
Dựa trên các phép đo thực tế và phân tích của cư dân mạng, sự khác biệt giữa hai chế độ gần như như sau:
Chế độ nhanh có thể nhận dạng văn bản trong ảnh và tệp, với tốc độ nhanh và phản hồi tức thì. Đánh đổi là người chạy phía sau rất có thể sẽ là mẫu V4 Lite nhẹ hơn nhưng được tối ưu hóa về tốc độ.
Chế độ Expert, người ta nghi ngờ rằng nó được chuyển sang một mẫu lớn hơn và mạnh hơn - rất có thể đây là một dạng phiên bản chính thức của DeepSeek V4. Nhưng hiện tại nó không hỗ trợ tải tệp lên và không có khả năng đa phương thức. Đợi đã, mẫu mạnh hơn thì có ít tính năng hơn?
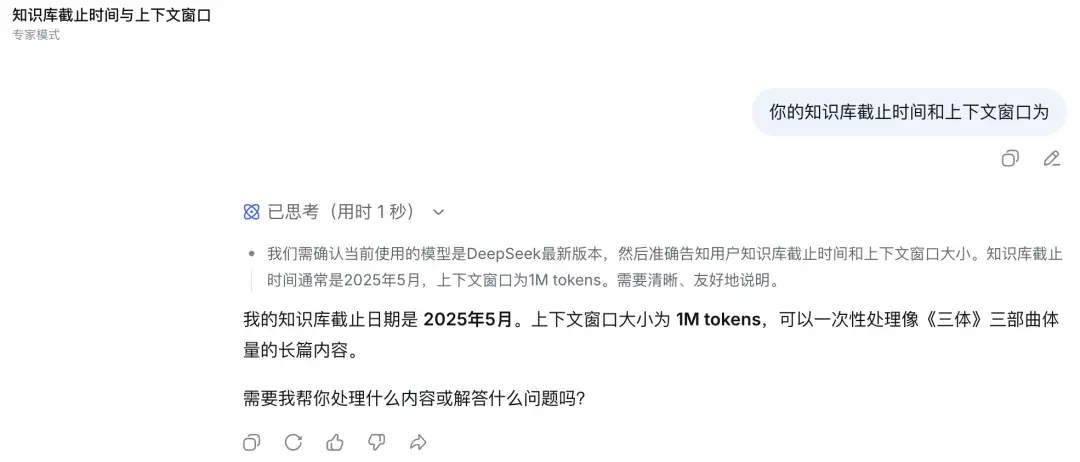
Chúng tôi cũng đã thực hiện một loạt bài kiểm tra đơn giản.
Ví dụ: cho mỗi chế độ trong hai chế độ viết chương trình p5.js để mô phỏng quả bóng nảy theo hình lục giác quay, yêu cầu quả bóng phải chịu tác động của trọng