Ngày 24 tháng 4, phiên bản xem trước của DeepSeek-V4 đã chính thức được phát hành và đồng thời có mã nguồn mở. tuyên bố đã đạt đến trình độ hàng đầu trong lĩnh vực nguồn mở và trong nước ở ba khía cạnh là năng lực của Tác nhân, kiến thức thế giới và hiệu suất lý luận. DeepSeek-V4 được chia thành hai phiên bản Pro và Flash, cả hai đều hỗ trợ ngữ cảnh siêu dài triệu (1M) mã thông báo. Cả hai phiên bản đều giảm đáng kể yêu cầu về bộ nhớ đồ họa và tính toán, giảm 73% FLOP suy luận trên mỗi thẻ và giảm 90% mức sử dụng bộ nhớ đệm KV.

Vào ngày 24 tháng 4, dữ liệu từ OpenRouter, nền tảng tổng hợp giao diện lập trình ứng dụng mô hình AI lớn nhất thế giới, cho thấy số lượng lệnh gọi đến V4-Flash đạt 27 tỷ Token, còn V4-Pro là 4,79 tỷ Token nhưng chúng không lọt vào danh sách.
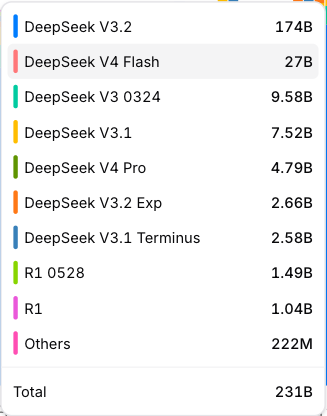
DeepSeek-V4 Sau khi phát hành, các nền tảng đánh giá chính thống đã tiến hành kiểm tra năng lực và xếp hạng.
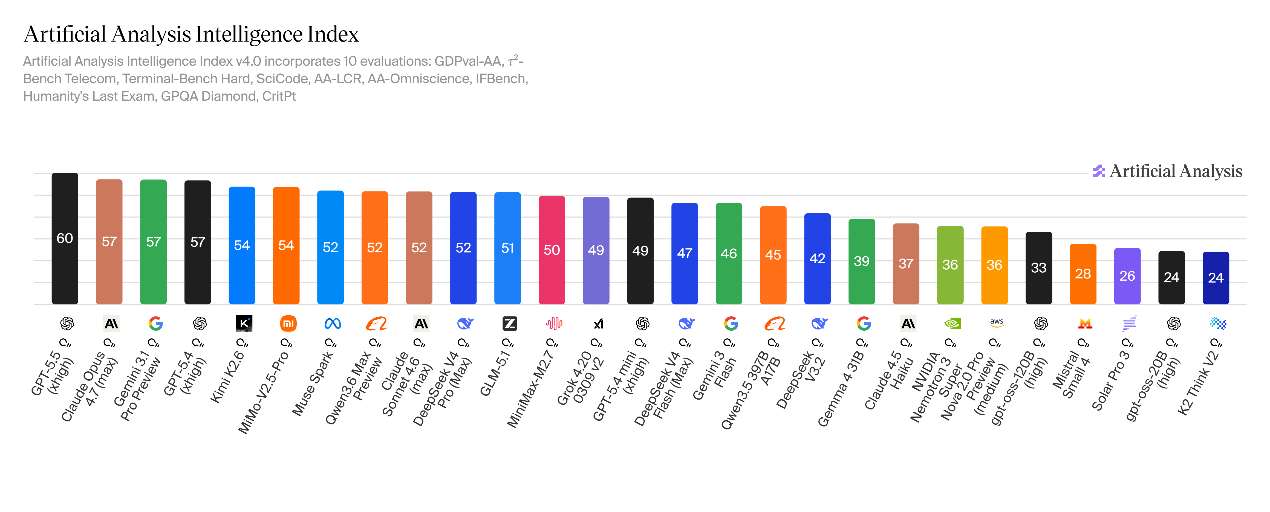
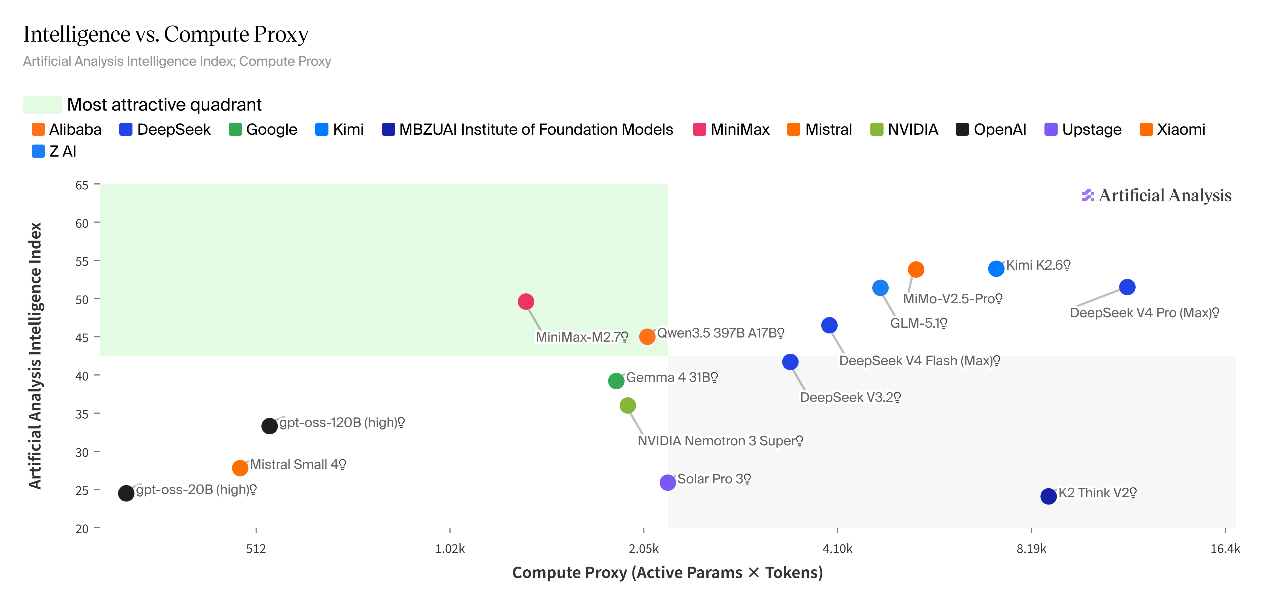
Artificial Analysis đã tiến hành đánh giá đặc biệt về khả năng suy luận của DeepSeek-V4. Kết quả cho thấy V4-Pro đạt 52 điểm ở chỉ số trí tuệ phân tích nhân tạo, đạt bước nhảy 10 điểm so với 42 điểm của phiên bản V3.2 và trở thành mô hình suy luận nguồn mở lớn thứ hai thế giới sau Kimi K2.6.
V4-Flash ghi được 47 điểm. Hiệu năng của nó yếu hơn V4-Pro nhưng vượt trội đáng kể so với DeepSeek-V3.2. Mức độ thông minh toàn diện của nó được so sánh với Claude Sonnet 4.6 (phiên bản đầy đủ), nằm giữa mô hình nguồn đóng hàng đầu và mô hình tầm trung phổ thông.
