Lần này Ultraman không đứng lên nói: "Lần đầu tiên trải nghiệm, tôi sợ đến mức ngất xỉu và gục xuống. Giây phút đó giống như nhìn thấy một quả bom nguyên tử phát nổ vậy". Thay vào đó, anh ta thuê một nhóm người thay thế (những người dùng thử nghiệm sớm). Trong số đó có một kỹ sư Nvidia, người đã mất quyền truy cập vào GPT-5.5 trong thời gian ngắn sau khi thử nghiệm sớm và đã nói thế này:

Mất GPT-5.5 giống như bị mất GPT-5.5 một cuộc cắt cụt.
Hãy nói chuyện, hãy gây rắc rối.
Sự hợp tác giữa OpenAI và NVIDIA này là chưa từng có.
Đầu tiên, các hệ thống GPT-5.5 và NVIDIA GB200 và GB300 NVL72 được thiết kế chung. Từ đào tạo đến triển khai, mối quan hệ giữa mô hình và phần cứng đã diễn ra theo cả hai hướng kể từ khi nó ra đời.
Thứ hai, để quảng bá Codex cho toàn bộ công ty NVIDIA, Ultraman còn đăng một email với Lão Hoàng.
Trước tiên hãy nhìn vào kết quả của sự hợp tác.
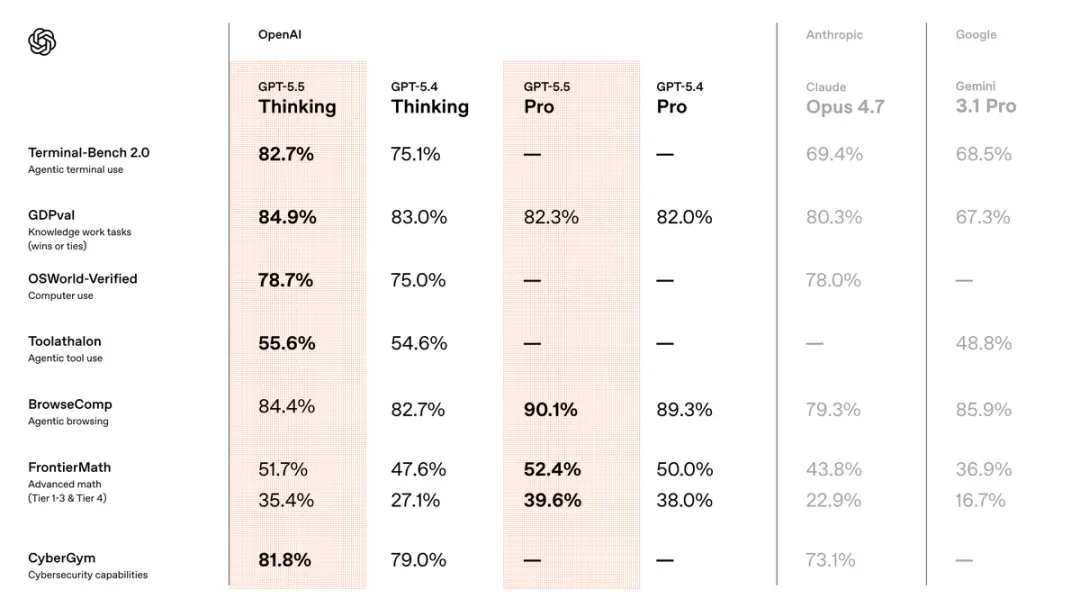
So với phiên bản GPT5.4 trước đó, mô hình mới đã dẫn đầu trong cả ba lĩnh vực: mã, công việc tri thức và nghiên cứu khoa học.
Kiểm tra toàn diệnKết quả chỉ số thông minh phân tích nhân tạo, có hai cách để diễn giải chúng:
GPT-5.5 đạt được cùng số điểm và tiêu thụ ít mã thông báo hơn hơn Claude Opus 4.7 và các mẫu khác.
Hoặc sử dụng cùng một mã thông báo, GPT-5.5 có thể hoàn thành nhiều nhiệm vụ hơn.