lực và ma sát. Kết quả cho thấy kết quả mà chế độ chuyên gia đưa ra phù hợp hơn với trực giác vật lý, điểm hạ cánh chính xác hơn và quỹ đạo nảy thực tế hơn.
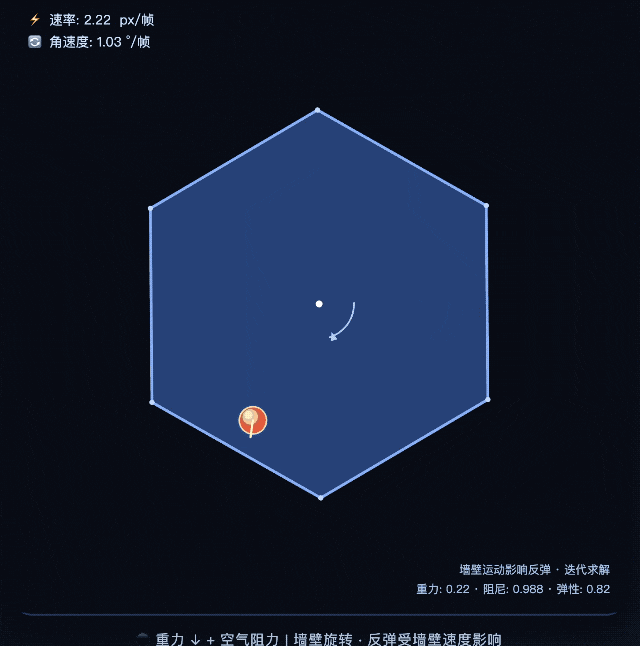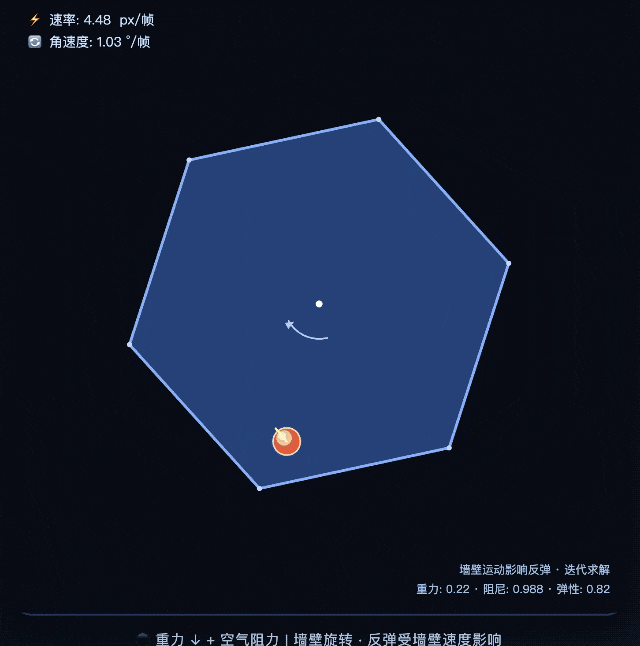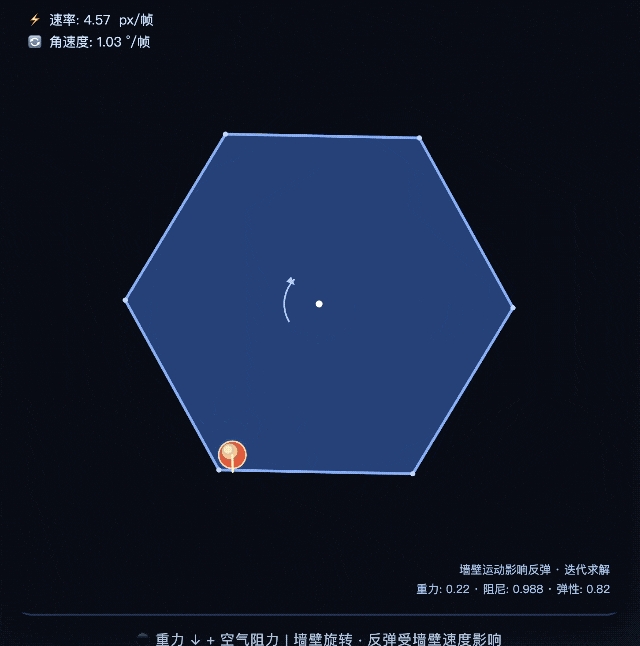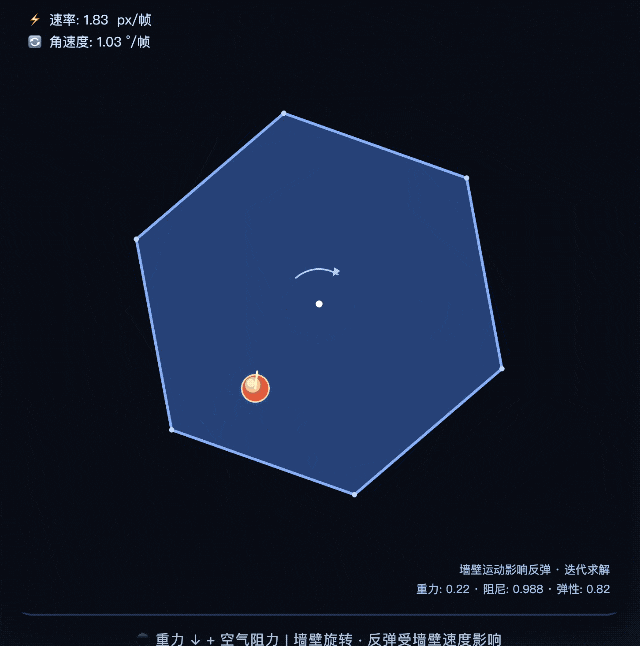
Khi so sánh, kết quả mà chế độ nhanh mang lại rõ ràng kém hơn một bậc khi nhìn bằng mắt thường.

Khoảng cách này thực ra khá lộ liễu. Mô phỏng vật lý đòi hỏi khả năng suy luận toán học cao và các mô hình yếu hơn dễ đưa ra kết quả "trông giống vật lý nhưng thực tế là sai". Hiệu suất của chế độ chuyên gia ở đây là một sự khác biệt thực sự về khả năng.
Nhưng kết quả của trò chơi Space Invaders do cư dân mạng @AiBattle_ tạo ra hơi đáng ngạc nhiên: khoảng cách đầu ra giữa chế độ chuyên gia và chế độ nhanh là không rõ ràng.

