Vào thứ Ba theo giờ miền Đông, Google đã phát hành thuật toán mới nhất đã bùng nổ trong giới công nghệ ở Thung lũng Silicon: thuật toán nén bộ nhớ AI cực kỳ hiệu quả TurboQuant. Google tuyên bố rằng thuật toán này có thể giảm dung lượng bộ nhớ đệm của các mô hình ngôn ngữ lớn ít nhất 6 lần và cải thiện hiệu suất 8 lần mà không làm mất độ chính xác. Về bản chất, nó cho phép trí tuệ nhân tạo ghi nhớ nhiều thông tin hơn trong khi chiếm ít không gian bộ nhớ hơn.

Ngay sau khi thuật toán này được tung ra, lượng tồn kho chip của Mỹ đã giảm. Google và Phố Wall cũng bắt đầu tranh luận sôi nổi: Liệu thảm họa thiếu chip nhớ hiện nay đang gây khó khăn cho nhiều gã khổng lồ công nghệ có thể kết thúc tại đây?
TurboQuant là gì?
Trước tiên hãy nói về thuật toán TurboQuant này là gì.
Theo giới thiệu của Google trên trang web chính thức, TurboQuant là phương pháp nén có thể giảm đáng kể kích thước mô hình mà không làm mất bất kỳ độ chính xác nào, vì vậy nó rất phù hợp để hỗ trợ nén bộ nhớ đệm khóa-giá trị (KV Cache) và tìm kiếm vectơ. Nó đạt được điều này thông qua hai bước chính:
1. Nén chất lượng cao (phương pháp PolarQuant): TurboQuant trước tiên xoay ngẫu nhiên vectơ dữ liệu. Bước thông minh này giúp đơn giản hóa hình học của dữ liệu, giúp dễ dàng áp dụng bộ lượng tử hóa chất lượng cao tiêu chuẩn cho từng phần của vectơ riêng biệt. Giai đoạn đầu tiên sử dụng hầu hết công suất nén (hầu hết các bit) để bảo toàn các khái niệm và đặc điểm chính của vectơ gốc.
2. Loại bỏ các lỗi ẩn: TurboQuant sử dụng một lượng nhỏ công suất nén còn lại (chỉ 1 bit) để áp dụng thuật toán QJL cho các lỗi nhỏ còn sót lại từ giai đoạn đầu. Giai đoạn QJL hoạt động như một trình kiểm tra lỗi toán học, loại bỏ sai lệch, mang lại điểm chú ý chính xác hơn.
Nói một cách đơn giản, TurboQuant về cơ bản nén mô hình AI trong khi vẫn giữ nguyên cấu trúc cốt lõi của mô hình AI và không yêu cầu xử lý trước hoặc dữ liệu hiệu chuẩn cụ thể.
Google tuyên bố rằng họ đã sử dụng các mô hình ngữ cảnh dài nguồn mở (Gemma và Mistral) để đánh giá nghiêm ngặt ba thuật toán TurboQuant, PolarQuant và KIVI trong nhiều bài kiểm tra điểm chuẩn bao gồm LongBench, Needle In A Haystack, ZeroSCROLLS, RULER và L-Eval.
Dữ liệu thử nghiệm cho thấy TurboQuant đạt được hiệu suất chấm điểm tối ưu về mặt biến dạng và thu hồi sản phẩm chấm, đồng thời giảm thiểu mức sử dụng bộ nhớ khóa-giá trị (KV).