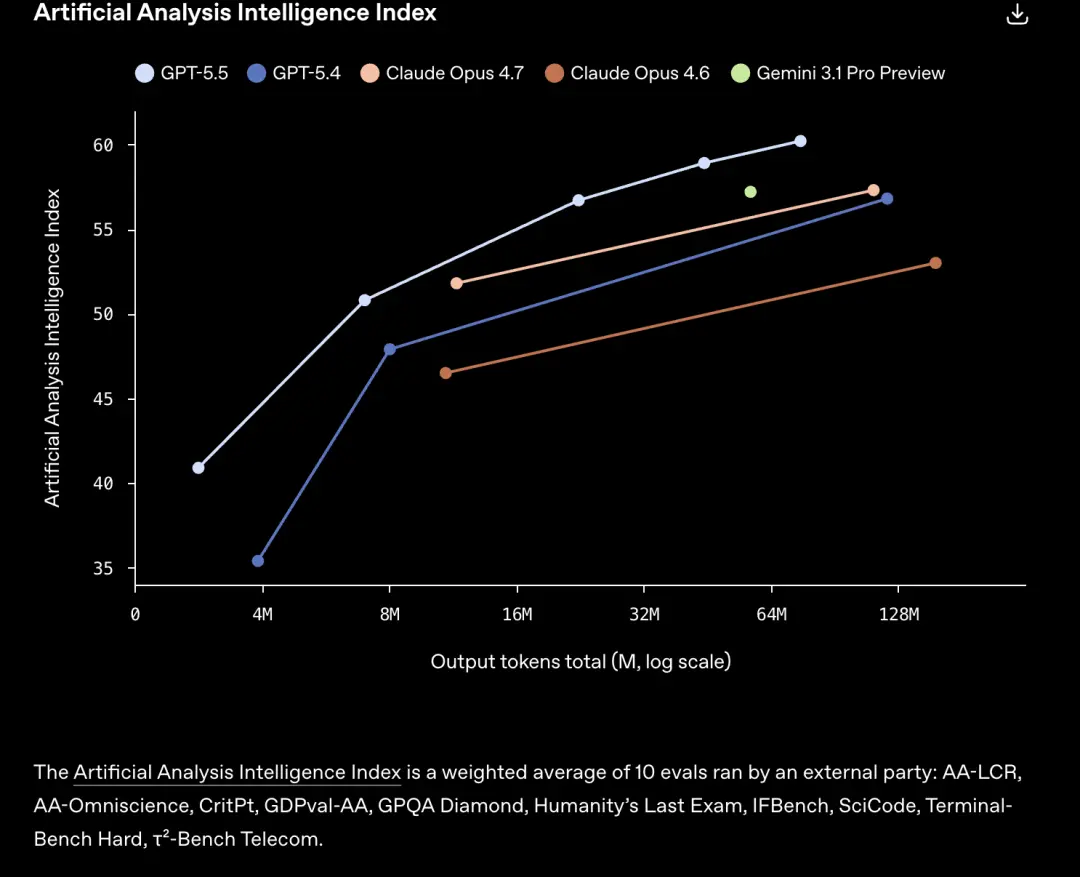
Nhưng điều đáng ngạc nhiên nhất không phải là điểm chạy.
Trước đây, mọi nâng cấp mẫu máy, “mạnh hơn” và “chậm hơn” hầu như đều được bán theo gói.
Đây là giá của Luật Scaling, model lớn hơn, nhiều thông số hơn và thời gian suy nghĩ lâu hơn. Khi người dùng trả tiền cho thông tin, họ cũng phải trả tiền cho sự chậm trễ.
GPT-5.5 vi phạm luật sắt này.
Trong môi trường sản xuất thực, độ trễ từng mã thông báo của nó tương đương với GPT-5.4 và cần ít mã thông báo hơn để hoàn thành cùng một nhiệm vụ so với GPT5.4.
hiệu quả hơn và mạnh mẽ hơn.
(nhưng giá gấp đôi)

Tính đến thời điểm báo chí, phiên bản mới nhất của Codex đã được cập nhật để sử dụng GPT-5.5.
Cửa sổ ngữ cảnh cũng được nâng cấp lên 400K
TAGP H115
Lập trình hack
Lập trình là lĩnh vực mà GPT-5.5 đã cải thiện nhiều nhất.
Khi sử dụng model thế hệ trước, bạn vẫn phải chia nhỏ các nhiệm vụ một cách cẩn thận, theo dõi từng bước và sẵn sàng sửa sai lệch bất cứ lúc nào.
GPT-5.5 thì khác. Bạn ném các yêu cầu sang một bên và nó sẽ tự tháo rời, thực thi và kiểm tra. Bạn chỉ cần nhìn vào kết quả.
OpenAI đã trình diễn trò chơi hành động 3D do GPT-5.5 tạo ra trong Codex, chạy trực tiếp trên trang web.
Bao gồm việc sử dụng TypeScript/Three.js để triển khai hệ thống chiến đấu, các cuộc chạm trán với kẻ thù, phản hồi HUD và kết cấu môi trường do GPT tạo.