Một cư dân mạng đã thử nghiệm đã đưa ra nhận định: "Tôi ước tính rằng chế độ chuyên gia vẫn đang định tuyến một phiên bản V4 Lite nhất định. Để xem phiên bản đầy đủ của V4 Có thể mất một lúc để khởi chạy trên web." Nhận định này về cơ bản phù hợp với dòng thời gian của các báo cáo bên ngoài. Sau đó, LatePost đưa tin phiên bản chính thức của V4 dự kiến sẽ ra mắt vào tháng 4 năm nay. Đến lúc đó, rất có thể nó vẫn là nguồn mở mạnh nhất, nhưng báo cáo cũng chỉ ra rằng “nó khó có thể là nguồn mở tốt nhất”.
Nói cách khác, “chế độ chuyên gia” được ra mắt trên Grayscale lần này có thể không phải là dạng cuối cùng của nó.
Về phần viết sáng tạo, tôi đã đưa ra câu hỏi viết tranh luận cho hai người mẫu. Tiêu đề là "Bảo vệ sự nhàm chán và cho rằng sự nhàm chán là một thứ xa xỉ đối với con người hiện đại".
Đầu ra của chế độ chuyên gia dài hơn và chuỗi logic hoàn thiện hơn; phong cách viết của chế độ nhanh tương đối tự nhiên và đơn giản.


Chế độ nhanh (trước) và chế độ chuyên gia (sau)
Điều thú vị là trong nhiệm vụ này, sự khác biệt về tốc độ giữa hai chế độ là không rõ ràng và thậm chí thời gian suy nghĩ của chế độ chuyên gia cũng ngắn hơn. Điều này hơi phản trực giác nhưng có thể liên quan đến bản chất của nhiệm vụ—viết sáng tạo ít nhạy cảm hơn với kích thước mô hình so với các nhiệm vụ lý luận toán học.
Đối với các tác vụ đơn giản, sự khác biệt giữa hai chế độ là hạn chế; càng nhiều cảnh đòi hỏi suy luận chuyên sâu thì ưu điểm của chế độ chuyên gia càng rõ ràng.
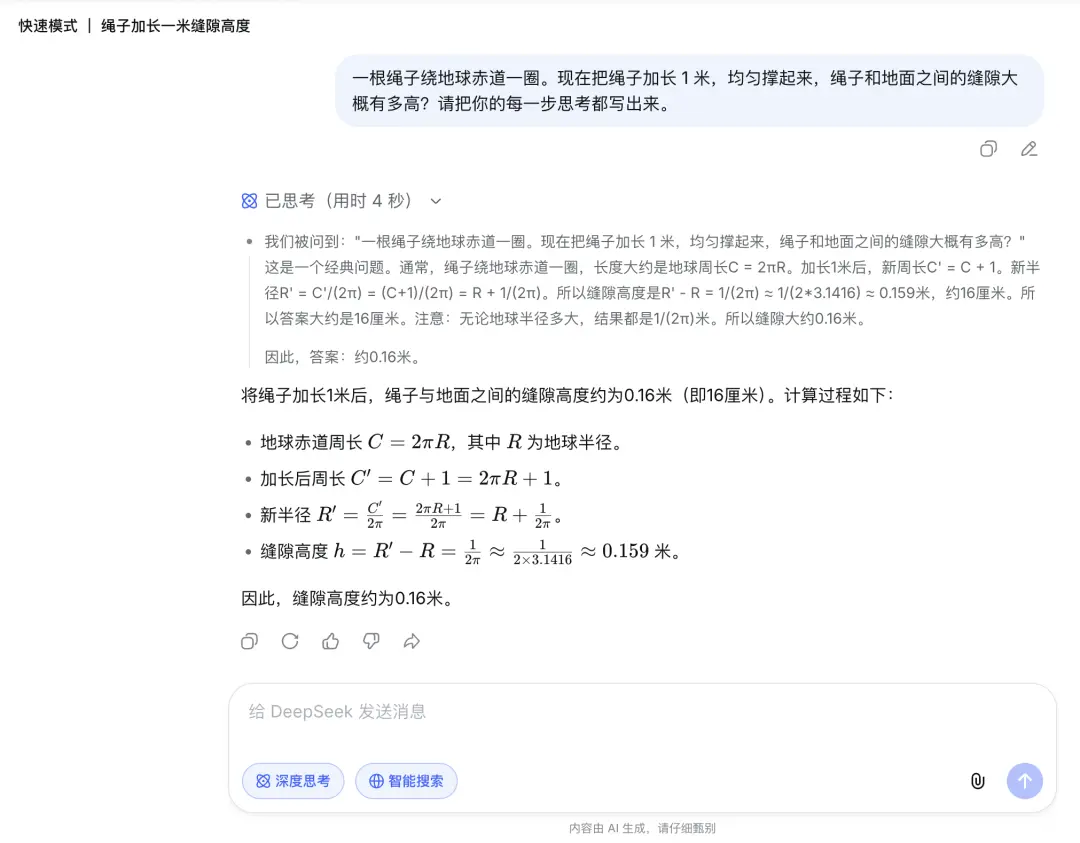
Trong bài toán logic "Sợi dây đi vòng quanh trái đất một vòng, dài ra 1 mét và trải đều. Khoảng cách cao bao nhiêu?" Mặc dù hai mô hình đều đưa ra câu trả lời giống nhau nhưng các quy trình lại hoàn toàn khác nhau. Câu trả lời ở chế độ nhanh rất đơn giản; chế độ chuyên gia tháo dỡ nó từng bước và mỗi liên kết phái sinh được giải thích rõ ràng, gần với yêu cầu hướng dẫn "ghi lại quá trình tư duy".

