Cuộc cạnh tranh sức mạnh tính toán AI toàn cầu đã đạt đến một bước ngoặt lớn về mặt kỹ thuật! Gần đây, Google đã công bố công nghệ nén bộ nhớ AI mới "TurboQuant", đã thu hút được sự chú ý lớn trong ngành. Công nghệ này tuyên bố có thể giảm yêu cầu về không gian của "bộ đệm giá trị khóa" (KV Cache) tiêu tốn nhiều tài nguyên nhất trong giai đoạn suy luận AI tổng quát xuống còn 1/6 so với ban đầu mà không làm giảm độ chính xác của mô hình và tăng tốc độ tính toán lên 8 lần.
Công nghệ đột phá này cũng gây ra mối lo ngại trên toàn thị trường rằng nhu cầu bộ nhớ sẽ giảm mạnh. Các cổ phiếu liên quan đến lưu trữ của Mỹ như Micron, Sandisk và Western Digital đã giảm mạnh.
TurboQuant chính xác là gì?
Trong quy trình suy luận LLM (Mô hình ngôn ngữ lớn), để xử lý các văn bản dài, hệ thống phải lưu trữ thông tin cuộc hội thoại trong quá khứ trong KV Cache, giống như một "sổ tay di động" AI. Khi thời lượng cuộc trò chuyện tăng lên, thông tin cần lưu trữ trong cuốn sổ này sẽ nhanh chóng lấn át bộ nhớ băng thông cao (HBM) của AI GPU, trở thành nút thắt lớn nhất trong hoạt động của AI.
Ưu điểm cốt lõi của công nghệ TurboQuant của Google là giải quyết "nhiễu bộ nhớ" (Overhead) do công nghệ nén bộ nhớ truyền thống tạo ra. Công nghệ này bao gồm hai phần chính:
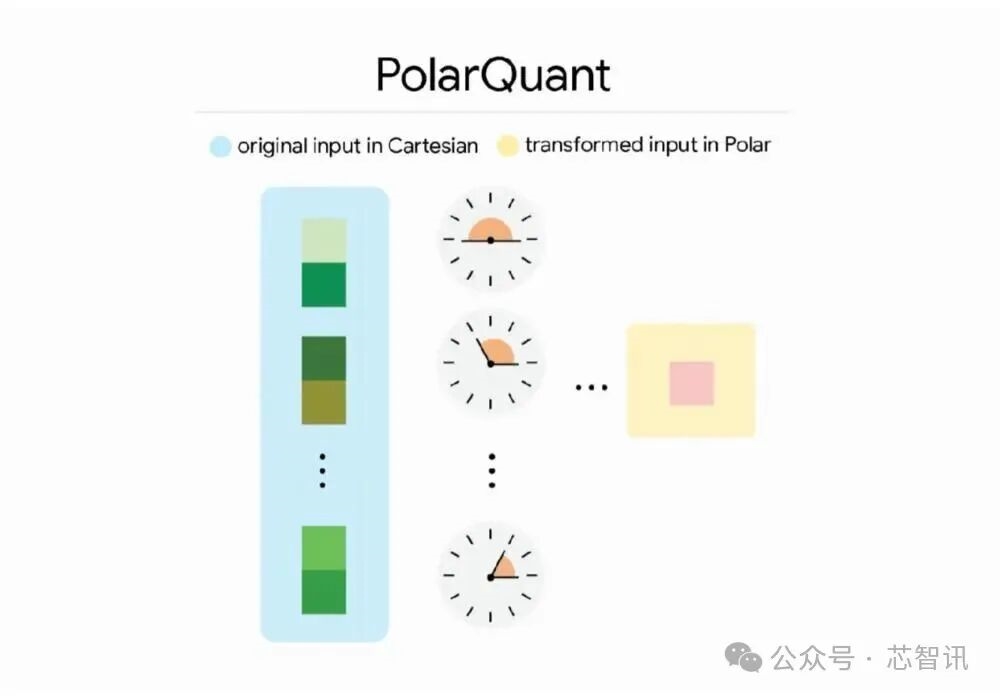
PolarQuant (lượng tử hóa tọa độ cực): Các vectơ truyền thống được đánh dấu bằng tọa độ XYZ và thao tác rất cồng kềnh. Thay vào đó, Google sử dụng logic "tọa độ cực" để đơn giản hóa các hướng phức tạp thành "bán kính" và "góc". Điều này giống như việc đơn giản hóa thông tin ban đầu được gắn nhãn “đi bộ 3 km về phía đông và 4 km về phía bắc” thành “đi bộ 5 km ở góc 37 độ”. Sự chuyển đổi cấu trúc hình học này làm giảm đáng kể tải xử lý dữ liệu.