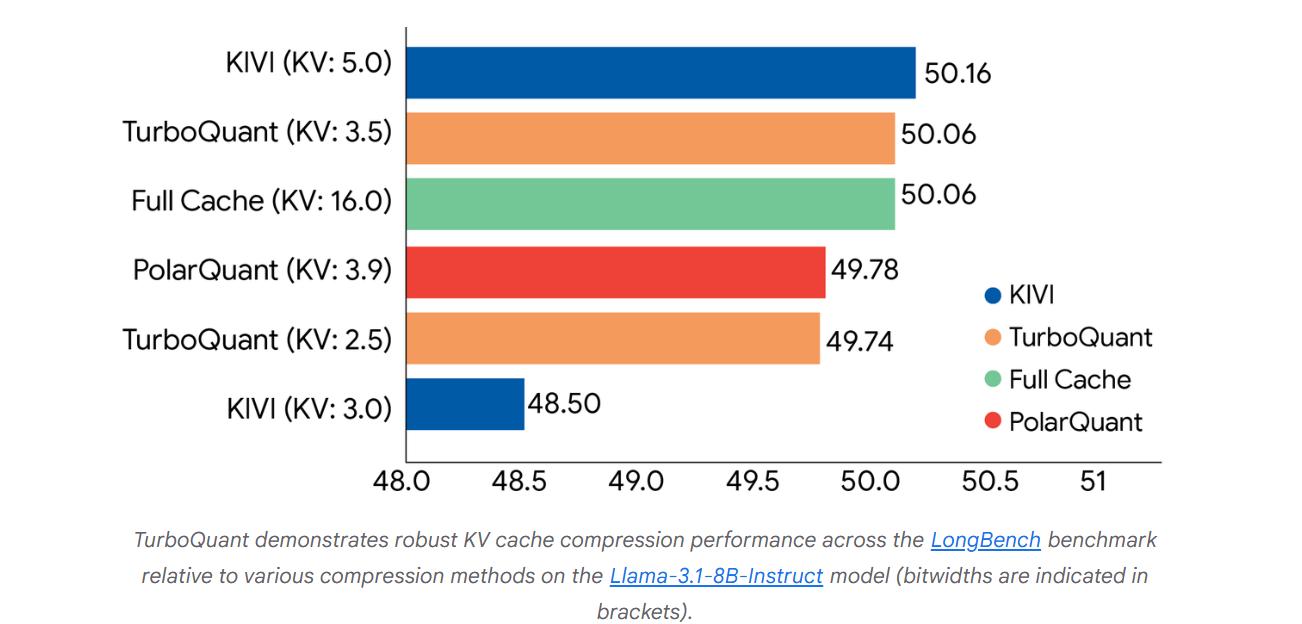
Hình trên cho thấy điểm hiệu suất toàn diện của các thuật toán cơ bản TurboQuant, PolarQuant và KIVI trong các tác vụ khác nhau như trả lời câu hỏi, tạo mã và tóm tắt.
Google cho biết TurboQuant đã đạt được kết quả hoàn hảo ở tất cả các điểm chuẩn trong khi giảm ít nhất 6 lần kích thước bộ nhớ khóa-giá trị.
Họ dự định trình bày kết quả nghiên cứu của mình tại hội nghị ICLR 2026 vào tháng tới, đồng thời trình diễn hai phương pháp để đạt được khả năng nén như vậy: phương pháp lượng tử hóa PolarQuant và phương pháp đào tạo và tối ưu hóa có tên QJL.
Google mở ra thời điểm DeepSeek?
Thuật toán này của Google khiến nhiều người liên tưởng đến công ty khởi nghiệp hư cấu Pied Piper trong loạt phim truyền hình HBO "Thung lũng Silicon" (phát sóng từ năm 2014 đến 2019). Trong loạt phim truyền hình, Pied Piper cũng đã phát triển một thuật toán nén đột phá có thể giảm đáng kể kích thước tệp bằng cách nén gần như không mất dữ liệu.
Trên thực tế, công nghệ TurboQuant do Viện nghiên cứu Google phát hành cũng cam kết đạt được khả năng nén tối đa mà không làm giảm chất lượng, nhưng nó được áp dụng vào nút thắt cốt lõi của hệ thống trí tuệ nhân tạo.
Giám đốc điều hành Cloudflare, Matthew Prince và những người khác thậm chí còn gọi đó là khoảnh khắc DeepSeek của Google, tin rằng nó được kỳ vọng, giống như DeepSeek, sẽ giảm đáng kể chi phí vận hành của AI thông qua mức tăng hiệu suất cực cao trong khi vẫn duy trì tính cạnh tranh về kết quả.
