Hôm qua là một "Dạ tiệc Lễ hội Mùa xuân" thực sự trong giới AI. Ngay khi báo cáo kỹ thuật của DeepSeek-V4 ra đời, nó dài gần 60 trang, bao quát mọi thứ từ kiến trúc, đào tạo cho đến hậu đào tạo. 484 ngày là điều bất thường đối với đội bóng này. V3 mất chưa đầy 8 tháng kể từ khi V2 được phát hành. Tại sao V4 mất gần gấp đôi thời gian?

Sau khi nghiên cứu kỹ lưỡng báo cáo này, chúng tôi đã phát hiện ra những lý do có thể xảy ra đằng sau nó, cũng như nền tảng kỹ thuật gây sốc của "đèn nhà" này.
Có thể nói, điều thực sự đáng suy nghĩ về DeepSeek-V4 không phải là sức mạnh tính toán mà nó tích lũy được mà là tính hợp lý và minh bạch gần như tàn nhẫn trong đào tạo đặc vụ, cơ sở kỹ thuật và xử lý "cú sốc đào tạo".
Hôm nay chúng tôi trực tiếp tháo rời mui xe của V4 để xem bên trong ẩn chứa những chi tiết cốt lõi nào.
33T Token + Hàng nghìn tỷ tham số
Độ khó trực tiếp đạt đến
Đã 484 ngày kể từ khi phát hành V3 và V4 được ra mắt dưới dạng "phiên bản xem trước".
Mặc dù khoảng thời gian này không được giải thích trong bài báo, nhưng có một đoạn có thể cung cấp manh mối.

V3 đã sử dụng 14,8T mã thông báo để đào tạo trước, V4 trực tiếp nhân đôi nó, V4-Flash được đào tạo 32T và V4-Pro được đào tạo 33T. Số lượng tham số cũng đã mở rộng đáng kể. Tổng thông số của V4-Pro là 1.6T và V4-Flash cũng có 284B.
Dữ liệu được nhân đôi, các thông số được nhân đôi và độ khó trong việc ổn định luyện tập cũng tăng lên theo một bậc độ lớn.
Báo cáo rất trung thực: DeepSeek đặt tên rõ ràng là "thử thách ổn định trong đào tạo".
Nhà nghiên cứu Susan Zhang của GoogleDeepMind khen ngợi: Cách tiếp cận minh bạch này rất đáng khen ngợi. Tuyên bố này cũng được cha đẻ của tôm hùm
chuyển tiếp trên một cụm có quy mô rất lớn, khi lượng tham số và dữ liệu huấn luyện đạt đến một điểm tới hạn nhất định, các lỗi tinh vi của phần cứng sẽ được khuếch đại vô hạn.
Trong bài báo, từ "ổn định" xuất hiện hơn mười lần.
Trong báo cáo kỹ thuật, bản thân tần số này chính là tín hiệu. Trong tình huống bình thường, ổn định là tiền đề mặc định, không đáng nhắc đi nhắc lại nhiều lần. Việc nhắc đi nhắc lại nhiều lần cho thấy nó thực sự có vấn đề.
Cụ thể, DeepSeek nhận thấy rằng các ngoại lệ số (ngoại lệ) trong lớp MoE sẽ tiếp tục khuếch đại thông qua cơ chế định tuyến, tạo thành một vòng luẩn quẩn, cuối cùng gây ra mức tổn thất tăng đột biến và đường cong đào tạo tăng vọt.
Các biện pháp khắc phục chính được nhóm đưa ra là hai chiêu thức.
Bí quyết đầu tiên là Định tuyến dự đoán. Về cơ bản, nó sử dụng các tham số phiên bản trước đó trong giai đoạn định tuyến để tách các bản cập nhật của mạng đường trục và mạng định tuyến, phá vỡ vòng luẩn quẩn giữa hai mạng.
Thủ thuật thứ hai là SwiGLU Kẹp. Nó trực tiếp kẹp phạm vi số của SwiGLU trong [-10, 10], loại bỏ các giá trị ngoại lệ khỏi nguồn, việc này mang tính bạo lực nhưng rất hiệu quả.

Chương trình đào tạo mô hình lớn hiện tại đã bước vào TA GPH115Lớp dưới cùng của phần cứng, ngăn xếp trình biên dịch và kiến trúc toán họcBộ ba không man's land
Trong bài báo có một chi tiết rất thú vị đáng để suy ngẫm.