QJL (Quantized Johnson-Lindenstrauss): Đây là cơ chế hiệu chỉnh toán học 1-bit cực kỳ hợp lý. Chỉ cần sử dụng thêm 1 bit để sửa chính xác lỗi còn sót lại trong quá trình nén, nhờ đó dù mô hình có bị nén chỉ còn 3 bit vẫn có thể đạt được mức "mất độ chính xác bằng 0" trong nhiều bài kiểm tra benchmark như LongBench.
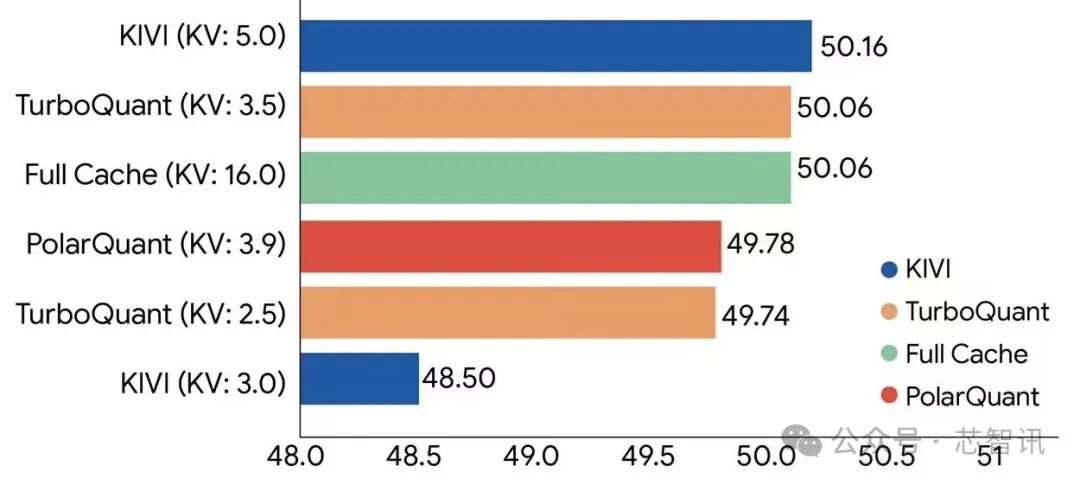
△ Trên mẫu Llama-3.1-8B-Instruct, TurboQuant đã thể hiện hiệu suất nén bộ đệm KV mạnh mẽ trong điểm chuẩn LongBench, vượt trội so với các phương pháp nén khác nhau. (Độ rộng bit được biểu thị trong ngoặc đơn).
Google đã chọn mở nguồn hoàn toàn bộ công nghệ này để có thể trở thành khả năng cạnh tranh cốt lõi. Nó không chỉ tối ưu hóa hiệu quả truy xuất của các mô hình lớn như Gemini mà còn giảm sự phụ thuộc vào bộ nhớ đối với các mô hình lớn khác và mở đường cho việc đẩy nhanh sự phát triển của AI đầu cuối.
