Vào ngày 23 tháng 4, OpenAI đã phát hành mẫu hàng đầu GPT-5.5 thế hệ mới và viết trên trang web chính thức của mình rằng đây là mẫu thông minh nhất, trực quan nhất và dễ sử dụng nhất cho đến nay và đây cũng là bước tiếp theo trong cách hoàn thành công việc mới trên máy tính. Bản phát hành này nhanh chóng thu hút sự chú ý của ngành, không chỉ vì nó tuyên bố sẽ đạt được bước đột phá trong nhiệm vụ tác nhân thông minh mà còn vì “sự thống trị” của nó được thể hiện trong nhiều bài kiểm tra điểm chuẩn.
Theo cơ quan đánh giá bên thứ ba Artificial Trong danh sách chỉ số trí tuệ toàn diện do Analysis công bố, OpenAI chiếm bốn trong số sáu vị trí hàng đầu với dòng GPT-5.5. Cơ quan này tin rằng "GPT-5.5 đã cho phép OpenAI trở lại vị trí đầu tiên trong lĩnh vực AI, phá vỡ mối ràng buộc tay ba với Anthropic và Google."
Nhưng thứ được phơi bày cùng với hiệu suất cao là tỷ lệ ảo giác cao. Trong điểm chuẩn riêng AA-Omniscience của Phân tích nhân tạo, tỷ lệ ảo giác của GPT-5.5 cao tới 86%, cao hơn nhiều so với 36% của Claude Opus 4.7.
Điều này có nghĩa là khi bộ não AI “thông minh nhất” hiện tại phải đối mặt với một vấn đề không chắc chắn hoặc chưa biết, thì xác suất chọn “tự tin không biết” là cực kỳ thấp và nó có nhiều khả năng “tự tin bịa đặt” ra câu trả lời. Một khi tỷ lệ ảo giác cao này được đặt vào một kịch bản công việc đòi hỏi độ tin cậy cao, nó có khả năng dẫn đến sai lệch phân tích, sai sót khi đưa ra quyết định và thậm chí là tổn thất tài chính.
AI mạnh nhất cũng là kẻ “nói dối” nguy hiểm nhất? Đối mặt với tỷ lệ ảo giác cao, liệu GPT-5.5 có thể hoàn thành các nhiệm vụ kiến thức phức tạp trong các ứng dụng thực tế một cách đáng tin cậy không? Để trả lời những câu hỏi quan trọng này, chúng tôi đã tiến hành thử nghiệm thực tế trên GPT-5.5, từ xử lý sổ cái hộ gia đình đến viết trò chơi chiến đấu thời gian thực, để kiểm tra công việc kiến thức và khả năng lập trình của GPT-5.5 trong việc xử lý các bối cảnh dài và logic phức tạp.
Thử nghiệm này không chỉ về hiệu suất của một mô hình mà còn về cách chúng ta có thể tận dụng các khả năng mạnh mẽ của nó trong khi xử lý các rủi ro tiềm ẩn sau khi công nghệ AI đi vào vùng nước sâu.
01. Năng lực kiến thức: Nó thực sự biết cách làm việc như một người làm việc
Theo kết quả kiểm tra điểm chuẩn chính thức, GPT-5.5 đã vượt qua GPT-5.4 thế hệ trước ở hầu hết các chỉ số cốt lõi và hiệu suất của nó đặc biệt nổi bật trong lĩnh vực công việc tri thức.
Trong bài kiểm tra GDPval bao gồm 44 ngành nghề, GPT-5.5 đạt được số điểm 84,9%, không chỉ vượt mức 83,0% của nhân sự tại nơi làm việc thực tế mà còn cao hơn 80,3% của Claude Opus 4.7 và 67,3% của Gemini 3.1 Pro. Bài kiểm tra mô phỏng công việc hàng ngày của nhiều ngành nghề cổ trắng khác nhau như nhà phân tích tài chính, quản lý thị trường và kỹ sư phần mềm, đồng thời yêu cầu mô hình hoàn thành các nhiệm vụ toàn diện như tích hợp thông tin, lý luận phân tích, đề xuất ra quyết định và tạo báo cáo.
