Phiên bản xem trước DeepSeek-V4 cuối cùng đã được phát hành. Hôm nay, DeepSeek chính thức thông báo rằng hai mô hình deepseek-v4-pro và deepseek-v4-flash với bối cảnh siêu dài hàng triệu từ đã được phát hành và là nguồn mở. Từ giờ trở đi, bạn có thể đăng nhập vào trang web chính thức hoặc ứng dụng chính thức để nói chuyện với DeepSeek-V4 mới nhất và khám phá trải nghiệm mới về bộ nhớ ngữ cảnh siêu dài 1M (triệu). Dịch vụ API đã được cập nhật đồng thời.

Văn bản | Cột "BUG" Chu Wemenng

Theo đánh giá benchmark chính thức, về độ dài ngữ cảnh, kiến thức, lý luận và khả năng của tác nhân, hiệu suất của DeepSeek V4 có thể so sánh với các mô hình nguồn đóng quốc tế hàng đầu và đã đạt đến cấp độ hạng nhất của các mô hình nguồn mở quốc tế. So sánh trong cột "BUG" cho thấy về mặt giá lệnh gọi API, phiên bản V4 của DeepSeek, phiên bản đã một mình thúc đẩy việc giảm giá trong ngành công nghiệp mô hình lớn trong nước vào năm ngoái, một lần nữa đặt "giá thấp nhất" trong ngành.
"Mặc dù giá gọi trên một triệu Token của các mô hình trong nước không giảm nhiều nhưng thời lượng ngữ cảnh dài và hiệu suất tốt mang lại lợi thế rất cạnh tranh!" Một số người trong cuộc nhận xét trên cột truyền thông "BUG": "Người bán thịt mô hình lớn đó đã trở lại!"
Hiệu suất có thể so sánh với các mô hình nguồn đóng hàng đầu, kiến thức và khả năng suy luận đang dẫn đầuT AGPH67
Theo giới thiệu chính thức của DeepSeek, Dòng V4 bao gồm hai phiên bản mô hình: DeepSeek-V4-Pro với tổng thông số là 1,6T, Tham số kích hoạt là 49B và dữ liệu đào tạo trước là 33T; tổng tham số của DeepSeek-V4-Flash là 284B, tham số kích hoạt là 13B và dữ liệu đào tạo trước là 32T; cả hai đều hỗ trợ nguyên bản 1 triệu bối cảnh mã thông báo.
Theo dữ liệu kiểm tra benchmark được DeepSeek tiết lộ, trong các bài kiểm tra kiến thức và lý luận, DeepSeek-V4-Pro-Max vượt trội hơn Apex. Nó đạt hiệu suất tốt nhất trong các bài kiểm tra Shortlist và Codeforces, vượt qua các mẫu quốc tế như Claude-Opus-4.6-Max, GPT-5.4-xHigh và Gemin-3.1-Pro-Hight, thể hiện tính logic mạnh mẽ và khả năng thuật toán. Trong thử nghiệm được xác minh SimpleQA, nó kém Gemini-3.1-Pro-High một chút nhưng trước Claude và GPT.
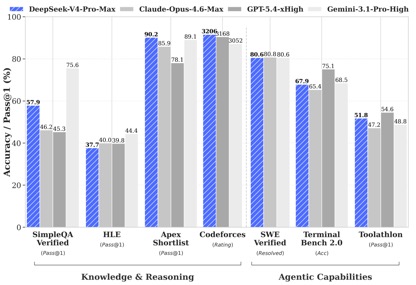
Trong đánh giá khả năng của Agentic, ba mẫu V4, Opus-4.6 và Gemin-3.1-pro đã được thử nghiệm trong SWE. Có sự ngang bằng trong nhiệm vụ Đã xác minh và DeepSeek đã đạt được cấp độ chỉ sau GPT-5.4-xHigh trong nhiệm vụ Toolathlon và mức cao hơn Opus-4.6 trên Terminal Bench 2.0, phản ánh những ưu điểm của nó trong các tình huống gọi công cụ và thực thi lệnh phức tạp.