Theo đo thực tế, trên bộ tăng tốc NVIDIA H100, hiệu suất của TurboQuant được cải thiện tới 8 lần so với giải pháp không nén và mô hình có thể được gắn trực tiếp mà không cần đào tạo lại. Có thể gọi nó là “vũ khí thần kỳ” giúp giảm chi phí và tăng hiệu quả trong triển khai AI.
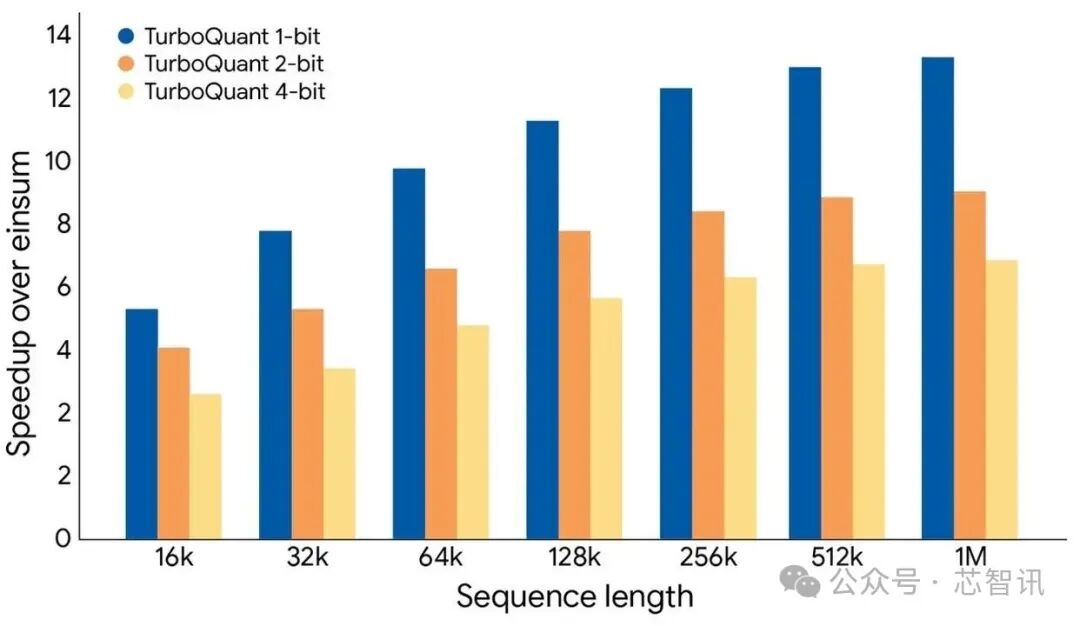
△Trên bộ tăng tốc NVIDIA H100, TurboQuant đã thể hiện những cải tiến hiệu suất đáng kể trong việc tính toán các giá trị logic chú ý trong bộ nhớ đệm khóa-giá trị, vượt trội so với đường cơ sở JAX được tối ưu hóa cao ở nhiều mức băng thông bit khác nhau.