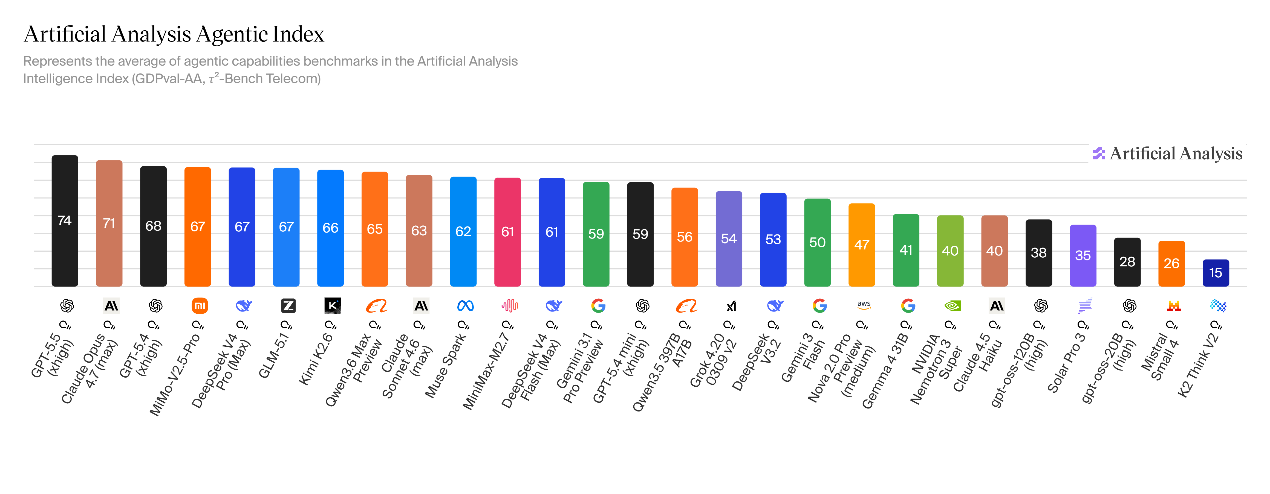
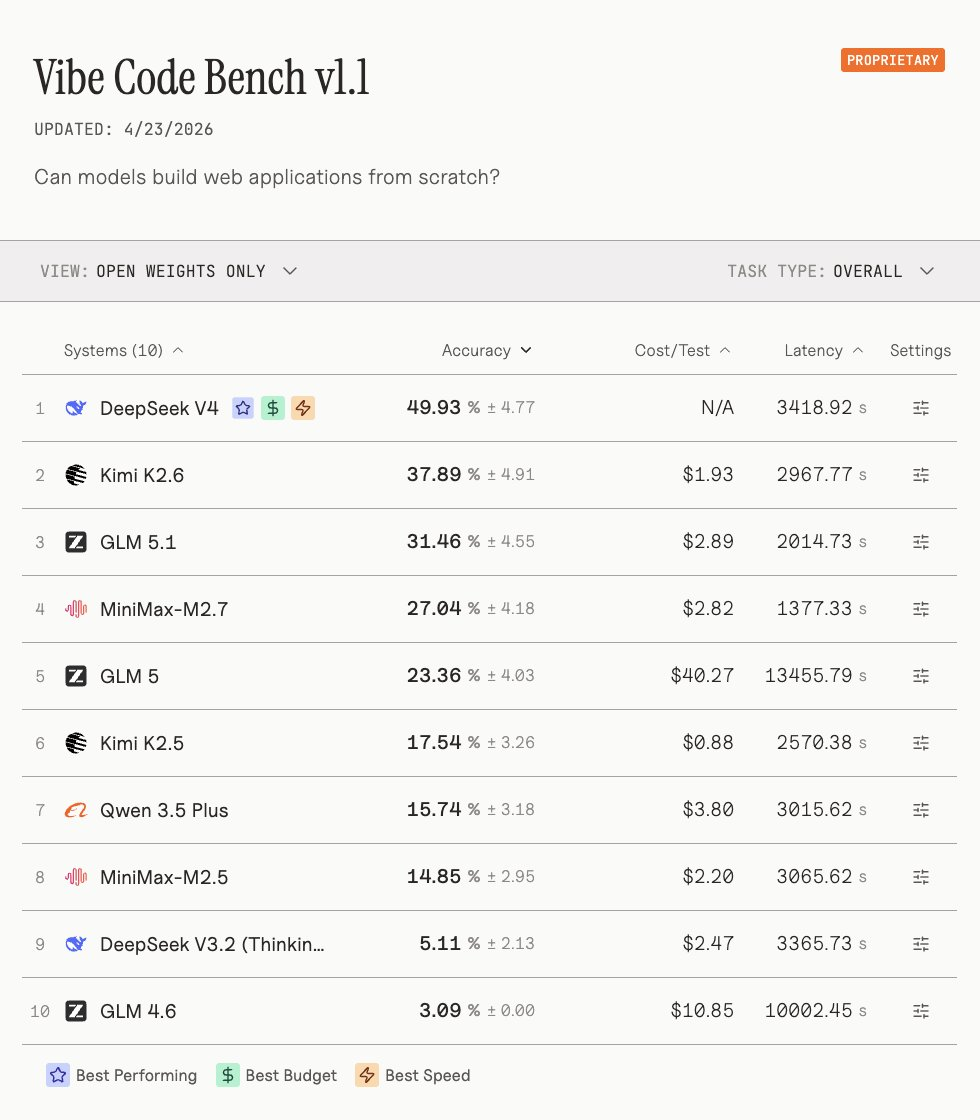
Về hiệu suất tác vụ tác nhân, hiệu suất của V4-Pro đứng đầu trong số tất cả các mô hình trọng lượng nguồn mở trong các tác vụ tác nhân cảnh thực và điểm 1554, vượt qua Kimi K2.6 (1484), GLM-5.1 (1535), GLM-5 (1402) và MiniMax-M2.7 (1514).
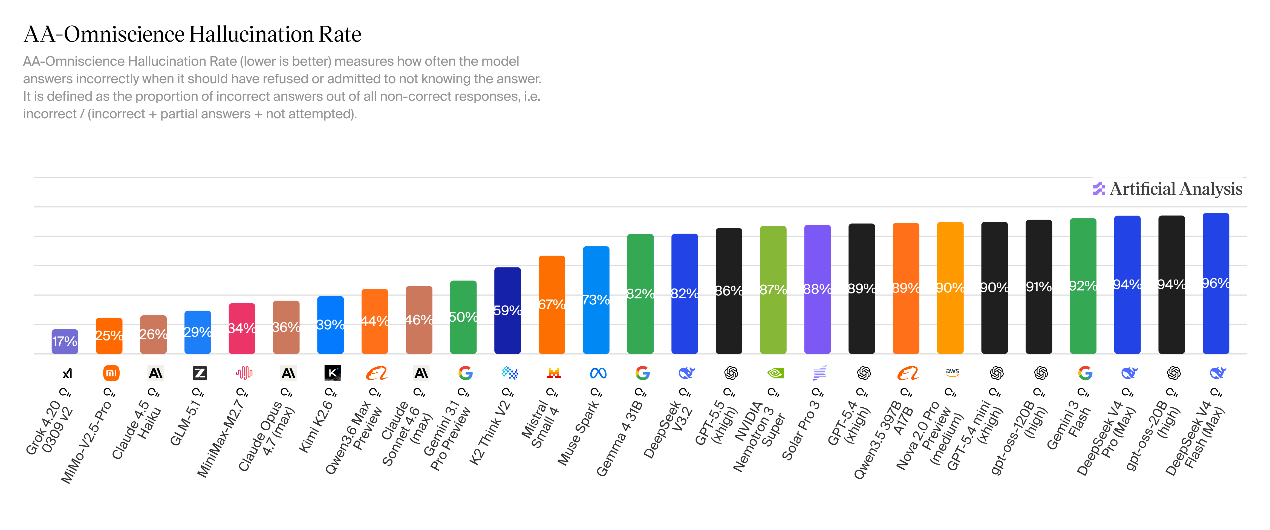
Dự trữ kiến thức DeepSeek-V4 được nâng cấp nhưng tỷ lệ mắc ảo giác lại tăng lên. V4-Pro đạt điểm -10 ở chỉ số đánh giá toàn diện toàn diện (AA-Omniscience), cao hơn 11 điểm so với phiên bản lý luận V3.2. Phần cốt lõi được hưởng lợi từ việc tối ưu hóa đáng kể độ chính xác của câu trả lời kiến thức. V4-Flash đạt điểm -23 và mức tổng thể về cơ bản giống với V3.2.