Hiện tại, DeepSeek-V4 đã trở thành mô hình Mã hóa tác nhân được các nhân viên nội bộ của công ty sử dụng. Theo phản hồi đánh giá, trải nghiệm sử dụng tốt hơn Sonnet 4.5 và chất lượng phân phối gần với chế độ không suy nghĩ của Opus 4.6.
Trong đánh giá toán học, STEM và mã cạnh tranh, DeepSeek-V4-Pro vượt qua hầu hết các mô hình nguồn mở đã được đánh giá công khai và đạt kết quả tương đương với các mô hình nguồn đóng hàng đầu thế giới.
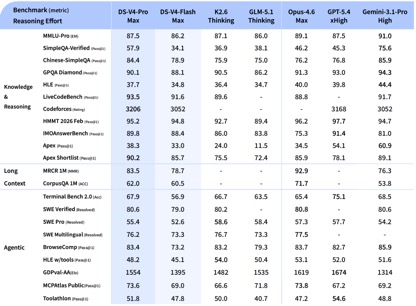
Khi kết hợp lại với nhau, xét về khả năng xử lý kiến thức và lý luận, DeepSeek-v4 đã đạt được vị trí dẫn đầu toàn diện so với các mô hình nguồn mở trong nước và có thể so sánh với khả năng đánh giá quốc tế. Tuy nhiên, về khả năng của Agentic, mặc dù DeepSeek-v4 mới nhất đã có những cải tiến tốt nhưng khoảng cách giữa khả năng hạng nhất trong nước và quốc tế vẫn chưa được nới rộng và mỗi bên đều dẫn trước.
"Chuẩn" bối cảnh 1 triệu, Price Butcher "đã trở lại"
So với những lợi thế về hiệu suất được phản ánh trong các thử nghiệm điểm chuẩn khác nhau, tính năng lớn nhất của bản phát hành V4 này là sự đột phá về khả năng văn bản dài và giá lệnh gọi API giảm hơn nữa.
Nhờ cơ chế chú ý mới do DeepSeek-V4 tiên phong, V4 đạt được khả năng ngữ cảnh dài hàng đầu thế giới bằng cách nén kích thước mã thông báo và kết hợp nó với chú ý thưa thớt DSA (Chú ý thưa thớt DeepSeek) và giảm đáng kể các yêu cầu về bộ nhớ điện toán và đồ họa so với các phương pháp truyền thống, biến ngữ cảnh 1 triệu (một triệu) trở thành tiêu chuẩn cho tất cả các dịch vụ DeepSeek chính thức.
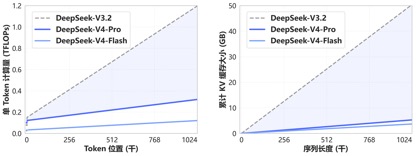
Một năm trước, 1 triệu bối cảnh là con át chủ bài độc quyền của Gemini, thậm chí Trong hầu hết các mô hình nguồn mở trong nước chính thống được phát hành gần đây, độ dài của bối cảnh mô hình chủ yếu nằm trong phạm vi 128K-200K và DeepSeek trực tiếp chuyển đổi hàng triệu bối cảnh từ "chức năng nguồn đóng cao cấp" sang cấu hình tiêu chuẩn nguồn mở.