Ngoài ra, GPT-5.5 còn hoạt động tốt trong các thử nghiệm ở nhiều tình huống thực tế khác. Trong thử nghiệm mô phỏng các cuộc trò chuyện phức tạp về dịch vụ khách hàng, nó có thể đạt độ chính xác 98,0% mà không cần hướng dẫn đặc biệt; trong bài kiểm tra cho phép AI vận hành máy tính hoàn thành nhiệm vụ như người thật, nó đạt 78,7%; trong bài kiểm tra yêu cầu sự kết hợp giữa hiểu biết hình ảnh, văn bản và sử dụng các công cụ để giải quyết vấn đề, nó đạt được số điểm lần lượt là 83,2% và 75,3%. Những kết quả này cho thấy GPT-5.5 đang dần mở ra hàng loạt khả năng như “nhìn, nói và làm”.
OpenAI cũng sử dụng các trường hợp thực tế nội bộ để chứng minh giá trị năng suất của mình. Nhóm tài chính của nó đã sử dụng nó để xem xét 24.771 biểu mẫu thuế K-1, tổng cộng 71.637 trang tài liệu và cho biết quá trình này đã hoàn thành sớm hơn hai tuần so với năm trước. Điều này cho thấy GPT-5.5 là một công cụ năng suất có thể được tích hợp trực tiếp vào quy trình làm việc và nâng cao hiệu quả một cách hiệu quả.
Những khả năng này hoạt động như thế nào trong đời thực? Chúng tôi đã thiết kế một cuộc thử nghiệm gần nhà để xác minh.
Chúng tôi đã cung cấp cho GPT-5.5 nhiều phần dữ liệu chi tiêu trong một tháng ở định dạng lộn xộn và yêu cầu nó hoạt động như một nhà phân tích dữ liệu gia đình, hoàn thành các nhiệm vụ như sắp xếp dữ liệu, tính toán tổng chi tiêu, phân tích tỷ lệ của từng phương thức thanh toán, phân loại chi tiêu và cuối cùng tạo báo cáo đề xuất cho các thành viên gia đình.
Mặc dù kịch bản thử nghiệm này được thiết kế đơn giản nhưng nó có thể cho thấy rõ liệu AI có thực sự “dễ sử dụng” hay không. Kế toán hộ gia đình là công việc thường ngày của nhiều người nhưng sổ sách thường được viết tay và lộn xộn. Dữ liệu kế toán “lộn xộn” đòi hỏi AI không chỉ xử lý các bảng biểu gọn gàng mà còn phải “đọc” hồ sơ viết tay, hiểu ý nghĩa của từng số tiền và nhóm các mục tương tự lại với nhau.
Tính toán sổ cái chung, phân tích tiền được chi tiêu vào đâu và đưa ra đề xuất tiết kiệm thực sự tương ứng với một bộ quy trình tư duy hoàn chỉnh. GPT-5.5 trước tiên cần phải sắp xếp thông tin, sau đó xem manh mối từ đó, đề xuất các phương pháp khả thi và cuối cùng để nó "viết báo cáo", yêu cầu nó báo cáo công việc của mình theo cách mà mọi người có thể hiểu và chấp nhận.
Kết quả kiểm tra cho thấy nó kết hợp chính xác giữa "bữa trưa mang đi" và "bữa tối mang đi", đồng thời chủ động nhắc rằng "khấu trừ tự động Alipay" nên được đưa vào thống kê "Alipay", thể hiện khả năng hiểu các tài khoản khó hiểu và ý định thực sự của người dùng.