Định tuyến dự đoán và Kẹp SwiGLU, DeepSeek xác nhận rằng chúng "có hiệu quả đáng kể", nhưng sau đó là câu "cơ chế cơ bản vẫn là một câu hỏi mở".
Ngay cả đối với việc chuẩn hóa Q/KV, một thao tác cơ bản đã được xác minh rộng rãi, từ ngữ trên báo chỉ dám viết "có thể cải thiện độ ổn định trong huấn luyện".
Từ "có thể" đủ để cho thấy rằng trong việc đào tạo MoE nghìn tỷ thông số, không có gì đáng tin cậy 100%.

Từ 15T lên 33T, việc tăng gấp đôi lượng dữ liệu không gây ra khó khăn tăng trưởng tuyến tính mà gây ra rủi ro hệ thống theo cấp số nhân.
Mọi lớp mạng, mọi cập nhật độ dốc và mọi đồng bộ hóa truyền thông đều được khuếch đại thành các điểm sụp đổ tiềm ẩn ở quy mô lớn hơn.
DeepSeek đã chọn viết tất cả những điều này lên báo, một điều gần như chưa có tiền lệ trong ngành.
Đó là phần cứng hay phần mềm?
Vậy phần cứng của ai là “thách thức về độ ổn định trong luyện tập” được đề cập rõ ràng trong báo cáo kỹ thuật?
Mặc dù bài báo không nêu tên rõ ràng bất kỳ nền tảng phần cứng nào, nhưng một số người có khứu giác nhạy bén đã bắt đầu suy đoán.
Một số người trực tiếp chỉ ra rằng cái gọi là “thách thức về độ ổn định trong đào tạo” có thể là một vấn đề với nền tảng sức mạnh tính toán. Và không chỉ DeepSeek gặp phải cạm bẫy này mà tất cả các nhà sản xuất lớn đều gặp phải.
xAI Tại một cuộc họp báo, người phụ trách dự án Macrohard đã đề cập một cách mơ hồ rằng những con chip mới nhất của Nvidia đã khiến họ “rất rắc rối” và họ phải phát triển lại chương trình thích ứng phần cứng. Điều này cũng có thể giải thích một trong những lý do khiến tiến độ xAI bị chậm lại đột ngột.
Tuy nhiên, tất nhiên, vấn đề này không đơn giản như vậy.
Có quá nhiều biến số liên quan đến các cụm điện toán quy mô lớn: bản thân chip, kiến trúc kết nối, hệ thống làm mát, nguồn điện, phiên bản trình điều khiển và khả năng thích ứng ngăn xếp biên dịch. Sự không ổn định trong quá trình đào tạo không nhất thiết có nghĩa là lỗi ở cấp độ chip mà còn có thể là sự cố ở lớp tích hợp hệ thống.
Tuy nhiên, vẫn chưa có văn bản chính thức nào đưa ra câu trả lời.
Mọi thứ vẫn đang trong giai đoạn đoán mò.

Hệ thống đào tạo đại lý
4Khả năng kỹ thuật thật đáng kinh ngạcNếu quá trình đào tạo trước của V4 đang cạnh tranh với phần cứng thì Đào tạo sau của nó thể hiện tính thẩm mỹ kỹ thuật ở cấp độ sách giáo khoa.
Có thể nói rằng lộ trình kỹ thuật về khả năng của Tác nhân là đáng được đọc kỹ nhất trong bài báo V4.
Trước đây, chúng tôi nghĩ rằng khả năng của Đặc vụ là được "dạy", nhưng DeepSeek tin rằng khả năng của Đặc vụ phải được "phát triển".

Từ chối "di cư cứng", "Truyền máu" trong giai đoạn trước đào tạo
Hầu hết các phương pháp thực hành trong ngành trước tiên là đào tạo mô hình đối thoại và sau đó di chuyển cứng mô hình đó vào Tác nhân. Theo DeepSeek, điều này quá kém hiệu quả.
Trong giai đoạn giữa quá trình huấn luyện của V4, họ đã tiêm một lượng lớn Dữ liệu Tác nhân.
Điều này có nghĩa là mô hình đã thấy các chuỗi nhiệm vụ dài, phản hồi môi trường và các chế độ sửa đổi tệp trong giai đoạn học cơ bản. Trước khi nó học viết thơ, nó đã thấy lỗi từ dòng lệnh Linux.