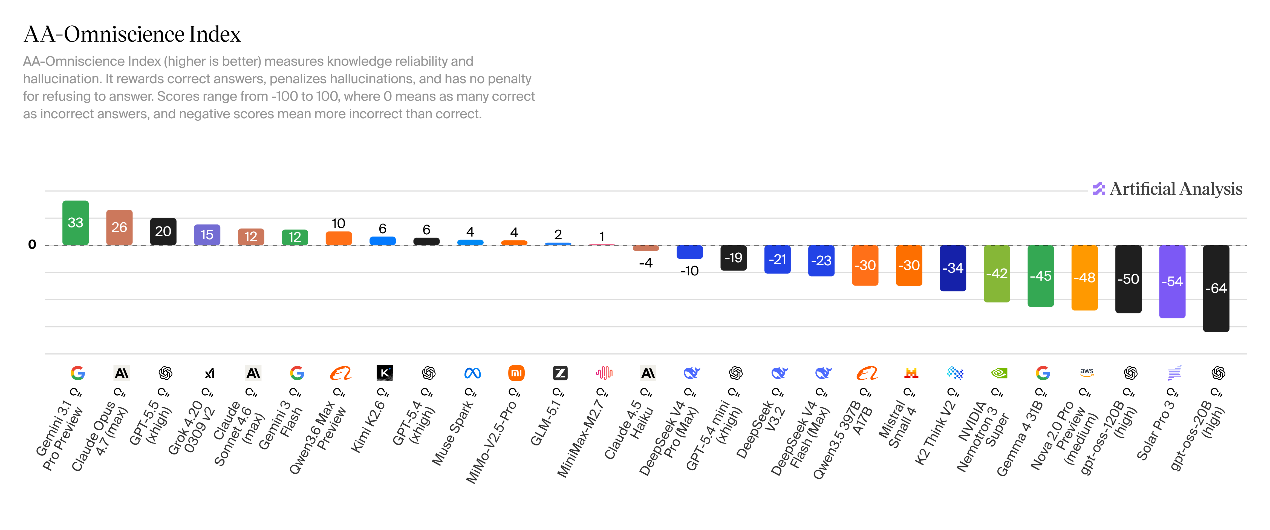
So với tốc độ ảo giác của V3.2 (82%), V4 có hai Vấn đề ảo giác của mẫu này rất nổi bật: Tỷ lệ ảo giác V4-Pro là 94%, tỷ lệ ảo giác V4-Flash là 96%, có nghĩa là mô hình hầu như sẽ luôn buộc phải tạo ra câu trả lời trong các tình huống có vấn đề chưa xác định.
DeepSeek-V4 thấp hơn mô hình nguồn đóng hàng đầu, cao hơn mô hình nguồn mở phổ thông mô hình, và cao hơn đáng kể so với thế hệ trước. Hoàn thành bộ đánh giá chỉ số trí tuệ phân tích nhân tạo đầy đủ, chi phí vận hành của V4-Pro là 1.071 USD, chỉ bằng một phần tư Claude Opus 4.7 (4.811 USD); tuy nhiên, so với các mô hình mã nguồn mở tương tự thì vẫn cao, cao hơn Kimi K2.6 (948 USD), GLM-5.1 (544 USD), DeepSeek-V3.2 (71 USD), gpt-oss-120B (67 USD). DeepSeek-V4-Flash chỉ tốn khoảng 113 USD để chạy, đây là một lợi thế đáng kể về chi phí.