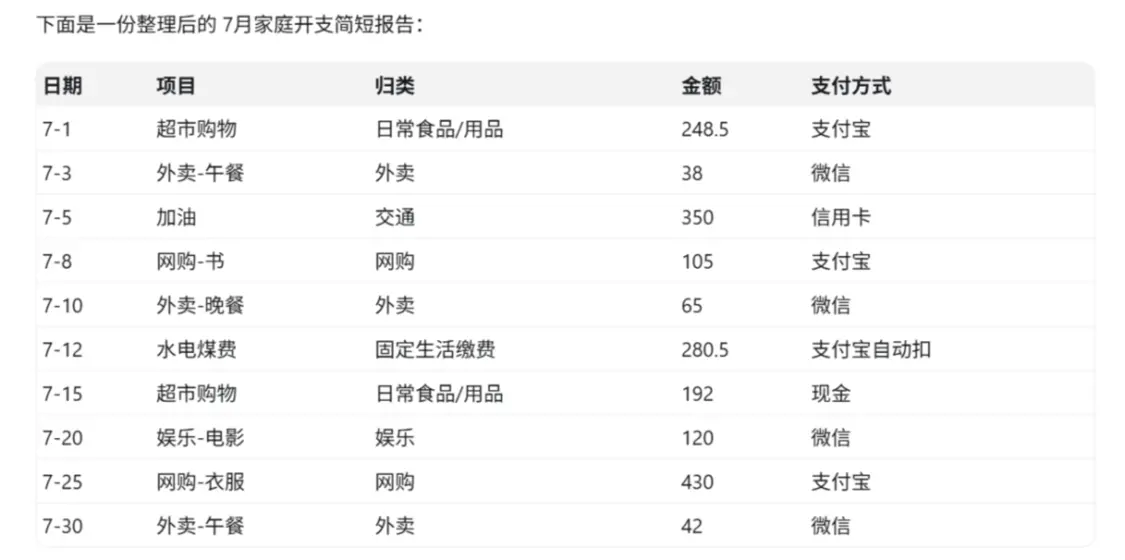

GPT-5.5 vì Phần chính tổ chức bảng và cung cấp phân tích
Trong phân tích, nó tính toán tỷ lệ và chỉ ra rằng chi tiêu của danh mục "mua sắm trực tuyến" (quần áo, sách) tương đối cao và hầu hết trong số đó là nguồn cung cấp không khẩn cấp. Vì vậy, nên lập ngân sách cho loại hình tiêu dùng này và những đề xuất đưa ra phải cụ thể, khả thi. Báo cáo cuối cùng được tạo ra cũng chứa đầy sự liên quan của con người. Câu “Nếu bạn kiềm chế được ham muốn mua sắm trực tuyến của mình một chút thì chi tiêu của gia đình chúng ta sẽ dễ dàng hơn”. Nó đáp ứng yêu cầu giao tiếp “cho gia đình bạn xem”. Giọng điệu thân mật và nên thực tế.
Thử nghiệm đơn giản này tương đương với việc khôi phục các khả năng cốt lõi được kiểm tra bằng thử nghiệm GDPval nêu trên trong các tình huống trong cuộc sống. Kết quả hiện tại cũng cho thấy năng lực chuyên môn của nó có thể được ứng dụng vào đời sống thực tế.
02. Khả năng lập trình: từ cơ bản đến phức tạp, không gây nhầm lẫn
Ngoài hiệu suất đáng tin cậy trong các nhiệm vụ kiến thức hàng ngày, GPT-5.5 còn cho thấy sự tiến bộ tốt về các "kỹ năng cứng" như lập trình đòi hỏi độ chính xác cao hơn.
Trong bài kiểm tra điểm chuẩn (Terminal-Bench 2.0) dành cho "tác nhân thông minh", nó đã đạt được số điểm cao là 82,7%. Thử nghiệm này mô phỏng việc thực hiện một loạt thao tác phức tạp trên dòng lệnh, giống như việc để AI tự mình hoàn thành nhiệm vụ vận hành và bảo trì gồm nhiều bước. Điểm số của nó không chỉ cao hơn thế hệ trước (75,1% GPT-5.4) mà còn vượt trội đáng kể so với đối thủ Claude Opus 4.7 (69,4%). Điều này cho thấy nó hoạt động tốt hơn khi bạn cần ghi nhớ các bước, tự gỡ lỗi và kiên trì hoàn thành các nhiệm vụ dài hạn.
Thứ hai, cũng có những cải tiến trong việc xử lý nội dung rất dài. Trong thử nghiệm truy xuất các văn bản rất dài từ 500.000 đến 1 triệu ký tự, nó đạt 74,0%, cao hơn gấp đôi so với thế hệ trước (36,6%). Điều này có nghĩa là khi được yêu cầu phân tích một cuốn sách dày hoặc duyệt qua kho mã khổng lồ, nó sẽ ít có khả năng “nhớ” hoặc “nhớ sai”, tìm kiếm thông tin chính xác hơn và có ý tưởng mạch lạc hơn.