Đây là thiết kế ở cấp độ nền tảng.
Đào tạo chuyên gia gốc
Một điểm nổi bật khác là phương pháp Đào tạo chuyên gia ban đầu của DeepSeek.
V4 không trực tiếp đào tạo một chiến binh toàn diện mà lần đầu tiên đào tạo một chuyên gia toán học, một chuyên gia mật mã, một chuyên gia đặc vụ và một chuyên gia tuân theo chỉ dẫn.
Đào tạo Chuyên gia theo giai đoạn này đảm bảo rằng giới hạn trên của từng lĩnh vực được kéo dài đến mức cao nhất.
Cuối cùng, thông qua OPD (Chưng cất chính sách nhiều giáo viên, chắt lọc chính sách trực tuyến nhiều giáo viên), tâm hồn của những chuyên gia này được tổng hợp thành một mô hình thống nhất.
Khó khăn về mặt kỹ thuật ở đây là việc tải hơn mười nghìn tỷ mô hình giáo viên cấp tham số cùng lúc để suy luận trực tuyến là không thực tế.
V4 giải pháp không phải là lưu nhật ký của giáo viên vào bộ nhớ đệm (bộ nhớ video không thể chứa vừa trong đó) mà chỉ lưu vào bộ nhớ đệm trạng thái ẩn của lớp cuối cùng của giáo viên và xây dựng lại nhật ký thông qua đầu dự đoán theo yêu cầu trong quá trình đào tạo.
Sau đó, sắp xếp các mẫu đào tạo theo chỉ mục giáo viên, đảm bảo rằng đầu dự đoán của mỗi giáo viên chỉ được tải một lần. Tính toán phân kỳ KL được tăng tốc bằng cách sử dụng hạt nhân chuyên dụng được viết bằng TileLang.
Tạm biệt Mô hình Phần thưởng truyền thống
Ngoài ra, đối với các nhiệm vụ “khó xác minh”, Mô hình Phần thưởng Vô hướng truyền thống không còn phù hợp nữa.
Về vấn đề này, DeepSeek đã chọn giới thiệu Mô hình phần thưởng sáng tạo (GRM).
Nó không còn đơn giản cho điểm từ 0 đến 1 nữa mà tạo báo cáo đánh giá chi tiết dựa trên Thang đánh giá đặt trước (tiêu chí đánh giá).
Quan trọng hơn, DeepSeek cũng đã thực hiện tối ưu hóa RL trên chính GRM, cho phép mạng tác nhân hoạt động như một mô hình phần thưởng tổng quát cùng một lúc, đồng thời khả năng phán đoán và khả năng tạo được cùng tối ưu hóa trong cùng một mô hình.

Biến Đại lý thành một đại lý được phân phối system
Không chỉ vậy, DeepSeek còn phát triển một bộ đế dành riêng cho V4.
DSec: Cụm hộp cát cấp sản xuất
Để đào tạo khả năng thực tế của Đặc vụ, DeepSeek đã xây dựng một nền tảng có tên DSec.
Hệ thống tệp phân tán 3FS đảm bảo truy cập dữ liệu cực nhanh; Hàng trăm nghìn phiên bản Sandbox đồng thời có nghĩa là khi V4 đang huấn luyện, có hàng trăm nghìn "máy tính ảo" chạy mã và kiểm tra lỗi cùng một lúc.
MegaMoE: Truyền thông và điện toán tích hợp
Ở lớp MoE, DeepSeek tích hợp truyền thông và điện toán vào một hạt nhân đường dẫn duy nhất. Các chuyên gia lên lịch theo sóng, độ trễ liên lạc hoàn toàn được ẩn dưới tính toán.
Kết quả là các cảnh chung được tăng tốc từ 1,5 đến 1,73 lần và các cảnh nhạy cảm với độ trễ như triển khai RL được tăng tốc lên tới 1,96 lần.
DSML tự phát triển: Từ chối thoát khỏi thất bại
Về mặt gọi công cụ, DeepSeek chỉ đơn giản thiết kế một bộ DSL giống như XML (ngôn ngữ dành riêng cho miền).