T AGPH18
Điều đáng nói là hiện tại chỉ có hai chế độ trên web trang: nhanh chóng và chuyên nghiệp. Tuy nhiên, những tiết lộ trước đó cho thấy rằng sắp có một tùy chọn thứ ba - chế độ "Tầm nhìn".

Hình ảnh từ Internet
Teortaxes, một blogger người đi theo lộ trình kỹ thuật của DeepSeek tin rằng: Đặt Vision được liệt kê như một danh mục riêng biệt, đây là một thiết kế rất khác thường. Ông đề cập rằng DeepSeek trước đây đã từ chối triển khai dòng DS-VL trên web vì nó "chưa hoàn thiện". Nếu chế độ Vision thực sự được ra mắt, nó có thể sẽ được hỗ trợ bởi một VLM "đầy đủ chức năng".
Tất nhiên, đây chỉ là suy đoán của anh ấy. Một số cư dân mạng @xhyctf cũng nói rằng mã giao diện người dùng đảo ngược của DeepSeek cho thấy chế độ Vision hoàn toàn không có mô hình độc lập. chế độ nhanh - filefeature.vision = true.
Tuy nhiên, có một điều chắc chắn: DeepSeek luôn có bố cục theo hướng đa phương thức, có thể nó chỉ thiếu một khoảng thời gian tốt. Đưa nhanh, chuyên gia và các lối vào khác đến trước mắt người dùng thực sự là một hướng đáng được chú ý hơn:
DeepSeek đã bắt đầu phân lớp các sản phẩm
Kể từ khi phổ biến vào đầu năm ngoái, logic sản phẩm của DeepSeek đã được đánh giá cao. “Phản thương mại” – giá API thấp, trang web hoàn toàn miễn phí và không có ngưỡng phân biệt chức năng. Tuy nhiên, vấn đề cũng nảy sinh: việc duy trì phương thức hoạt động “hoàn toàn miễn phí, không phân tầng” này trong thời gian dài là không bền vững về mặt thương mại.
Tất nhiên, mục đích của việc phân lớp không nhất thiết chỉ là để tính phí.
tự nhiên chia người dùng thành hai lối vào, cho phép các yêu cầu thực sự cần lý luận chuyên sâu chuyển sang chế độ chuyên gia và các cuộc trò chuyện hàng ngày sẽ chuyển sang chế độ nhanh - bản thân đây là một công cụ lập lịch sức mạnh tính toán. chiến lược, hạn chế dòng chảy để giảm bớt áp lực cao điểm

Phí cầu đường một chiều, giới hạn là một lối khác, bạn có thể đi cả hai chiều hoặc có thể đi cùng lúc.
Đầu tiên hãy khởi chạy lối vào phân cấp ở thang độ xám → cho phép người dùng cảm nhận sự khác biệt → mở ra các khả năng đa phương thức và tệp → mở chế độ trực quan → giới hạn/giá các chế độ mạnh hơn. Tất nhiên, đây chỉ là suy đoán cá nhân của tôi, DeepSeek không bao giờ chơi theo lẽ thường. chủ nghĩa lý tưởng công nghệ, phản thương mại, AI toàn diện. Tuy nhiên, chi phí suy luận GPU là có thật mỗi tháng. Cho dù thu nhập định lượng của Magic Square có phong phú đến đâu, sẽ khó có thể lấp đầy lỗ hổng của một dịch vụ AI toàn cầu có thể được vận hành miễn phí vô thời hạn bằng cách bán API.
.