Sáng sớm nay, Google DeepMind đã cho ra mắt mô hình nguồn mở thế hệ mới Gemma 4: với khoảng 30B tham số, gần bằng các mô hình nguồn mở head khác . Gemma là chuỗi mô hình nguồn mở của Google. Nó chia sẻ công nghệ cơ bản với Gemini hàng đầu nguồn đóng. Các trọng số hoàn toàn mở và bất kỳ ai cũng có thể tải xuống, sửa đổi và triển khai chúng.
Gemma 3 thế hệ trước được phát hành vào tháng 3 năm 2025 và đã tròn một năm kể từ bản cập nhật này. Một số mô hình nguồn mở trong nước đã được lặp lại nhiều lần trong năm nay và sự hiện diện của Google trong lĩnh vực nguồn mở ngày càng yếu đi
Lần này hãng đã phát hành bốn mô hình cùng một lúc, cụ thể là 2B, 4B, 26B và 31B, bao gồm tất cả các kịch bản từ điện thoại di động đến máy trạm. Giấy phép đã thay đổi từ giấy phép của chính Google thành Apache 2.0
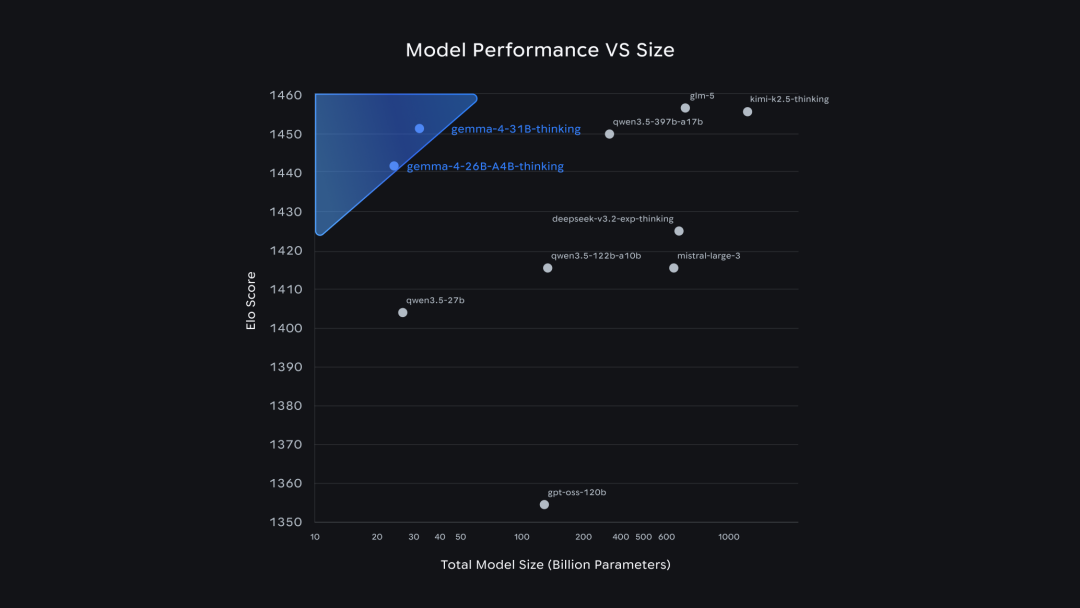
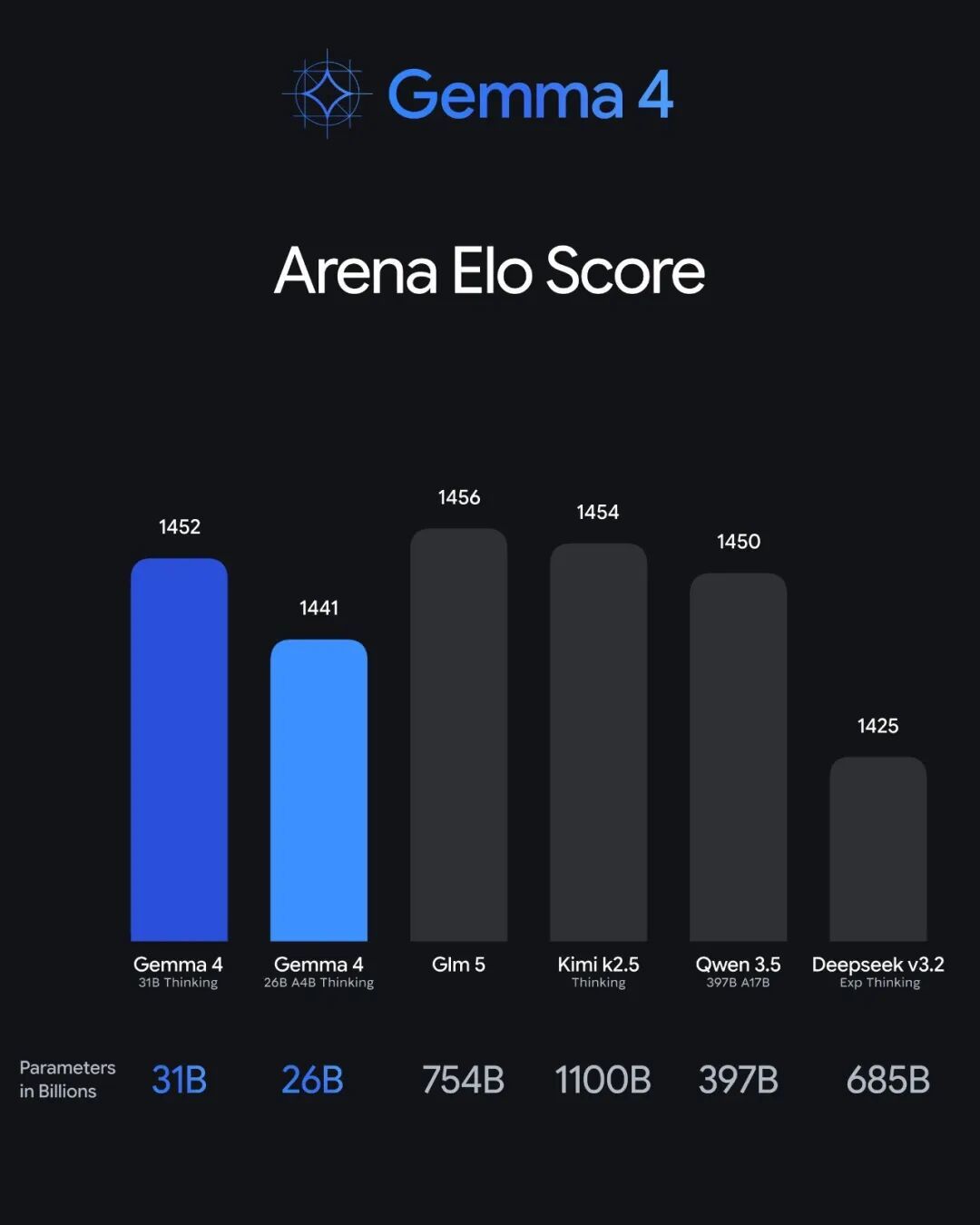
Gemma 4 trong bảng xếp hạng mã nguồn mở Arena AI Điểm Elo so với số lượng tham số, 31B đứng thứ ba, 26B MoE đứng thứ sáu
Bốn mẫu
Gemma 4 Bốn phiên bản đã được phát hành, chia thành nhóm mô hình lớn và nhóm mô hình nhỏ