Giao thức này đơn giản và hiệu quả, đồng thời trực tiếp cải thiện tỷ lệ thành công của các lệnh gọi công cụ từ "phụ thuộc vào may mắn" thành "mạnh mẽ ở cấp độ công nghiệp".

Đào tạo chế độ phụ Nỗ lực lý luận
Ngoài ra còn có một thiết kế tinh tế, tức là V4 hỗ trợ các chế độ tư duy khác nhau.
Chế độ không suy nghĩ là lựa chọn công cụ đơn giản với phản hồi vài giây. High/Max nhắm đến các tài liệu dài, việc tái cấu trúc và các lỗi phức tạp, tối đa hóa sức mạnh tính toán suy luận.
Chiến lược “tiết kiệm tiền khi có thể và tàn nhẫn khi cần thiết” cũng là chìa khóa giúp giá thành của V4 đạt 1/4 Claude.
Sau khi đọc phần này, nhiều nhà nghiên cứu trong cộng đồng đã rất ấn tượng đến nỗi họ nói: "Năng lực kỹ thuật của DeepSeek vẫn vững chắc đến mức khiến mọi người không nói nên lời".

Suy nghĩ xen kẽNâng cấp
V3.2 sẽ loại bỏ dấu vết suy nghĩ trước đó khi mỗi tin nhắn mới của người dùng đến. V4 lưu giữ lịch sử lý luận xuyên suốt hoàn chỉnh trong kịch bản Gọi công cụ, cho phép Tác nhân duy trì chuỗi lý luận mạch lạc trong các nhiệm vụ dài hạn.
Các cảnh đối thoại thông thường vẫn được xóa qua mỗi hiệp để giữ cho bối cảnh được sắp xếp hợp lý.
Mặt khác của đồng tiền là tỷ lệ ảo ảnh 94%
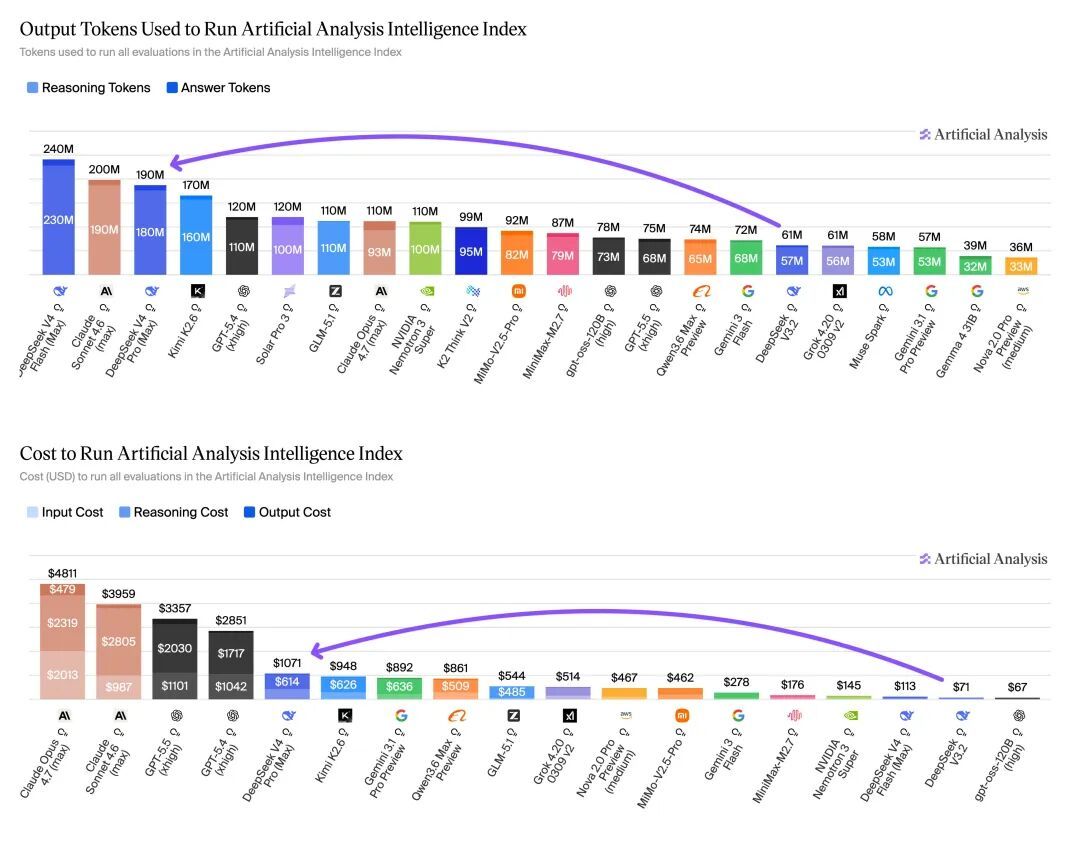
Phép đo thực tế của Phân tích nhân tạo mang lại hình ảnh ba chiều hơn.