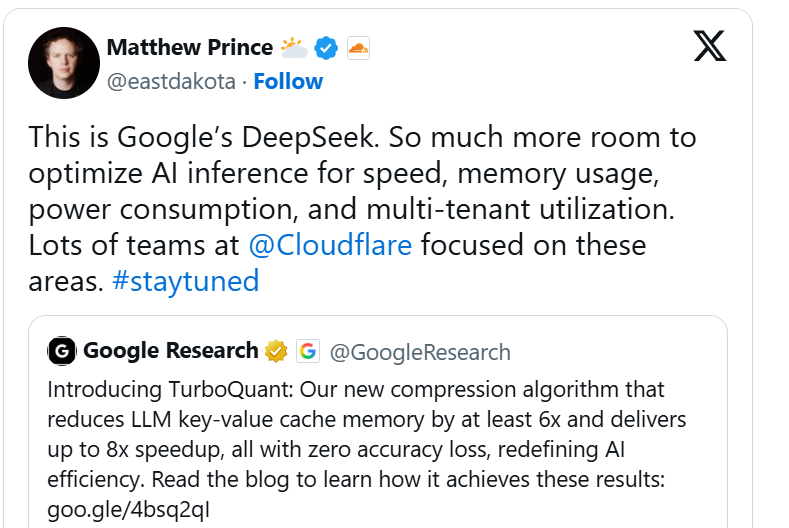
Ông đã viết trong một bài viết trên X: "Xét về tốc độ, mức sử dụng bộ nhớ, mức tiêu thụ và sử dụng điện năng, suy luận AI vẫn còn rất nhiều chỗ để tối ưu hóa".
Liệu nhu cầu chip nhớ có hạ nhiệt không?
Việc Google phát hành thuật toán này diễn ra vào thời điểm tình trạng thiếu chip bộ nhớ trên toàn cầu ngày càng trở nên nghiêm trọng.
Khi các gã khổng lồ lớn trên toàn cầu hoàn toàn cam kết xây dựng cơ sở hạ tầng AI, nhu cầu bộ nhớ tiếp tục tăng và tình trạng thiếu nguồn cung sẽ khó giảm bớt trong thời gian ngắn. Các nhà phát triển tại các công ty công nghệ lớn đã đưa ra nhiều cách sáng tạo khác nhau để khắc phục hoặc ít nhất là giải quyết tình trạng thiếu bộ nhớ và TurboQuant của Google hiện được những người trong ngành công nghệ coi là giải pháp bền vững để hạ nhiệt nhu cầu bộ nhớ.
Kỳ vọng này đương nhiên là một điều tốt đối với những gã khổng lồ công nghệ cam kết xây dựng cơ sở hạ tầng AI. Nhưng đối với các nhà sản xuất chip nhớ, kết quả có thể khác.
Bị ảnh hưởng bởi kỳ vọng rằng nhu cầu bộ nhớ có thể hạ nhiệt, thị trường chip nhớ chứng khoán của Hoa Kỳ đã lao dốc chung ngay sau khi khai trương vào thứ Tư theo giờ miền Đông: SanDisk giảm 6,5%, Micron Technology giảm 4%, Western Digital giảm hơn 4% và Seagate Technology giảm hơn 5%.
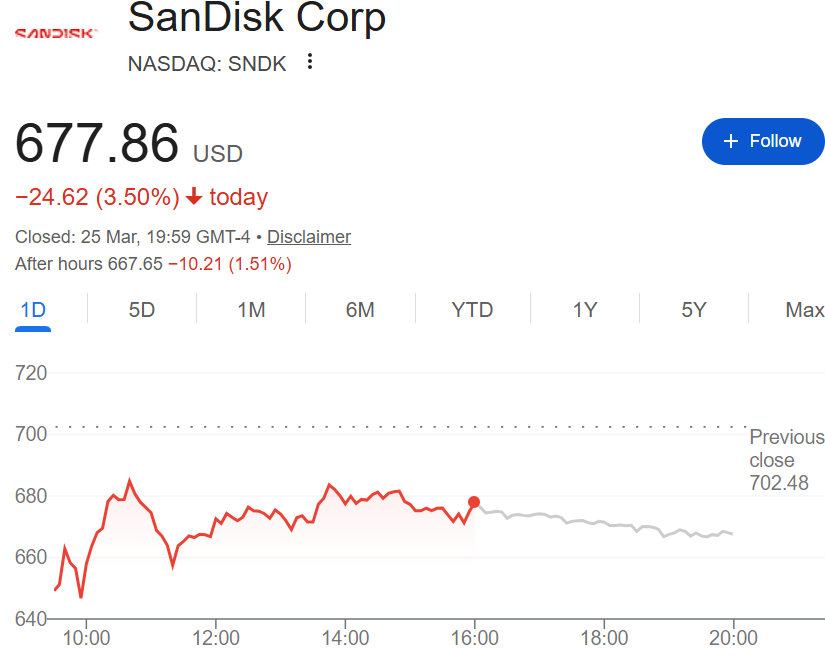
SanDisk giảm mạnh trong đầu phiên giao dịch ngày thứ Tư
Trong phiên giao dịch châu Á hôm thứ Năm, SK Hynix giảm 4,42% và Samsung giảm 3,02% tính đến thời điểm báo chí.