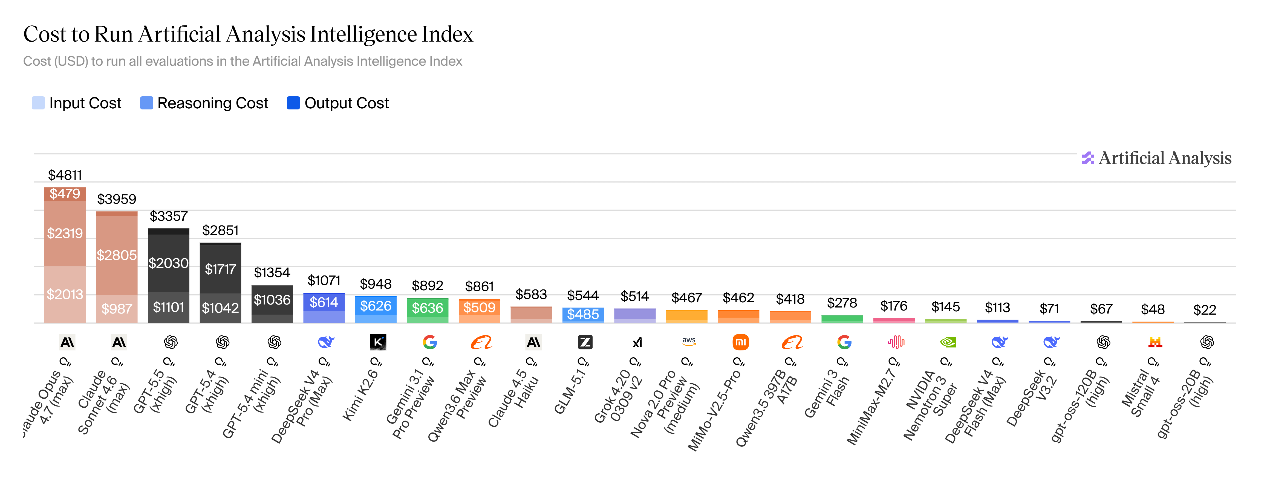
Sau khi hoàn tất quy trình đánh giá tiêu chuẩn, mức tiêu thụ token đầu ra của V4-Pro đạt 190 triệu, đây là một trong những mẫu có mức tiêu thụ token cao nhất trong đợt đánh giá này; Mức tiêu thụ V4-Flash tiếp tục tăng lên 240 triệu token. Ngay cả khi giá thấp, mức tiêu thụ Token cao vẫn là lý do cốt lõi khiến chi phí sử dụng toàn diện của V4-Pro cao hơn các mẫu mã nguồn mở khác.
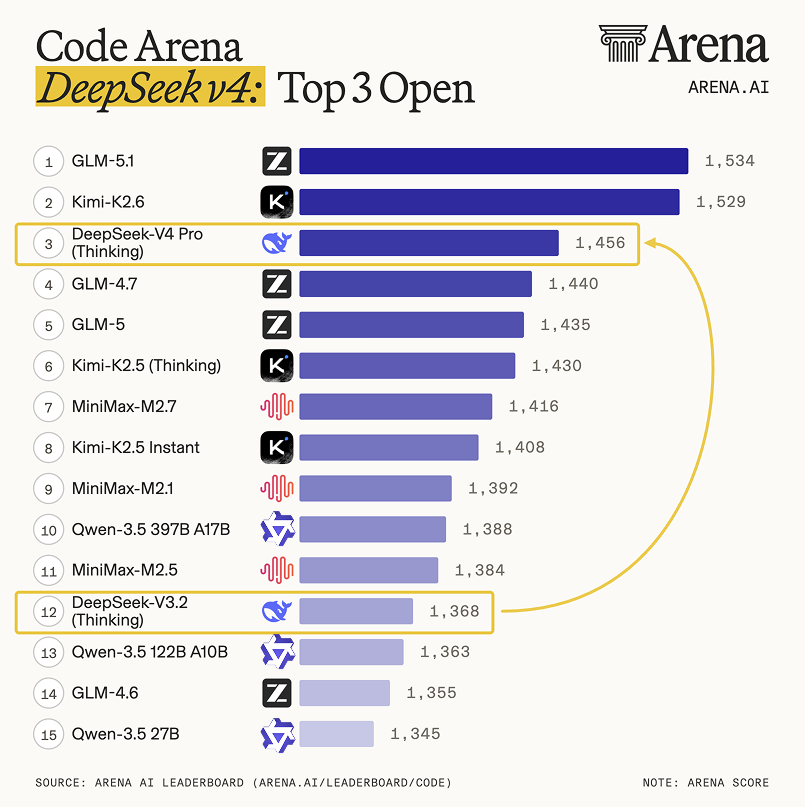
Trong các bài đánh giá khác, Large Model Arena Arena.ai đánh giá DeepSe ek-V4-Pro được coi là "một bước nhảy vọt lớn so với DeepSeek-V3.2" , đứng thứ 3 trong số các mô hình nguồn mở và đứng thứ 14 tổng thể trong lĩnh vực mã của nó. DeepSeek-V4-Pro ngang hàng với GPT-5.4-high và Gemini-3.1-Pro trong các nhiệm vụ phát triển web đại lý. Trong lĩnh vực văn bản của mình, DeepSeek-V4-Pro xếp thứ 2 trong số các mô hình nguồn mở và thứ 14 về tổng thể, giống như Kimi-2.6. DeepSeek-V4-Flash đứng thứ 10 trong số các mô hình nguồn mở và thứ 14 về tổng thể.