31B Dense: 31 tỷ tham số được kích hoạt đầy đủ, 60 lớp, 256K ngữ cảnh. Theo đuổi giới hạn trên về chất lượng, Arena AI đứng thứ ba trong bảng xếp hạng nguồn mở. Trọng lượng bfloat16 không được lượng tử hóa có thể được lắp vào H100 80GB. Sau khi lượng tử hóa, card đồ họa dành cho người tiêu dùng cũng có thể chạy
26B A4B MoE: tổng cộng 25,2 tỷ tham số, 3,8 tỷ tham số kích hoạt, kiến trúc MoE (128 chuyên gia, 8 điểm cộng cho mỗi lần kích hoạt) 1 lượt chia sẻ), 30 lớp, 256K ngữ cảnh. Tốc độ suy luận gần bằng mô hình 4B và chất lượng vượt xa mức 4B. Xếp hạng số 6
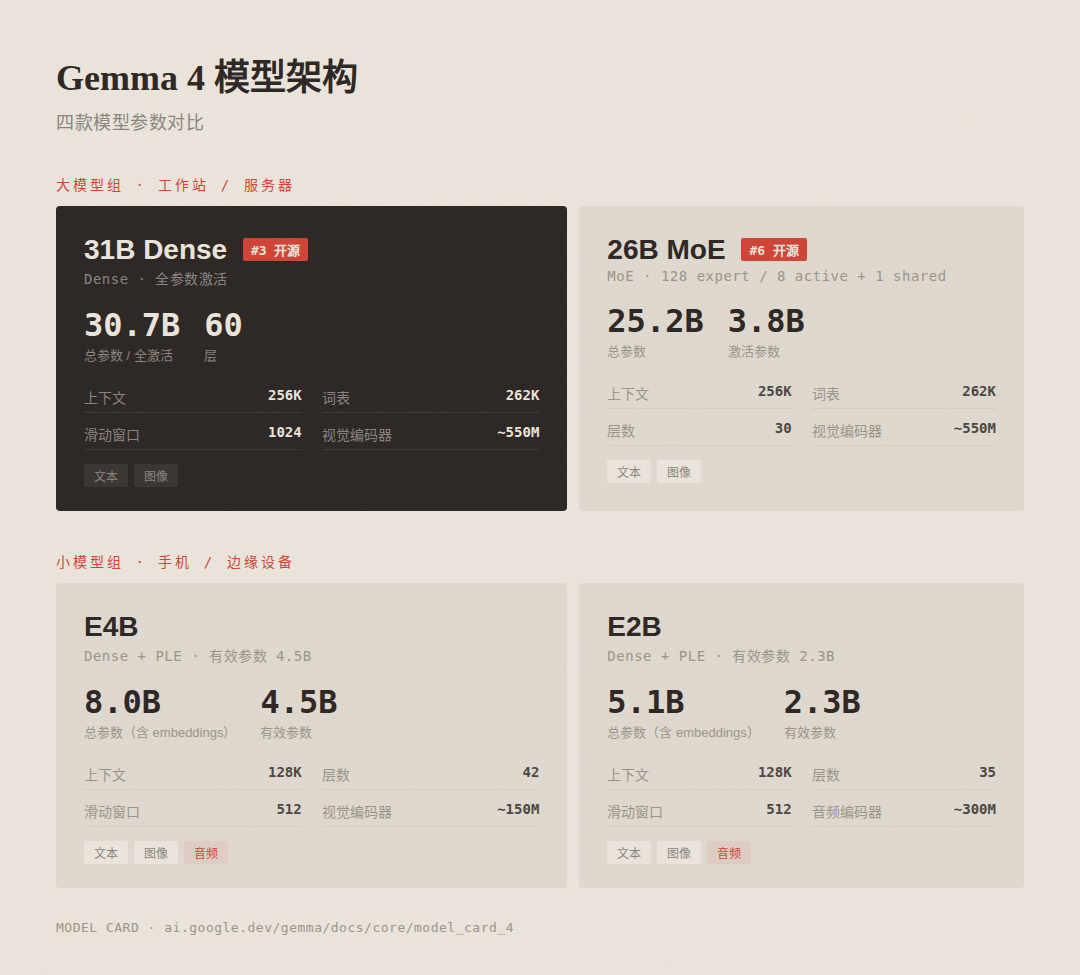
E4B:80 Tổng số 100 triệu tham số, 4,5 tỷ tham số hiệu quả, 42 lớp, bối cảnh 128K. Chữ E trong tên là viết tắt của Hiệu quả. Mô hình nhỏ sử dụng công nghệ Nhúng trên mỗi lớp. Tham số hiệu quả nhỏ hơn nhiều so với tổng tham số
E2B: Tổng cộng 5,1 tỷ tham số, 2,3 tỷ tham số hiệu quả, 35 lớp, bối cảnh 128K. Theo báo cáo chính thức, mức sử dụng bộ nhớ có thể giảm xuống 1,5 GB trên một số thiết bị. Sau đây

So sánh khả năng chính thức của bốn kiểu máy
Tất cả các kiểu máy đều hỗ trợ đầu vào hình ảnh và video, hỗ trợ 140 Đa ngôn ngữ
Mỗi mẫu đều có nhiều chế độ. Mẫu nhỏ hỗ trợ nhập bằng giọng nói nhưng mẫu lớn không hỗ trợ