Shay, Futurum Equity Research Boloor tuyên bố:
“Thị trường coi đây là một trở ngại tiềm tàng đối với kho bộ nhớ vì suy luận AI ngữ cảnh dài cho mỗi nhân viên. Bộ nhớ có thể cần thiết cho khối lượng công việc giờ đây có thể bị giảm đáng kể. ”
Mount Morgan đưa ra quan điểm ngược lại
Tuy nhiên, cũng có những đại gia Phố Wall đưa ra quan điểm ngược lại.
Ví dụ, nhà phân tích KC Rajkumar của Lynx Equity Strategies cho rằng "tính đột phá" của công nghệ TurboQuant có thể không quá cường điệu như mô tả của giới truyền thông.
Ông nói rằng cái gọi là “cải thiện hiệu suất 8 lần” của Google dựa trên sự so sánh với mô hình 32-bit cũ. Tuy nhiên, mô hình suy luận hiện tại đã sử dụng rộng rãi dữ liệu lượng hóa 4 bit nên việc cải thiện hiệu suất không phải là quá đáng.
Ngoài ra, Morgan Stanley cũng chỉ ra rằng công nghệ Google TurboQuant chỉ hoạt động trên bộ nhớ đệm khóa-giá trị trong giai đoạn suy luận, không ảnh hưởng đến HBM bị trọng lượng mô hình chiếm giữ và không liên quan gì đến nhiệm vụ huấn luyện.
Vì vậy, tổng yêu cầu lưu trữ hoặc tổng phần cứng không phải là giảm 6 lần mà là sự gia tăng thông lượng GPU đơn thông qua các cải tiến về hiệu suất – cùng một phần cứng có thể hỗ trợ các bối cảnh dài hơn gấp 4 đến 8 lần hoặc tăng đáng kể kích thước lô mà không gây ra hiện tượng tràn bộ nhớ.
Quan trọng hơn, Morgan Stanley còn trích dẫn thêm "Nghịch lý Jevons" để giải thích nhận định rằng nhu cầu bộ nhớ sẽ không hạ nhiệt.
Nghịch lý Jevons là một khái niệm quan trọng trong kinh tế học, đề cập đến mối quan hệ phản trực giác giữa tiến bộ công nghệ và mức tiêu thụ tài nguyên. Định nghĩa là: khi tiến bộ công nghệ nâng cao hiệu quả, mức tiêu thụ tài nguyên không những không giảm mà còn tăng lên. Ví dụ, động cơ hơi nước cải tiến của Watt cho phép đốt than hiệu quả hơn, nhưng kết quả là nhu cầu về than tăng vọt.
Morgan Stanley tin rằng bằng cách giảm đáng kể chi phí dịch vụ của một truy vấn, TurboQuant có thể di chuyển các mô hình chỉ có thể chạy trên các cụm đắt tiền trên đám mây sang cục bộ, hạ thấp ngưỡng triển khai AI trên quy mô lớn một cách hiệu quả, điều này có thể thúc đẩy hơn nữa nhu cầu tổng thể.
Trên thực tế, DeepSeek, được CEO Cloudflare Matthew Prince và những người khác nhắc đến, là ví dụ sinh động nhất về nghịch lý Jevons: khi DeepSeek được phát hành vào đầu năm ngoái, thị trường cũng lo lắng nhu cầu về phần cứng AI sẽ hạ nhiệt. Nhưng thực tế là sự cải thiện về hiệu quả đã kéo theo sự phổ biến hơn nữa của các ứng dụng AI và nhu cầu về phần cứng AI cũng nóng lên trở lại.