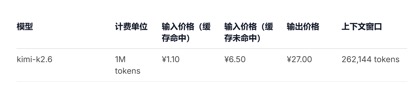
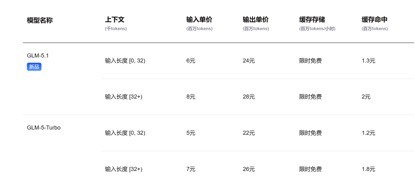
Về mặt lệnh gọi giá API, so với đơn giá đầu vào GLM-5.1 hiện tại là 1,3 nhân dân tệ-2 nhân dân tệ/triệu mã thông báo (lần truy cập bộ đệm) và Kimi-K2.6 1,1 nhân dân tệ/triệu mã thông báo (bộ nhớ đệm), DeepSeek-v4 -Đối với phiên bản chuyên nghiệp và flash, đơn giá đầu vào lần lượt là 1 nhân dân tệ/triệu mã thông báo và 0,2 nhân dân tệ/triệu mã thông báo. Tuy giá không giảm nhiều nhưng đều ở mức thấp nhất và độ dài bối cảnh được kéo dài ra nhiều lần.
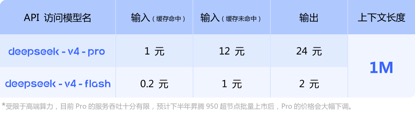
(Giá lệnh gọi API mẫu dòng DeepSeek- v4)
T AGPH24
(Giá gọi API mẫu GLM-5.1)
“DeepSeek-v 4 Đột phá về hiệu suất do bản phát hành này mang lại ít tác động đến thế giới bên ngoài hơn so với bản phát hành DeepSeek-R1. Hiệu suất vẫn ở cấp độ đầu tiên, nhưng vị trí dẫn đầu chưa được mở rộng hoàn toàn. Mẫu V4 tập trung nhiều hơn vào việc cải thiện khả năng văn bản dài và giảm giá hơn nữa."
TAGPH. 29Người này than thở: "Sau khi phát hành các mẫu DeepSeek-V3 và R1, lợi thế về hiệu suất do sự đổi mới công nghệ cơ bản mang lại đã trực tiếp thúc đẩy việc giảm giá chung của toàn bộ ngành công nghiệp mô hình lớn trong nước. Mặc dù giá gọi trên một triệu Token của phiên bản V4 không giảm nhiều so với các đồng nghiệp trong nước nhưng nó vẫn có tính cạnh tranh. Kẻ bán thịt mô hình lớn đã quay trở lại!"“Sức mạnh tính toán của Huawei sẽ được bổ sung theo đợt vào nửa cuối năm nay và giá Pro sẽ giảm đáng kể”
Đáng lưu ý ở cuối thông tin về giá API do DeepSeek-v4 phát hành, quan chức này đặc biệt lưu ý: "Bị hạn chế bởi sức mạnh tính toán cao cấp, thông lượng dịch vụ hiện tại của Pro rất hạn chế. Dự kiến Shengteng 950 sẽ vượt mức 950 vào nửa cuối năm nay. Sau khi các nút được tung ra theo đợt, giá của Pro sẽ giảm đáng kể ”

Điều này có nghĩa là. , các mẫu dòng v4 được phát hành lần này đã được điều chỉnh cho phù hợp với siêu nút Ascend 950 của Huawei. Chỉ cần Ascend 950 ra mắt, người dùng có thể sử dụng DeepSeek-v4 dựa trên sức mạnh tính toán trong nước tương đương với các mẫu mã nguồn đóng hàng đầu quốc tế.
Trong tài liệu kỹ thuật nguồn mở chính thức, DeepSeek cũng đề cập đến điều này, nói rằng v4 đã được triển khai trên GPU NVIDIA và Huawei Ascend Sơ đồ EP (song song chuyên gia) chi tiết đã được xác minh trên nền tảng NPU. So với đường cơ sở không hợp nhất mạnh mẽ, nó có thể đạt được hiệu ứng tăng tốc 1,50-1,73 lần đối với các tác vụ lý luận chung và có thể đạt được hiệu ứng tăng tốc 1,96 lần trong các tình huống nhạy cảm với độ trễ (chẳng hạn như khấu trừ RL và dịch vụ proxy tốc độ cao).