E2B và E4B, mỗi mẫu đều có bộ mã hóa âm thanh với khoảng 300 triệu thông số, có thể nhận dạng giọng nói và dịch giọng nói (tối đa 30 giây). Model lớn hơn không có khả năng âm thanh. Từ góc độ logic sản phẩm, giọng nói trên điện thoại di động là một nhu cầu thiết yếu, nhưng không phải trong các tình huống ở máy trạm.
Google đã hợp tác với nhóm Pixel, Qualcomm và MediaTek để tối ưu hóa việc triển khai phía thiết bị. E2B và E4B có thể chạy hoàn toàn offline trên điện thoại di động, Raspberry Pi, và NVIDIA Jetson Orin Nano
Achievements
Hãy để tôi bắt đầu bằng kết luận: So với Gemma 3 27B thế hệ trước, sự cải thiện của nhiều chỉ số cốt lõi là cấp độ thế hệ
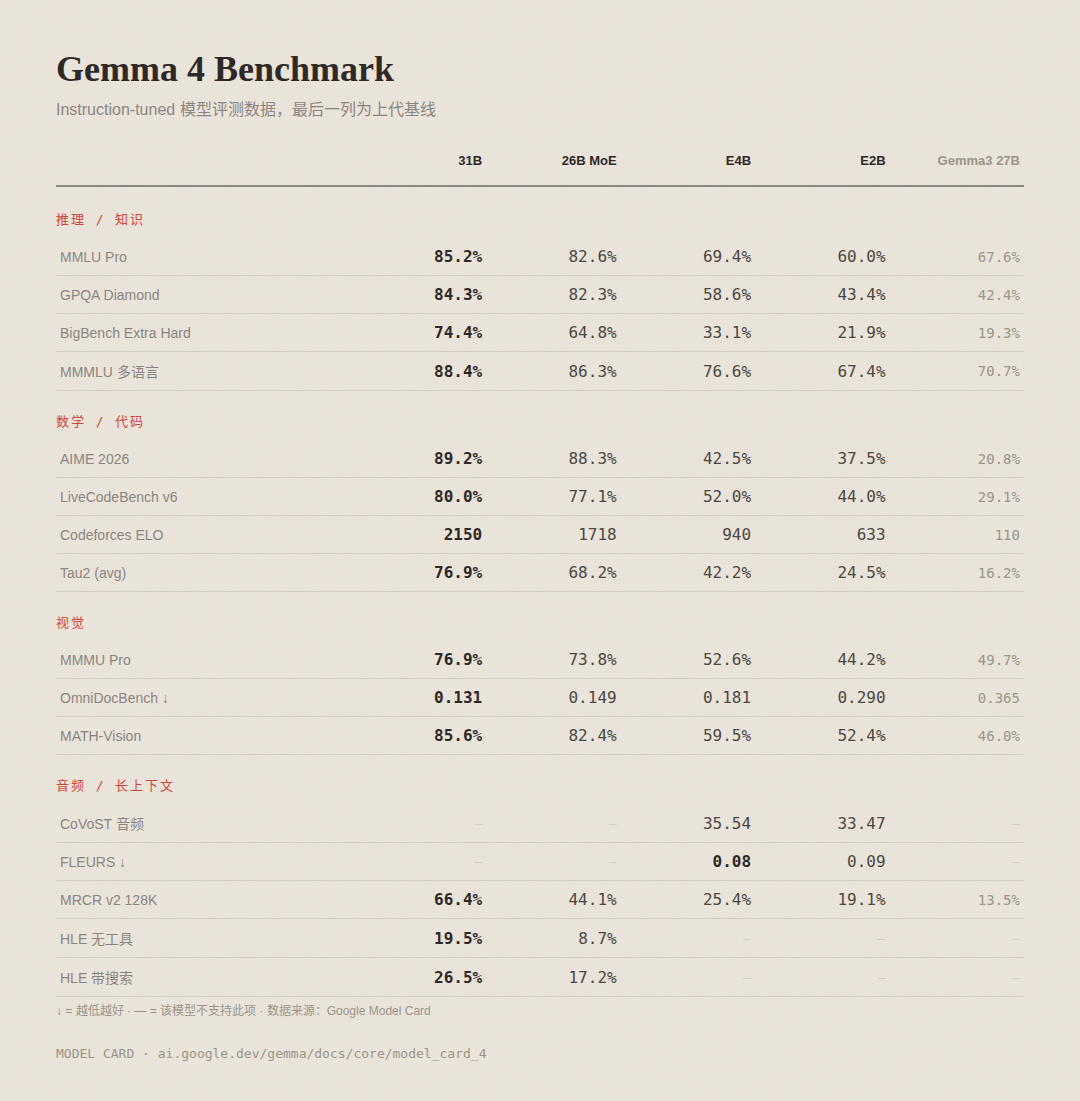
Dữ liệu điểm chuẩn hoàn chỉnh của Gemma 4, cột cuối cùng là Đường cơ sở Gemma 3 27B
Toán học : Kỳ thi cạnh tranh AIME 2026, 31B Đạt 89,2%, Gemma 3 27B Có 20,8%
Mã : Codeforces ELO được kéo từ 110 xuống 2150. LiveCodeBench v6 từ 29,1% xuống 80,0%. Mã là hướng tiến bộ lớn nhất lần này
Lý luận toàn diện: GPQA Diamond (Câu hỏi và câu trả lời về khoa học cấp độ sau đại học) từ 42,4% đến 84,3%. MMLU Pro từ 67,6% xuống 85,2%
Visual: MMMU Pro từ 49,7% xuống 76,9%. Tài liệu OCR (OmniDocBench) từ 0,365 đến 0,131
Ngữ cảnh dài: MRCR v2 128K từ 13,5% đến 66,4%. Ngữ cảnh dài trước đây là thiếu sót của Gemma nhưng lần này đã được bổ sung