Sau khi chạy thử nghiệm điểm chuẩn Intelligence Index đầy đủ, V4 Pro chỉ có giá 1.071 đô la Mỹ, rẻ hơn bốn lần so với 4.811 đô la Mỹ của Claude Opus 4.7.
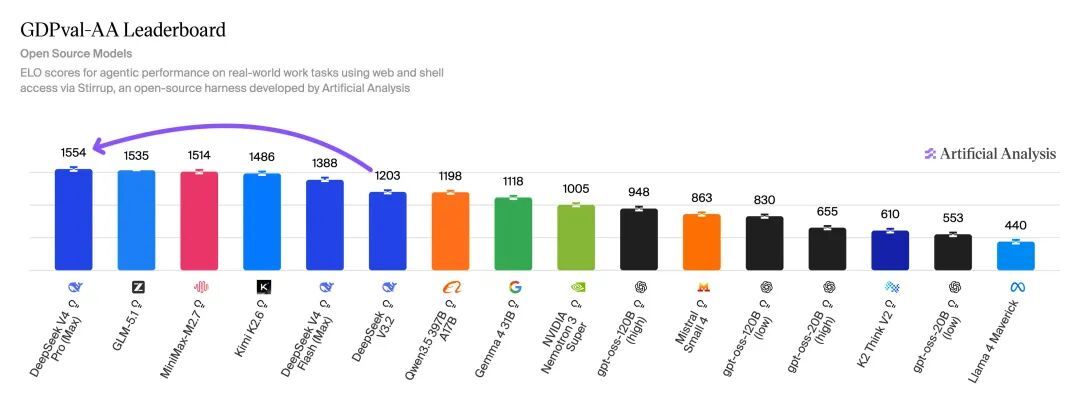
Về khả năng của Tác nhân, V4 Pro Max đạt 1554 điểm trong bài kiểm tra thực tế GDPval-AA (Điểm chuẩn của Tác nhân cho các nhiệm vụ công việc thực tế), vượt trội toàn diện so với nhiều mẫu mã nguồn mở.
Tuy nhiên, không có bữa trưa miễn phí. Báo cáo của
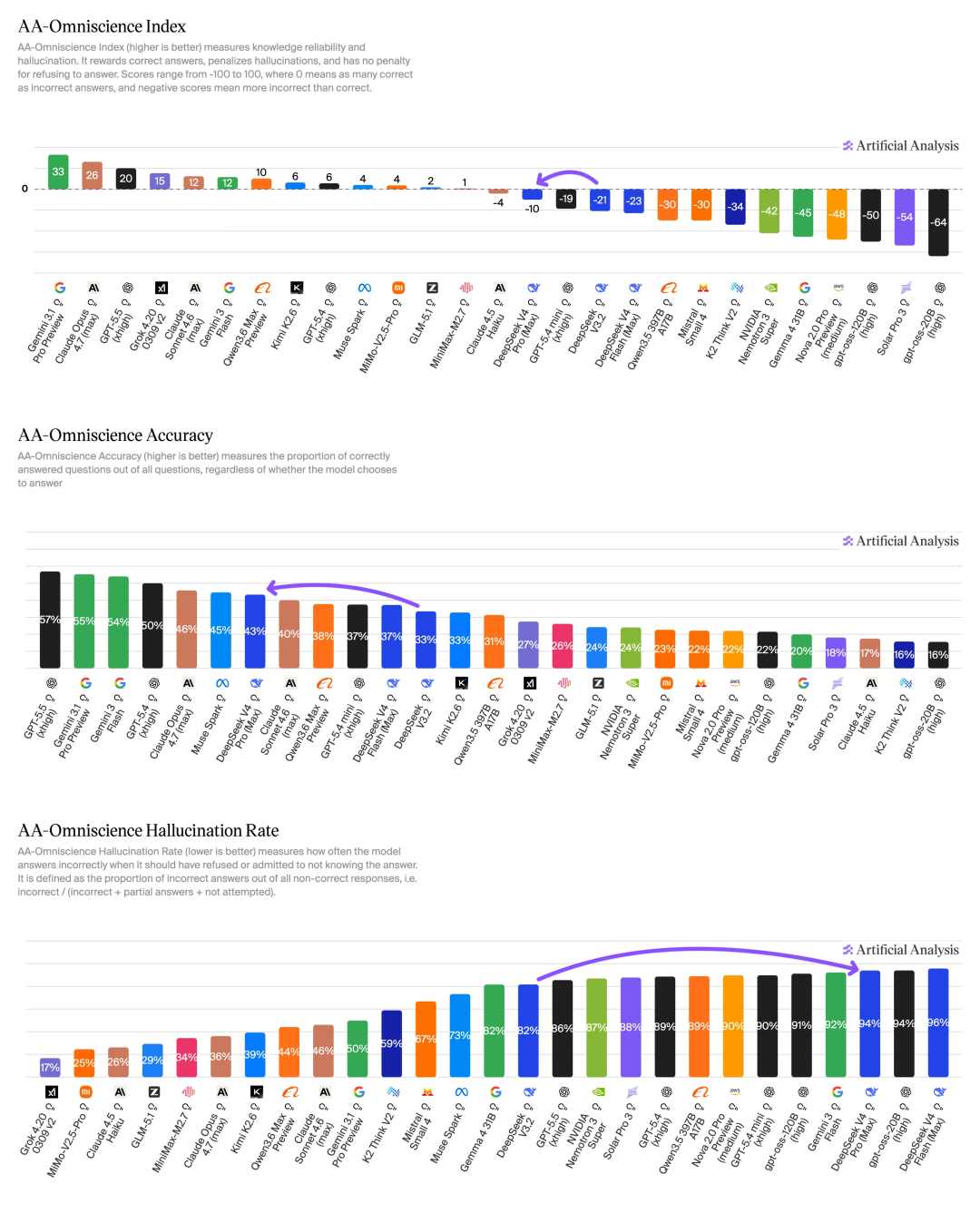
Aritificial Analysis' cũng chỉ ra chi phí của phương pháp này một cách rất thẳng thắn: tỷ lệ ảo giác của V4 pro trên AA-Ominiscience cao tới 94%.

Điều này cho thấy một vấn đề nan giải về cấu trúc: để đạt được hiệu suất cao nhất với ngân sách sức mạnh tính toán hạn chế, bạn phải đánh đổi ở một số kích thước nhất định.
DeepSeek đã chọn đặt tất cả các chip của mình vào khả năng suy luận và tác nhân. Cái giá là sự chính xác của kiến thức.
Tại sao chúng ta vẫn tôn trọng DeepSeek?