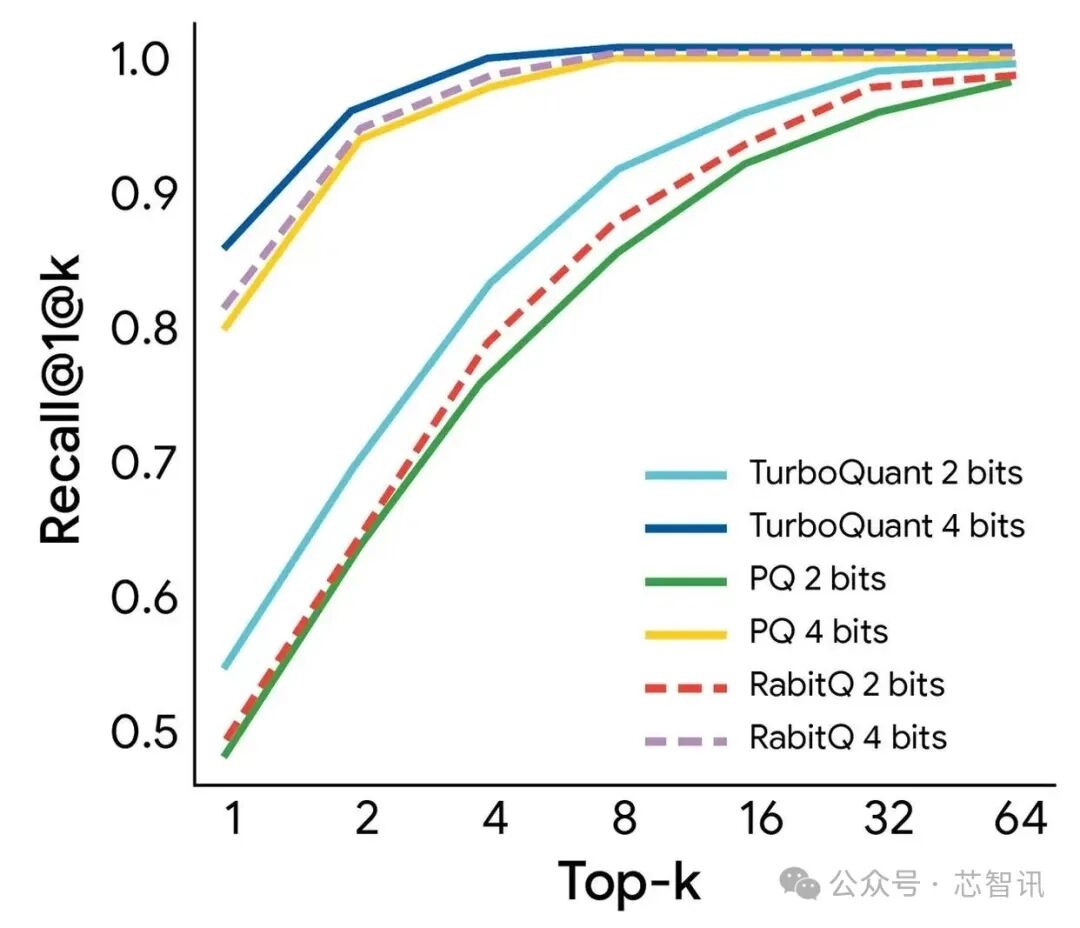
△TurboQuant thể hiện hiệu suất truy xuất mạnh mẽ, đạt được mức thu hồi 1@k tốt nhất trên tập dữ liệu GloVe (d=200) so với các đường cơ sở lượng tử hóa tiên tiến khác nhau.
Giám đốc điều hành Cloudflare, Matthew Prince và những người khác đã gọi TurboQuant là "khoảnh khắc DeepSeek" của Google và tin rằng nó được kỳ vọng, giống như DeepSeek, sẽ giảm đáng kể chi phí vận hành của AI thông qua mức tăng hiệu suất cực cao trong khi vẫn duy trì tính cạnh tranh về kết quả.
Yêu cầu bộ nhớ sẽ giảm hay sẽ tạo ra yêu cầu lớn hơn?
Về công nghệ TurboQuant, vốn gây ra lo ngại về nhu cầu bộ nhớ giảm mạnh trên toàn thị trường, các chuyên gia trong ngành và tổ chức nghiên cứu cũng đưa ra những quan điểm hoàn toàn khác:
Nhà phân tích Andrew Rocha của Wells Fargo đã chỉ ra: “Khi cửa sổ ngữ cảnh (cửa sổ ngữ cảnh) ngày càng lớn hơn, KV Sự tăng trưởng bùng nổ của Cache ban đầu là sự đảm bảo cho việc thúc đẩy nhu cầu bộ nhớ, nhưng TurboQuant đang trực tiếp tấn công vào đường cong chi phí này. Sau khi được áp dụng rộng rãi, các yêu cầu đặc điểm kỹ thuật về dung lượng bộ nhớ trong trung tâm dữ liệu sẽ đặt ra những câu hỏi lớn.” Tuy nhiên, ngân hàng đầu tư nổi tiếng Morgan Stanley và tổ chức nghiên cứu Lynx Equity. Các chiến lược đã đưa ra một cái nhìn hoàn toàn khác.