Một nhà đánh giá khác Vals AI cho biết rằng DeepSeek-V4 nằm trong Vibe Code In Benchmark (Điểm chuẩn mã khí quyển), nó đã giành được vị trí hàng đầu của nguồn mở mô hình cân nặng với "lợi thế vượt trội". đã đạt được hiệu suất tăng gấp 10 lần so với V3.2 thế hệ trước và thậm chí còn đánh bại các mẫu mã nguồn đóng hàng đầu như Gemini 3.1 Pro. DeepSeek-V4 cũng là mô hình trọng lượng nguồn mở duy nhất vượt mức 40% trên Vibe Code Benchmar.
So với khả năng của DeepSeek-V4, các nước ở nước ngoài chú ý hơn đến sự hợp tác giữa DeepSeek và Huawei.
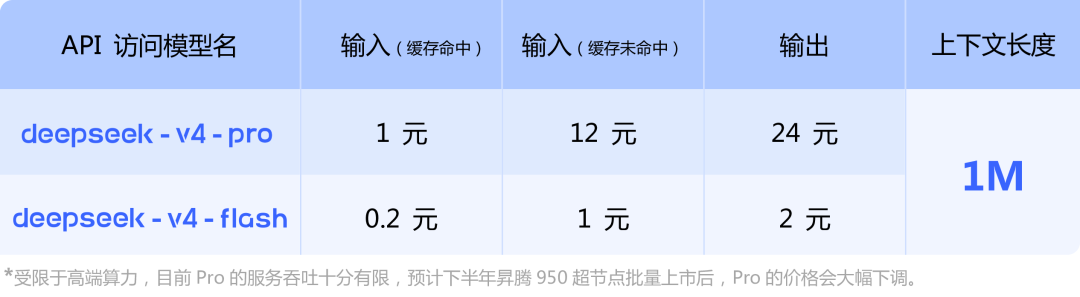
Ở phần cuối thông tin về giá API do DeepSeek-V4 công bố, quan chức này lưu ý cụ thể: "Bị hạn chế bởi sức mạnh tính toán cao cấp, thông lượng dịch vụ hiện tại của Pro rất hạn chế. Dự kiến Ascend 9 sẽ được ra mắt vào nửa cuối năm nay. Sau khi 50 siêu nút được tung ra theo đợt, giá của Pro sẽ giảm đáng kể. "
DeepSeek cho biết trong một báo cáo kỹ thuật rằng V4 đã được NVIDIA ra mắt. Giải pháp EP (song song chuyên nghiệp) chi tiết đã được xác minh trên nền tảng GPU và NPU Huawei Ascend. So với đường cơ sở không hợp nhất mạnh mẽ, nó có thể đạt được hiệu ứng tăng tốc 1,50 ~ 1,73 lần đối với các tác vụ lý luận chung và có thể đạt được hiệu ứng tăng tốc 1,96 lần trong các tình huống nhạy cảm với độ trễ (chẳng hạn như khấu trừ RL và dịch vụ proxy tốc độ cao).