Và nhiều kết quả thử nghiệm cho thấy rằng khi thực hiện cùng một tác vụ lập trình, GPT-5.5 tiêu thụ mã thông báo ít hơn đáng kể so với GPT-5.4. Ngay cả Michael Truell, đồng sáng lập của trình soạn thảo mã Cursor, cũng nhận xét rằng nó thông minh hơn và linh hoạt hơn thế hệ trước, có thể gọi các công cụ đáng tin cậy hơn và có thể tồn tại lâu hơn khi đối mặt với các tác vụ phức tạp và dài hạn.
Nói một cách đơn giản, trong các kịch bản vận hành phức tạp như lập trình, dữ liệu trên cho thấy GPT-5.5 không chỉ mạnh hơn mà còn ổn định hơn, tiết kiệm tài nguyên hơn, đồng thời phù hợp để xử lý các tác vụ phát triển thực tế có nhiều bước và mất nhiều thời gian.
Để xác minh khả năng lập trình thực sự của nó, chúng tôi đã thử nghiệm nó với một nhiệm vụ phát triển cụ thể, xây dựng và nâng cấp dần dần trò chơi Lianliankan từ đầu và quy định rằng trò chơi phải sử dụng 12 biểu thức biểu tượng cảm xúc khác nhau được cung cấp.
Đầu tiên, chúng tôi để GPT-5.5 tạo ra một trò chơi Lianliankan hoàn chỉnh và có thể chạy được.
Điều này yêu cầu nó phải hiểu nhu cầu văn bản của nhà phát triển, thiết kế giao diện, quản lý trạng thái trò chơi và triển khai độc lập thuật toán tìm kiếm đường dẫn cốt lõi. Hóa ra nó được thực hiện trong vài phút.

GPT- Lianliankan mini-game được tạo trong 5.5
Tiếp theo, chúng tôi tăng độ khó và yêu cầu nó thêm phụ kiện "vẽ lại" vào trò chơi.
Chức năng của đạo cụ này là: khi người chơi sử dụng nó, nó có thể tiêu thụ năng lượng "kết hợp" và làm mới ngẫu nhiên tất cả các biểu tượng trên bảng cùng loại với lần trước chúng bị loại.
Để đạt được điều này, GPT-5.5 phải thực hiện hai việc. Một là sửa đổi các quy tắc dữ liệu đằng sau trò chơi để hỗ trợ tính năng mới này; hai là để đảm bảo rằng bố cục bảng được làm mới vẫn có thể "giải quyết được" và không để người chơi bị mắc kẹt. Cuối cùng, GPT-5.5 đã viết thành công phần mã này. Sau
, chúng tôi tiếp tục cho phép nó thêm hệ thống người dùng hoàn chỉnh vào trò chơi, bao gồm đăng nhập, ghi điểm và hiển thị xếp hạng.
Thử nghiệm chính của bước này là liệu GPT-5.5 có thể tích hợp trơn tru các chức năng mới vào khung hiện có hay không, đồng thời duy trì lối chơi cốt lõi và logic của trò chơi mà không bị phá hủy.
Một lần nữa, nó đã hoàn thành xuất sắc nhiệm vụ và thể hiện sự hạn chế đáng kể trong quá trình lặp lại mã mà không cần tái cấu trúc quá mức hoặc đưa ra những thay đổi không cần thiết.