Đa ngôn ngữ : MMMLU từ 70,7% lên 88,4%. Được đào tạo nguyên bản trên hơn 140 ngôn ngữ
26B MoE và 31B chỉ cách nhau 2 đến 5 điểm phần trăm trên hầu hết các chỉ số nhưng lại suy luận nhanh hơn nhiều. 26B MoE tiết kiệm chi phí hơn trong các tình huống nhạy cảm với độ trễ
MMLU Pro 69,4%% của E4B, chỉ với 4,5 tỷ tham số hiệu quả, gần bằng Cấp 27B thế hệ trước
Năng lực cốt lõi
Lý luận và suy nghĩ . Cả bốn mô hình đều có chế độ tư duy tích hợp có thể bật và tắt. Khi được bật, trước tiên mô hình sẽ đưa ra lý luận nội bộ rồi đưa ra câu trả lời. Các nhiệm vụ toán học, logic và lập kế hoạch nhiều bước hiệu quả hơn nhiều và có cùng nguồn gốc với khả năng tư duy của Song Tử
Quy trình làm việc của nhân viên. Hỗ trợ gốc cho các lệnh gọi hàm và đầu ra JSON có cấu trúc cho phép các mô hình gọi các công cụ và API bên ngoài. Google đồng thời phát hành Bộ công cụ phát triển đại lý (ADK), một khung Đại lý nguồn mở. E2B/E4B phía khách hàng cũng có thể chạy Tác nhân và đã có ứng dụng trình diễn
tạo mã trong Thư viện Google AI Edge. Hỗ trợ viết mã ngoại tuyến. Codeforces ELO 2150, LiveCodeBench 80,0%, có sẵn trong các kịch bản tạo và hoàn thành mã