Sau khi phát hành V4, Huawei Ascend cũng thông báo rằng “toàn bộ dòng sản phẩm siêu nút đều hỗ trợ các mẫu dòng DeepSeek-V4”. Được biết, Ascend 950 giảm chi phí tính toán Chú ý và truy cập bộ nhớ bằng cách tích hợp công nghệ song song hạt nhân và đa luồng, cải thiện đáng kể hiệu suất suy luận và kết hợp nhiều thuật toán lượng tử hóa để đạt được thông lượng cao và triển khai suy luận mô hình DeepSeek-V4 có độ trễ thấp.
Về sự hợp tác của DeepSeek với Huawei, He Hui, giám đốc nghiên cứu bán dẫn tại Omdia, một tổ chức nghiên cứu thị trường, cho biết: “Điều này có ý nghĩa rất lớn đối với ngành trí tuệ nhân tạo của Trung Quốc”.
Ông nói thêm: "chip Ascend của Huawei là chip tự phát triển của Trung Quốc. Nó ở cấp độ cao nhất và có thể thay thế các sản phẩm của NVIDIA. DeepSeek-V4 mẫu lớn được điều chỉnh để trang bị chip Huawei, đánh dấu rằng mẫu lớn hàng đầu của Trung Quốc giờ đây có thể hiện thực hóa việc triển khai phần cứng trong nước.
Nhà phân tích Christopher Moniz của Goldman Sachs nhận xét rằng sau khi phát hành phiên bản xem trước DeepSeek-V4, lĩnh vực GPU và chip nội địa đã được tăng cường. Một trong những mối quan tâm cốt lõi là kiến trúc chip cơ bản hỗ trợ mẫu V4: bao gồm các chip được sử dụng để đào tạo mô hình và các thiết bị phần cứng được sử dụng trong giai đoạn suy luận. Điều này cũng có nghĩa là Hệ sinh thái phần cứng AI tự phát triển của Trung Quốc đang cung cấp hỗ trợ sức mạnh tính toán cho việc tiếp tục lặp lại các mô hình lớn tiên tiến nhất của DeepSeek
Sự thay đổi trong lộ trình công nghệ của DeepSeek cũng khẳng định mối lo ngại trước đây của Giám đốc điều hành NVIDIA Jen-Hsun Huang: NVIDIA là
Đầu tháng này, người sáng lập NVIDIA Huang Jensen đã chấp nhận Dwarkesh. Trong một cuộc phỏng vấn độc quyền, Patel từng nói: "Nếu DeepSeek được phát hành trên nền tảng Huawei trước tiên, đó sẽ là thảm họa đối với Hoa Kỳ."
Không giống như DeepSeek-R1, DeepSeek-V4 không gây ra sự sụt giảm mạnh về cổ phiếu công nghệ của Hoa Kỳ.
ảnh hưởng thị trường ban đầu của mô hình suy luận R1 vì thị trường giao dịch đã đáp ứng đầy đủ kỳ vọng: Công nghệ trí tuệ nhân tạo của Trung Quốc có tính cạnh tranh và chi phí sử dụng thấp hơn.
Nhà nghiên cứu Kyle Chan của Viện Brookings cho biết DeepSeek-V4 rất ấn tượng vì đây là mẫu máy gần như hiện đại với độ dài bối cảnh 1 triệu Token hiệu quả và có thể chạy trên các chip mới của Huawei đã không tái tạo "khoảnh khắc DeepSeek-R1" vì kỳ vọng của thế giới bên ngoài đối với khả năng AI của Trung Quốc cao hơn nhiều so với trước đây.