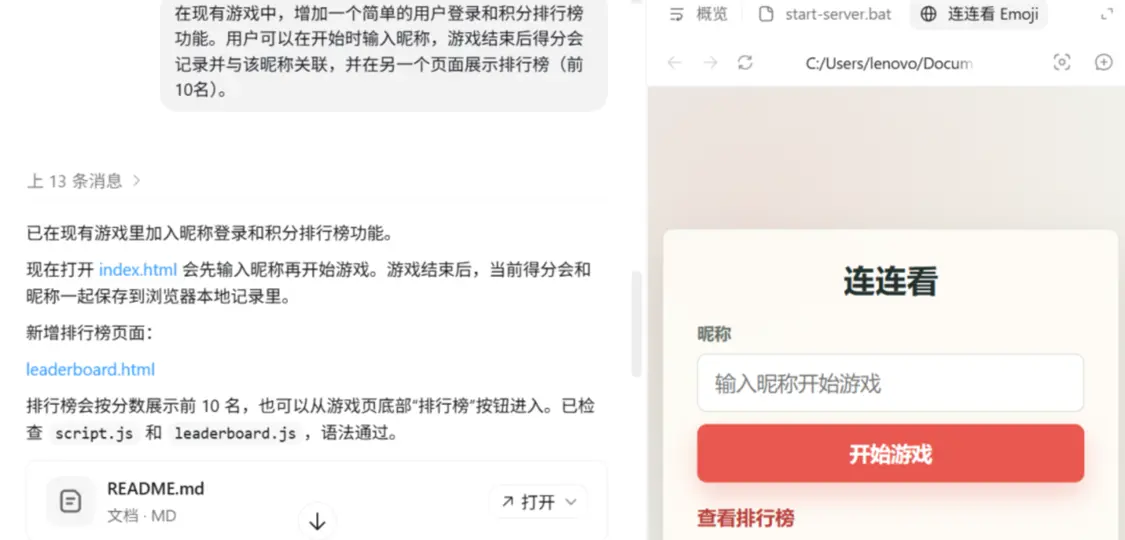
GPT-5.5 thực hiện hướng dẫn điều chỉnh chi tiết trò chơi
Cuối cùng, chúng tôi đẩy độ khó lên cấp độ cao hơn của chế độ chiến đấu thời gian thực, cho phép hai người chơi cạnh tranh loại trừ thời gian thực trên các trình duyệt khác nhau.
Điều này liên quan đến một loạt sự cố trực tuyến nhiều người chơi điển hình như đồng bộ hóa trạng thái bàn cờ, giải quyết xung đột hoạt động và xử lý độ trễ mạng. Đối mặt với thách thức phức tạp như vậy với khả năng tích hợp cao và hiệu suất thời gian thực mạnh mẽ, GPT-5.5 vẫn đạt được khả năng phân phối chính xác.
Thử nghiệm từ đơn giản đến phức tạp này cho thấy GPT-5.5 không chỉ có thể xử lý thiết kế kiến trúc và logic phức tạp trong các tác vụ lập trình thực mà còn đáp ứng chính xác nhu cầu của nhà phát triển và không tùy ý tái cấu trúc hoặc giới thiệu mã khác. Ngay cả khi chúng tôi yêu cầu quay lại phiên bản trước, nó vẫn có thể khôi phục ổn định về trạng thái trước đó.
03. Tỷ lệ ảo giác cao: dùng được nhưng không dám buông
Mặc dù có hiệu suất đáng kinh ngạc trong các thử nghiệm thực tế, kết hợp với dữ liệu công khai, GPT-5.5 vẫn không vượt quá mong đợi của thị trường và có những rủi ro không thể bỏ qua.
Hãy xem một tập hợp dữ liệu so sánh.
Trong điểm chuẩn riêng AA-Omniscience của Phân tích nhân tạo, tỷ lệ ảo giác của GPT-5.5 cao tới 86%, trong khi Claude Opus 4.7 chỉ là 36%. Điều này có nghĩa là trong kịch bản do thử nghiệm này đặt ra, được thiết kế đặc biệt để phát hiện ranh giới của kiến thức mô hình, khi GPT-5.5 đối mặt với một câu trả lời không chắc chắn, xác suất "thú nhận không biết" của nó thấp hơn nhiều so với đối thủ và nó có xu hướng tạo ra một câu trả lời có thể sai.
Cần lưu ý rằng 86% này không có nghĩa là mô hình sẽ gây ảo giác trong hầu hết các câu hỏi và câu trả lời hàng ngày mà là xu hướng hành vi cụ thể của nó khi chạm vào điểm mù kiến thức. Một học viên giải thích rằng điều này có thể là do GPT-5.5 có phạm vi bao phủ kiến thức thực tế mạnh hơn, nhưng mức độ không chắc chắn cũng cao hơn và mọi người sẽ đoán câu trả lời cho những câu hỏi không chắc chắn. Tuy nhiên, chỉ báo này vẫn đòi hỏi sự thận trọng cao khi sử dụng cho những công việc đòi hỏi độ tin cậy cao.
