DeepSeek V4 rất được mong đợi cuối cùng đã được phát hành! Vừa rồi, phiên bản Preview được chờ đợi từ lâu của DeepSeek V4 đã chính thức ra mắt. Hai phiên bản - V4-Pro và V4-Flash. Toàn bộ chuỗi sản phẩm này đạt tiêu chuẩn với ngữ cảnh cực dài 1M (triệu từ), trọng lượng mô hình nguồn mở được đồng bộ hóa và báo cáo kỹ thuật .

Trong hai ngày trước Ngày tháng Năm, các mẫu lớn đã bước vào một làn sóng phát hành mới.
Trưa ngày 23/4, "cậu bé thiên tài" Yao Shunyu đã trao phiếu trả lời mẫu đầu tiên sau khi gia nhập Tencent. Phiên bản xem trước của Tencent Hunyuan Hy3 đã được ra mắt. Nó có kiến trúc MoE 295 tỷ tham số, tham số được kích hoạt 21B, hiệu suất suy luận tăng 40% và giá đầu vào giảm xuống còn 1,2 nhân dân tệ/triệu token.
Sáng nay, OpenAI đã ra mắt GPT-5.5 cho người dùng trả phí và chính thức công bố gói API, tập trung vào quy trình làm việc của Đại lý và hoàn thành nhiệm vụ nhiều bước. Cửa sổ ngữ cảnh đã được mở rộng lên 1 triệu mã thông báo và giá API cũng đã tăng - đầu vào 5 USD, đầu ra 30 USD/triệu mã thông báo.
Nhìn bề ngoài, con đường của ba công ty là khác nhau: OpenAI đi theo con đường nguồn đóng cao cấp và tiếp tục tăng trần giá; Tencent đưa mô hình này vào hệ sinh thái của riêng mình và sử dụng hiệu quả chi phí để thúc đẩy thương mại hóa quy mô lớn; DeepSeek tiếp tục truyền thống nguồn mở và đồng thời đẩy độ dài ngữ cảnh lên một điểm quan trọng toàn diện mới.
Đồng thời, ba từ khóa về khả năng của Tác nhân, ngữ cảnh siêu dài, lệnh gọi mã và công cụ và xuất hiện liên tục trong các mẫu mới do ba công ty phát hành. Tất cả đều bổ sung theo cùng một hướng: cho phép mô hình xử lý thông tin dài hơn, hoạt động tự chủ trong các chuỗi nhiệm vụ phức tạp hơn và thực sự được nhúng vào quy trình làm việcTA GPH73 「Công việc」.
01
DeepSeek "Chủ nghĩa thực dụng" của V4
DeepSeek Bản phát hành này đã thay đổi bối cảnh của Million Words từ "tùy chọn cao cấp" thành "tiêu chuẩn cơ bản".
Trước đó, độ dài ngữ cảnh ở mức 1M phổ biến hơn trong các phiên bản cao cấp của các mẫu mã nguồn đóng hàng đầu. Chi phí gọi cao đủ để cản trở hầu hết các nhà phát triển và doanh nghiệp vừa và nhỏ.
Cách tiếp cận của DeepSeek rất rõ ràng: cả hai phiên bản V4-Pro và V4-Flash đều được trang bị tiêu chuẩn độ dài ngữ cảnh 1M. Cái trước mang lại hiệu suất tối ưu và cái sau cung cấp một lựa chọn kinh tế toàn diện, đáp ứng đầy đủ cho những người dùng có nhu cầu khác nhau. Chiến lược “phân cấp bừa bãi các khả năng cốt lõi” này về cơ bản làm giảm hoàn toàn ngưỡng mua lại của ngành đối với khả năng xử lý văn bản dài.

Nguồn hình ảnh: Trang web chính thức của DeepSeek
Phiên bản Flash tập trung vào độ trễ cực thấp và hiệu suất chi phí cao. Đây là giải pháp cốt lõi của DeepSeek cho các kịch bản tần số cao nhẹ . Với các tham số kích hoạt 13B, cơ chế chú ý nén mã thông báo mới và tối ưu hóa kiến trúc chú ý thưa thớt DSA, nó đạt được tốc độ phản hồi cực nhanh trong khi vẫn đảm bảo gần bằng khả năng suy luận cốt lõi của phiên bản Pro. Đối với các tương tác đối thoại trong thời gian thực, quy trình gọi hàm và thậm chí tất cả các kịch bản nhẹ nhạy cảm với tốc độ phản hồi, tính năng này có thể mang lại sự cải thiện đáng kể về trải nghiệm.