Sau khi phát hành V4, Huawei Ascend cũng thông báo rằng “tất cả các dòng sản phẩm siêu nút đều hỗ trợ các mẫu dòng DeepSeek V4”. Được biết, Ascend 950 giảm chi phí tính toán Chú ý và truy cập bộ nhớ bằng cách tích hợp công nghệ song song hạt nhân và đa luồng, cải thiện đáng kể hiệu suất suy luận và kết hợp nhiều thuật toán lượng tử hóa để đạt được thông lượng cao và triển khai suy luận mô hình DeepSeek V4 có độ trễ thấp.
Đầu tháng này, người sáng lập NVIDIA Huang Jensen đã chấp nhận Dwarkesh Trong một cuộc phỏng vấn độc quyền, Patel nói: "Nếu DeepSeek được phát hành trên nền tảng Huawei trước, đó sẽ là một thảm họa đối với đất nước chúng tôi (Hoa Kỳ)." Theo quan điểm của Huang Renxun, mặc dù DeepSeek là mô hình nguồn mở và cũng có thể được sử dụng trên các sản phẩm của NVIDIA, nhưng nếu DeepSeek được tối ưu hóa đặc biệt cho sức mạnh tính toán của Huawei, NVIDIA sẽ gặp bất lợi do những hạn chế như hạn chế mua sức mạnh tính toán cao cấp.
Bây giờ có vẻ như mặc dù DeepSeek cũng đã xác minh giải pháp EP cho sức mạnh tính toán của Nvidia nhưng điều mà Huang Renxun lo lắng vẫn đã xảy ra. Theo quan điểm của người trong ngành, "V4 là sản phẩm bị ép buộc bởi cuộc chơi sức mạnh tính toán. Trong năm tới, các mẫu máy quy mô lớn trong nước chạy trên thẻ nội địa sẽ dần trưởng thành".
TAGPH 55Khả năng đa phương thức vẫn chưa xuất hiệnThật không may, DeepSeek Mặc dù V4 đã được phát hành nhưng phiên bản này vẫn là mô hình văn bản thuần túy không có nhiều khả năng đa phương thức như hình ảnh văn bản và video văn bản. Điều này cũng cho phép người dùng thông thường nhanh chóng trải nghiệm và đánh giá một mô hình, điều này gây thêm nhiều khó khăn.

Xét cho cùng, khi khả năng của các mô hình ngôn ngữ lớn tiếp tục được cải thiện và tỷ lệ ảo giác giảm dần, rất khó để câu hỏi và câu trả lời về kiến thức thông thường và đơn lẻ phản ánh khách quan khả năng toàn diện của một mô hình. Đối với hầu hết người dùng, nếu muốn trải nghiệm trực quan các khả năng của mẫu V4, họ phải tải xuống và sử dụng cá nhân trong một thời gian. Các mẫu thuộc dòng
V4 được ra mắt cùng thời điểm DeepSeek gần đây tiết lộ kế hoạch huy động 50 tỷ nhân dân tệ. Những người thân cận với DeepSeek tiết lộ rằng định giá trước cấp vốn của DeepSeek là 300 tỷ nhân dân tệ, tương đương khoảng 44 tỷ đô la Mỹ. Hiện tại, Tencent Holdings và Tập đoàn Alibaba đang đàm phán để đầu tư vào DeepSeek. Tuy nhiên, DeepSeek chưa trả lời trực tiếp các câu hỏi của giới truyền thông về các vấn đề liên quan đến tài chính.
Có lẽ, đối với người sáng lập DeepSeek, Liang Wenfeng, việc sử dụng việc phát hành V4 để huy động nguồn tài chính kịp thời nhằm củng cố sức mạnh của mình là một bước đi khôn ngoan khi tốc độ phát triển "trí tuệ" của các mô hình lớn toàn cầu đang chậm lại, sự cạnh tranh về nhân tài trong ngành ngày càng gay gắt và xu hướng đa phương thức và đại lý của ngành ngày càng nổi bật.