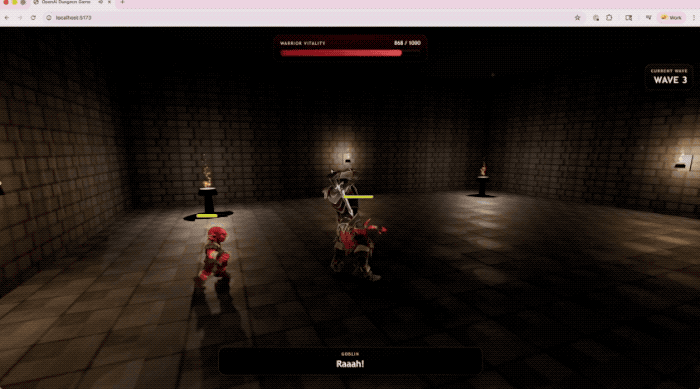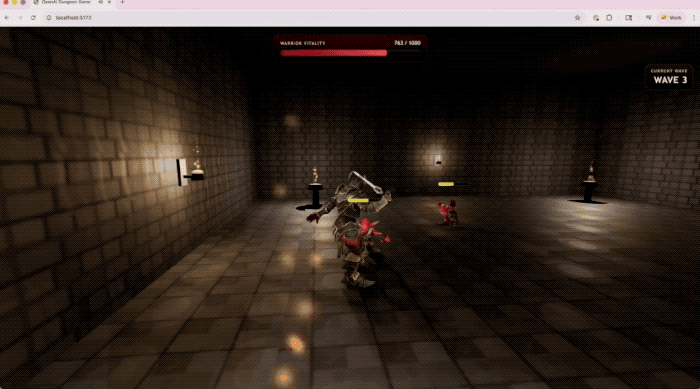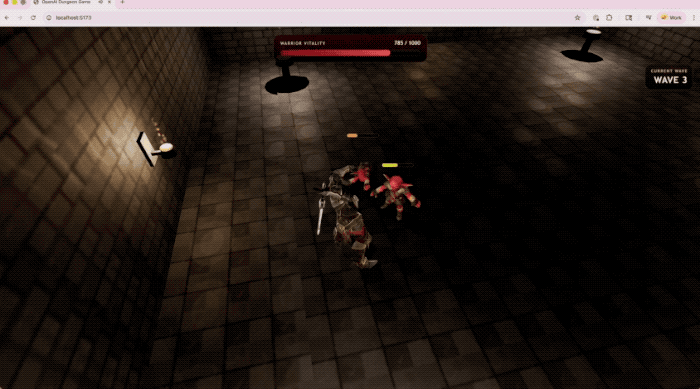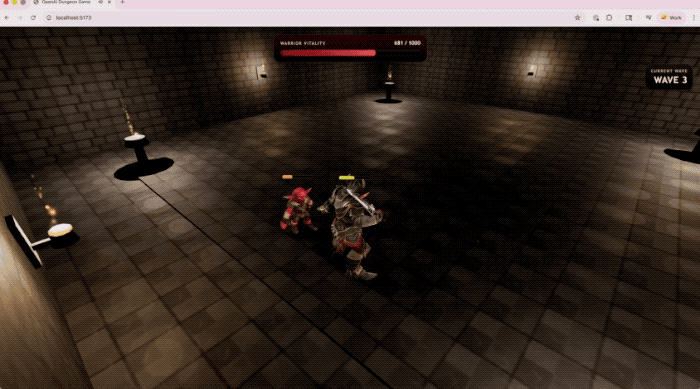
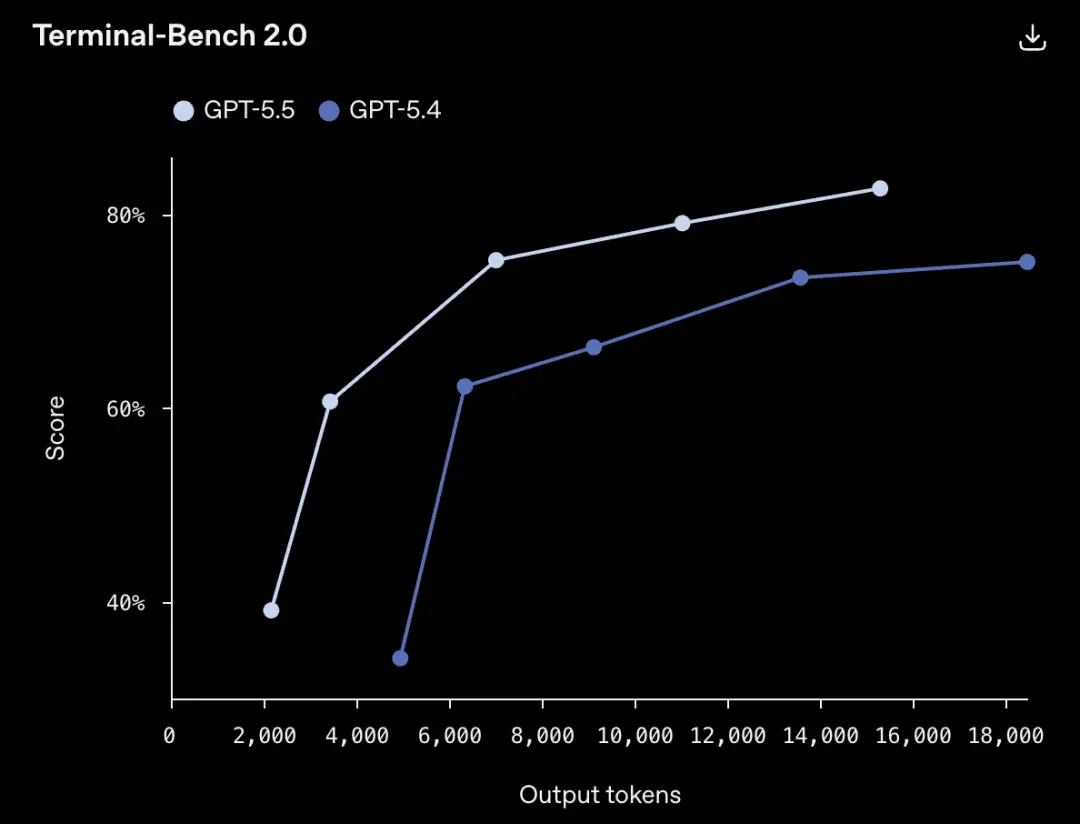
Thiết bị đầu cuối-Bàn ghế 2.0, một bài kiểm tra cốt lõi để đo lường quy trình làm việc dòng lệnh phức tạp, GPT-5.5 đạt 82,7%.
Phiên bản trước đây của GPT-5.4 là 75,1% và đối thủ cạnh tranh mạnh nhất hiện tại, Claude Opus 4.7, là 69,4%.
Có thể hiểu, khi gặp mức độ khó này, gần 1/3 số mẫu xe thế hệ trước sẽ mắc kẹt nhưng hiện nay tỷ lệ này đã giảm xuống chỉ còn chưa đến 1/4.
Tiếp theo, mời các bạn cho ý kiến:
Người thử nghiệm ban đầu Dan Shipper đã thực hiện một thí nghiệm. Anh ấy là CEO khởi nghiệp và là nhà phát triển sản phẩm AI tích cực.
Ứng dụng của anh ấy sau khi ra mắt đã xảy ra lỗi nên anh ấy đã thuê một kỹ sư hàng đầu để xây dựng lại nó. Các kỹ sư đã làm việc chăm chỉ và cuối cùng đã tìm ra giải pháp.
Sau đó Shipper quay ngược đồng hồ: ném mã lỗi vào mô hình và xem liệu mô hình có thể độc lập đưa ra quyết định tương tự như kỹ sư hay không.
GPT-5.4 không thể làm được. GPT-5.5 đã làm được điều đó.