Quan trọng hơn là cơ cấu chi phí cạnh tranh .
Theo tài liệu định giá API chính thức của DeepSeek, phiên bản Flash áp dụng quy tắc thanh toán theo cấp bậc: mã thông báo đầu vào cho lần truy cập bộ đệm thấp tới 0,2 nhân dân tệ/triệu mã thông báo, mã thông báo đầu vào cho lần bỏ lỡ bộ nhớ đệm là 1 nhân dân tệ/triệu mã thông báo và mã thông báo đầu ra có giá 2 nhân dân tệ/triệu mã thông báo.
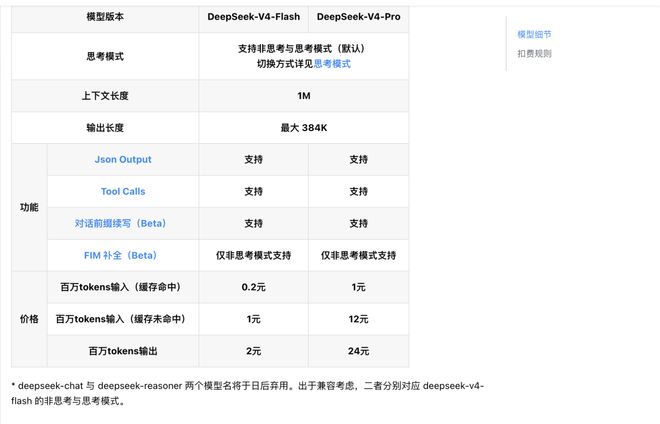
DeepSeek V4 Mỗi phiên bản trở thành|Nguồn hình ảnh: Tài liệu API DeepSeek
Mức giá thân thiện với người dùng, cộng với tiêu chuẩn 1 triệu cho toàn bộ chuỗi Khả năng theo ngữ cảnh khiến "chi phí cho mỗi cuộc gọi" không còn là hạn chế cốt lõi trong thiết kế kỹ thuật - nhà phát triển có thể ưu tiên trải nghiệm sản phẩm và thiết kế kiến trúc mà không cần thực hiện nhiều lần sự cân bằng giữa số lượng cuộc gọi và chi phí.
Flash giải quyết nhu cầu phổ biến về "giá cả phải chăng và nhanh chóng", trong khi V4-Pro đang trả lời một câu hỏi cốt lõi khác: ranh giới về khả năng của các mô hình lớn nguồn mở có thể được đẩy đến mức nào.
Việc cải tiến khả năng trực quan nhất vẫn xoay quanh bối cảnh dài. DeepSeek trực tiếp tăng độ dài bối cảnh mô hình từ 128K ở thế hệ V3.2 trước lên 1M (một triệu mã thông báo). Cùng với sự đổi mới của kiến trúc cơ bản, nó giúp giảm đáng kể các yêu cầu tính toán ngữ cảnh và bộ nhớ video dài trong khi vẫn đảm bảo rằng hiệu suất của toàn bộ cửa sổ ngữ cảnh vẫn nguyên vẹn.
Ở quy mô này, nhà phát triển có thể nhập trực tiếp các thư viện mã hoàn chỉnh, tài liệu ngành siêu dài, tệp dự án nhiều vòng và thậm chí hoàn thành sách với hàng triệu từ để xử lý từ đầu đến cuối mà không cần phải xây dựng thêm hệ thống tạo tăng cường truy xuất (RAG) phức tạp, giúp đơn giản hóa đáng kể các liên kết kỹ thuật của quá trình xử lý văn bản dài.
Đối với kiến trúc cơ bản, phiên bản Pro áp dụng kiến trúc MoE với tổng tham số là 1,6T và tham số kích hoạt là 49B. Lượng dữ liệu trước khi đào tạo đạt tới 33T, đây là mức đào sâu toàn diện của lộ trình chuyên gia kết hợp DeepSeek. Dữ liệu đánh giá chính thức cho thấy trong các đánh giá lý luận cốt lõi như toán học, STEM và mã cấp độ cạnh tranh, nó đã vượt qua tất cả các mô hình nguồn mở được đánh giá công khai hiện nay và đạt đến trình độ tương đương với các mô hình nguồn đóng hàng đầu thế giới.