Hiểu biết đa phương thức . Tất cả các kiểu máy đều có thể xử lý hình ảnh và video (video được xử lý từng khung hình, dài tối đa 60 giây). Hình ảnh hỗ trợ độ phân giải và tỷ lệ khung hình có thể thay đổi, ngân sách mã thông báo trực quan có thể được định cấu hình theo cách thủ công (năm cấp độ từ 70 đến 1120), tốc độ thay đổi ngân sách thấp và độ chính xác thay đổi ngân sách cao. OCR, phân tích cú pháp tài liệu và hiểu biểu đồ là những tình huống chính
Tài liệu dài. Bối cảnh 256K cho mô hình lớn, 128K cho mô hình nhỏ. Kiến trúc sử dụng cơ chế chú ý kết hợp (cửa sổ trượt cục bộ + xen kẽ chú ý chung) và lớp toàn cầu sử dụng KV thống nhất và RoPE tỷ lệ để tối ưu hóa dấu chân bộ nhớ của các ngữ cảnh dài
Đa ngôn ngữ. Đào tạo bản địa bằng hơn 140 ngôn ngữ, MMMLU 88,4%
Apache 2.0
Trước khi Gemma 1/2/3 sử dụng Google Thỏa thuận cấp phép riêng của họ cho phép sử dụng thương mại nhưng có các điều khoản bổ sung. Lần này nó được thay thế trực tiếp bằng Apache 2.0, một trong những giấy phép thân thiện với thương mại nhất được cộng đồng nguồn mở công nhận. Các nhà phát triển có thể tự do sửa đổi, phân phối và sử dụng nó cho mục đích thương mại và không có ngưỡng người dùng.
Người đồng sáng lập Hugging Face Clément Delangue nhận xét rằng đây là một cột mốc quan trọng. Nhìn vào chính dòng Gemma (ba thế hệ giao thức tùy chỉnh → Apache 2.0), đây là một sự thay đổi rõ ràng