Xu hướng ảo giác cao này có thể gây rủi ro khi GPT-5.5 được triển khai trong các tình huống "làm việc tự chủ".
Ví dụ: trong nhiệm vụ phân tích dữ liệu và tạo báo cáo, nó có thể tự tin trích dẫn dữ liệu không tồn tại, bịa đặt xu hướng thống kê hoặc đưa ra đề xuất ra quyết định dựa trên thông tin sai lệch, khiến người dùng đưa ra những đánh giá kinh doanh sai lệch so với thực tế. Trong quá trình lập trình và gỡ lỗi, giải pháp mã mà nó cung cấp có thể trông hợp lý nhưng có thể không chạy hoặc thậm chí che giấu các lỗ hổng bảo mật, làm tăng đáng kể chi phí cho việc điều tra và sửa chữa sau này.
Hơn nữa, những ảo giác như vậy thường được trình bày dưới hình thức rất tự tin và nhất quán về mặt logic. Đối với những người dùng thiếu kiến thức chuyên môn phù hợp, loại kết quả đầu ra "xác định" này cực kỳ lừa đảo và đòi hỏi sự cảnh giác cao độ.
Ngoài những lo ngại về kỹ thuật, chiến lược kinh doanh lần này của OpenAI còn bộc lộ ý định rõ ràng: đầu tiên sử dụng hệ sinh thái để khóa người dùng, sau đó dùng việc tăng giá để thu hoạch thị trường.
Một mặt, GPT-5.5 đã không mở API vào cùng thời điểm khi nó được phát hành lần đầu tiên. Nó chỉ được sử dụng bởi ChatGPT và Codex của riêng nó, ban đầu khóa người dùng vào hệ sinh thái ứng dụng của nó. Mặt khác, giá của GPT-5.5 đã tăng đáng kể so với thế hệ trước. Theo dữ liệu chính thức, GPT-5.5 tính phí 5 USD cho đầu vào và 30 USD cho đầu ra cho mỗi 1 triệu mã thông báo được xử lý. Giá đầu vào và đầu ra của GPT-5.4 thế hệ trước lần lượt là 2,5 USD và 15 USD, nghĩa là giá của thế hệ mới đã trực tiếp tăng gấp đôi.
Nếu so sánh với các đối thủ cạnh tranh chính hiện tại, mẫu Opus 4.7 mạnh nhất của Anthropic có giá 5 USD cho đầu vào và 25 USD cho đầu ra trên một triệu token. Có thể thấy, GPT-5.5 ngang bằng với đối thủ về giá đầu vào nhưng cao hơn 20% về giá đầu ra.
Mặc dù OpenAI giải thích rằng việc cải thiện hiệu quả sử dụng mã thông báo có thể bù đắp cho việc tăng giá, do đó chi phí thực tế của người dùng không tăng đáng kể, nhưng hiệu quả chi phí cụ thể vẫn cần được ngành xác minh thêm.
Về mô hình này, học viên cao cấp của Đặc vụ Zhao Jiangjie nhận xét rằng việc phát hành GPT-5.5 không tạo nên sự đột phá so với vị trí dẫn đầu và nó không lớn như sự cải thiện đáng kể được mong đợi trong mô hình "Spud" vốn phổ biến trong cộng đồng. Tuy nhiên, nó vẫn tiếp tục duy trì vị trí hàng đầu về khả năng tác nhân và mã hóa. Trong khi khả năng của tác nhân đang được cải thiện, nó cũng đang thúc đẩy các nhà sản xuất mô hình cơ sở cải thiện hiệu quả lặp lại mô hình. Mô hình đột phá thế hệ tiếp theo của OpenAI (GPT-6) có thể sẽ được triển khai.
Tóm lại, đối với người dùng thông thường, GPT-5.5 có thể đáng để thử nhưng không nên coi nó là một công cụ tuyệt đối đáng tin cậy. Đối với người dùng doanh nghiệp, họ phải thận trọng trước khi tích hợp nó vào quy trình làm việc cốt lõi. Một khi 86% "lỗi tin cậy" đó xảy ra, ai sẽ chịu trách nhiệm?