Về khả năng của Tác nhân, chất lượng phân phối của nó gần giống với chế độ không suy nghĩ của Claude Opus 4.6 . Phản hồi sử dụng nội bộ tốt hơn Anthropic Sonnet 4.5 và nó đã trở thành công cụ Mã hóa tác nhân chính cho nhân viên nội bộ DeepSeek.
Ở cấp độ chức năng, cả hai phiên bản của dòng V4 đều hỗ trợ cả chế độ không suy nghĩ và chế độ suy nghĩ. Các nhà phát triển có thể tùy chỉnh cường độ tư duy thông qua tham số Reasoning_effort, đồng thời hỗ trợ đầy đủ Đầu ra Json, Lệnh gọi công cụ và khả năng tiếp tục tiền tố hội thoại.
Về mặt giá cả, phiên bản Pro cũng tiếp tục lộ trình tiết kiệm chi phí . Giá chính thức là: mã thông báo đầu vào 1 nhân dân tệ/triệu mã thông báo cho lần truy cập bộ đệm, mã thông báo đầu vào 12 nhân dân tệ/triệu mã thông báo cho lỗi bộ nhớ đệm và giá mã thông báo đầu ra là 24 nhân dân tệ/triệu. token, thấp hơn đáng kể so với mô hình nguồn đóng hàng đầu cùng cấp ở nước ngoài. Quyền truy cập
API cũng đã đạt được ngưỡng cực kỳ thấp. Nhà phát triển không cần sửa đổi base_url ban đầu. Họ chỉ cần thay thế tham số model bằng tên phiên bản tương ứng để hoàn tất quyền truy cập. Nó cũng tương thích với các định dạng giao diện OpenAI ChatCompletions và Anthropic.
Sự kết hợp giữa “tăng khả năng + giảm chi phí” này khiến cho khả năng hàng đầu của mô hình lớn không còn là tài nguyên độc quyền của một số nhà sản xuất. Khi ngành dần rơi vào vòng luẩn quẩn của cuộc chạy đua vũ trang tham số, DeepSeek cung cấp một mô hình mới để phổ cập các mô hình lớn với cấu hình tiêu chuẩn của hàng triệu bối cảnh và các tùy chọn nguồn mở liên kết đầy đủ.
Đồng thời, DeepSeek V4 đã thực hiện các điều chỉnh và tối ưu hóa đặc biệt cho các sản phẩm Đại lý chính thống như Claude Code, OpenClaw, OpenCode và CodeBuddy, đồng thời hiệu suất của nó đã được cải thiện trong các tình huống thực tế như tác vụ mã hóa và tạo tài liệu. Giá trị của mô hình cuối cùng phải được kiểm tra trong quá trình phát triển và làm việc thực tế.
02
Tiếp tục mở nguồn, API Mở hoàn toàn
DeepSeek tiếp tục lộ trình nguồn mở và trực tiếp mở tất cả lệnh gọi API.
Hiện tại, trọng lượng mô hình của DeepSeek-V4 đã được mở để tải xuống đồng thời trên nền tảng Hugging Face và ModelScope, đồng thời các báo cáo kỹ thuật hỗ trợ cũng đã được công khai, hỗ trợ các nhà phát triển triển khai cục bộ và phát triển thứ cấp.
Khác với thông lệ trong ngành về "phiên bản bị thiến nguồn mở, phiên bản đầy đủ nguồn đóng" của một số nhà sản xuất, hai phiên bản nguồn mở giữ lại đầy đủ tất cả các khả năng nhất quán với API đám mây chính thức - bao gồm chế độ kép không suy nghĩ/suy nghĩ, xử lý không mất dữ liệu ngữ cảnh siêu dài 1M, tối ưu hóa đặc biệt cho tác nhân và khả năng gọi công cụ đầy đủ mà không cần thiến chức năng.
Điều này có nghĩa là cho dù bạn là một công ty khởi nghiệp vừa hay nhỏ, một nhà phát triển cá nhân hay một tổ chức nghiên cứu khoa học, bạn đều có thể có được cơ sở mô hình lớn với hàng triệu bối cảnh, khả năng lý luận và tác nhân cấp cao nhất ở ngưỡng 0 và bạn không còn cần phải trả phí giao diện nguồn đóng cao cho các chức năng mô hình cao cấp.