Morgan Stanley tin rằng thị trường có thể đã bỏ qua quy luật kinh tế rằng "cải thiện hiệu quả sẽ thúc đẩy tăng trưởng tổng thể". Khi chi phí bộ nhớ cần thiết cho tính toán AI giảm xuống còn 1/6 so với ban đầu, điều này sẽ gây ra sự bùng nổ lớn về nhu cầu đối với các ứng dụng AI mà trước đây không thể truy cập trực tuyến vì bộ nhớ quá đắt (chẳng hạn như dịch văn bản dài, tạo mã phức tạp) và thay vào đó sẽ lấp đầy hoặc thậm chí vượt quá khoảng trống bộ nhớ đã nén.
Đây là nghịch lý của Jevon, tức là khi tiến bộ công nghệ cải thiện hiệu quả sử dụng tài nguyên (giảm số lượng cần thiết cho bất kỳ hình thức sử dụng nào), nhưng việc giảm chi phí lại dẫn đến tăng nhu cầu, khiến tốc độ tiêu thụ tài nguyên tăng thay vì giảm.
Nhà phân tích Joseph Moore của Morgan Stanley và nhóm của ông đã chỉ ra trong một ghi chú dành cho nhà đầu tư phát hành hôm thứ Năm: "Có những báo cáo rằng TurboQuant của Google sẽ khiến mức sử dụng bộ nhớ giảm xuống còn 1/6 so với ban đầu, nhưng điều này bỏ qua rằng họ chỉ đề cập đến KV Cache chứ không phải mức sử dụng bộ nhớ tổng thể.
“Điều đáng chú ý là cả hai Các mẫu Gemini 3 và 2.5 Pro của Google có cửa sổ ngữ cảnh lên tới 1 triệu mã thông báo, nhưng Google đã tiết lộ rằng họ đã thử nghiệm tới 1000 mã thông báo với Gemini 1.5 Pro. Moore cho biết: “Cửa sổ bối cảnh gồm 10.000 mã thông báo và đạt được kết quả rất tốt, nhưng cuối cùng họ đã không phát hành mô hình do chi phí suy luận cao”. “Vì vậy, chúng tôi hy vọng rằng khi loại hình đổi mới này và các công nghệ khác xuất hiện, chi phí sẽ giảm và công nghệ này sẽ được sử dụng để phục vụ các sản phẩm thông minh hơn, có tính toán chuyên sâu hơn”. "
Morgan Stanley còn chỉ ra thêm rằng TurboQuant chủ yếu tối ưu hóa bộ nhớ đệm trong "giai đoạn suy luận" chứ không phải trọng lượng mô hình trong "giai đoạn huấn luyện". Do đó, tác động lên logic mua sắm HBM (bộ nhớ băng thông cao) hỗ trợ đào tạo lõi AI là tương đối hạn chế.
Ngược lại, TurboQuant có ý nghĩa hơn đối với việc triển khai trí tuệ nhân tạo trong các thiết bị đầu cuối chẳng hạn như điện thoại di động và máy tính xách tay. Do bộ nhớ của thiết bị di động có hạn, loại công nghệ nén hiệu quả này có thể cho phép chạy các mô hình AI mạnh mẽ hơn trên điện thoại di động, từ đó sẽ kích thích nâng cấp toàn diện các thông số bộ nhớ trong các thiết bị đầu cuối khác nhau. giảm nhu cầu về bộ nhớ và bộ nhớ flash trong vòng 3 đến 5 năm tới do nguồn cung hạn chế