Trong báo cáo V4 này, một số người nhìn thấy sự xấu hổ của việc "huấn luyện không ổn định", và một số nhìn thấy những khuyết điểm của "ảo giác nghiêm trọng".
Nhưng theo quan điểm của chúng tôi, khía cạnh ấn tượng nhất của báo cáo này là tính minh bạch của nó.
Họ dám thừa nhận nỗi đau của việc thích ứng phần cứng, dám tiết lộ các giải pháp trông giống như "bản vá" và thậm chí dám cho thấy cách họ sử dụng khả năng kỹ thuật cốt lõi nhất của mình để mài giũa linh hồn của Đặc vụ từng chút một trong hàng trăm nghìn hộp cát.
Tiềm ẩn nhiều đầu từ V3 Chú ý đến quá trình chưng cất OPD và hộp cát DSec của V4, DeepSeek đang sử dụng một "kỹ thuật" gần như hoang tưởng để khám phá một con đường khác từ mô hình lớn đến AGI -
Nếu kiến trúc chưa hoàn hảo, hãy sử dụng kỹ thuật để xây dựng những bức tường dày hơn; nếu sức mạnh tính toán không đủ rẻ thì hãy sử dụng các thuật toán để tận dụng hiệu quả.
DeepSeek-V4 có thể không phải là cái kết hoàn hảo nhất, nhưng nó chắc chắn là "bối cảnh AI Trung Quốc" chân thực và năng động nhất hiện nay.