Để hạ thấp hơn nữa ngưỡng triển khai, DeepSeek đã đồng thời mở nguồn chuỗi công cụ toàn bộ quy trình để tinh chỉnh mô hình, định lượng và tăng tốc suy luận. Nó đã hoàn thành việc điều chỉnh nguyên bản Ngày 0 của các khung suy luận chính thống như vLLM và TGI, cũng như các khung Tác nhân chính thống như LangChain và LlamaIndex. Nó cũng đã mở ra giải pháp triển khai toàn diện cho các nền tảng điện toán trong nước, cho phép các nhà phát triển triển khai nhanh chóng các ứng dụng trong các môi trường phần cứng khác nhau.
Đồng thời, DeepSeek cũng đưa ra kế hoạch chuyển đổi lặp lại mô hình rõ ràng: mô hình giao diện API cũ có tên deepseek-chat và deepseek-reasoner sẽ ngừng sử dụng sau ba tháng (24 tháng 7 năm 2026). Ở giai đoạn hiện tại, hai tên mô hình này lần lượt trỏ đến deepseek-v4-flash. Chế độ không suy nghĩ và chế độ suy nghĩ để lại đủ thời gian cho các nhà phát triển di chuyển suôn sẻ.
03
Thực hiện chắc chắn AI "Mô hình cơ sở hạ tầng"
Nhìn vào các bản phát hành trong hai ngày này cùng nhau, có thể thấy rõ một xu hướng: mỗi công ty đang tăng cường năng lực của Đại lý.
Trong hai năm qua, sự chú ý của công chúng và thị trường vốn đối với các mô hình lớn chủ yếu tập trung vào “sự thông minh”, nhưng giờ đây nó đã chuyển sang “ai có thể hoàn thành công việc ổn định hơn”. Trọng tâm của việc phát hành GPT-5.5 không phải là mức độ hiểu biết đa phương thức đã được cải thiện mà là khả năng thực thi liên tục của nó trong các tình huống như lập trình Tác nhân, sử dụng máy tính và công việc tri thức. Điểm bán hàng cốt lõi của Tencent Hunyuan Hy3 còn là “khả năng hành động” trong thế giới thực. DeepSeek V4 tập trung trực tiếp vào các khả năng của Tác nhân và xử lý ngữ cảnh dài, với mục tiêu rõ ràng là khối lượng công việc thực tế.
Đằng sau sự thay đổi này là thực tế là toàn bộ ngành đang hướng tới cạnh tranh về “tiện ích mô hình”. Ngày nay, người dùng và khách hàng doanh nghiệp ngày càng ít quan tâm đến việc mô hình của bạn xếp hạng ở đâu trong một đánh giá nhất định. Điều họ quan tâm là mô hình và sản phẩm có thể giúp họ làm được bao nhiêu công việc: liệu mô hình này có thể giúp tôi viết mã hay không, liệu nó có thể xử lý các tài liệu phức tạp hay không, liệu nó có thể thực hiện các tác vụ nhiều bước mà không gặp lỗi hay không và liệu nó có thể chạy với chi phí hợp lý hay không.

Nguồn hình ảnh: Trang web chính thức của DeepSeek
Ở cuối bài viết xuất bản hôm nay, DeepSeek trích dẫn một câu từ "Xunzi": "Đừng bị danh tiếng cám dỗ, đừng sợ bị vu khống, hãy hành động đúng mực và trung thực", tiếp tục giữ vững con đường kỹ thuật của riêng mình. Trong bối cảnh cạnh tranh người mẫu lớn hiện nay, ý nghĩa của câu này rất rõ ràng - đừng bị quấy rầy bởi những đánh giá và tiếng ồn bên ngoài, mà hãy tập trung vào việc làm đúng.
Các hành động của DeepSeek trong khoảng một năm qua đã thực sự thực hiện logic này: sử dụng nguồn mở để xây dựng ảnh hưởng sinh thái của nhà phát triển toàn cầu, sử dụng hiệu quả chi phí tối đa để phá vỡ các rào cản đối với việc sử dụng các khả năng AI cao cấp và sử dụng đổi mới kiến trúc cơ bản vững chắc để giải quyết những điểm khó khăn thực sự nhất của các nhà phát triển và người dùng doanh nghiệp.
Từ sự xuất hiện của mô hình suy luận R1 đến V4, lần đầu tiên đẩy các khả năng ngữ cảnh dài sang phạm vi bao quát, DeepSeek đã sử dụng một cách tương đối "chậm" để thực hiện một công việc khó khăn hơn - chuyển các chức năng mô hình hàng đầu từ một công cụ dành cho một số người thành cơ sở hạ tầng mà nhiều người có thể gọi trực tiếp là .