Google Lựa chọn giấy phép trả lời một câu hỏi đã được thảo luận trong hai năm: Các nhà sản xuất lớn chân thành đến mức nào trong việc thực hiện nguồn mở
Các đối thủ cạnh tranh trong nguồn mở track
Bảng xếp hạng nguồn mở Arena AI, Gemma 4 31B xếp thứ ba, 26B MoE Xếp thứ sáu. Top đầu chủ yếu là các mô hình nguồn mở trong nước
Các đối thủ cạnh tranh chính trong đường đua nguồn mở là DeepSeek (V3.2 đang được sử dụng, V4 sẽ sớm được phát hành), Tongyi Qianwen Qwen3.5, Zhipu GLM-5.1, MiniMax M2.5 và Dark Side of the Moon Kimi K2.5. Các công ty này tung ra phiên bản mới rầm rộ vào dịp Tết Nguyên đán năm nay. Số lượng tham số dao động từ hàng chục tỷ đến hàng trăm tỷ. Mỗi cái đều tập trung vào lý luận, mã, tác nhân, v.v.
Gemma 4 có kích thước tối đa chỉ 31B và trần số lượng tham số là một hạn chế. Nhưng Gemma 4 đã làm được nhiều nhất về mặt tính toàn vẹn kỹ thuật cho việc triển khai phía khách hàng: hợp tác cấp chip với Qualcomm và MediaTek, tích hợp tự nhiên với hệ sinh thái Android và sự thuận tiện tuân thủ của Apache 2.0. Đây là những khác biệt của nó.
Dữ liệu đào tạo tính đến tháng 1 năm 2025 và thành phần cụ thể của dữ liệu đào tạo không được tiết lộ.