Shipper cho biết đây là lần đầu tiên anh cảm nhận được "sự rõ ràng về khái niệm" thực sự trong một mô hình lập trình.
Vấn đề không phải là trả lời cuộc gọi mà là hiểu rõ vấn đề và tìm ra cách giải quyết nó.

Ngày càng có nhiều kỹ sư cấp cao báo cáo điều tương tự: GPT-5.5 mạnh hơn đáng kể so với GPT-5.4 và Claude Opus 4.7 về lý luận và quyền tự chủ.
Nó phát hiện sớm các vấn đề và dự đoán nhu cầu kiểm tra và đánh giá mà không cần nhắc nhở rõ ràng.

Lập trình chỉ là bước khởi đầu. Bước nhảy vọt về năng lực tương tự đang lan rộng sang cả công việc tri thức và nghiên cứu khoa học.
Ngoài lập trình
GPT-5.5 Những gì bạn làm trong Codex không chỉ đơn thuần là viết chương trình. Tạo tài liệu, sắp xếp biểu mẫu và tạo PPT.
OpenAI đã nhiều lần nhấn mạnh rằng nó hiểu rõ bạn muốn gì hơn thế hệ trước.
Quan trọng hơn, sẽ sử dụng các công cụ của riêng mình và kiểm tra xem đầu ra có chính xác hay không. Bạn cho tôi một ý tưởng mơ hồ và nó có thể giúp bạn điền vào phần còn lại.
Có dữ liệu thú vị ở đây. Hơn 85% nhân viên của OpenAI sử dụng Codex để làm việc hàng tuần. (Chuyện gì đang xảy ra với 15% còn lại?)
Trước tiên hãy xem kết quả đánh giá.
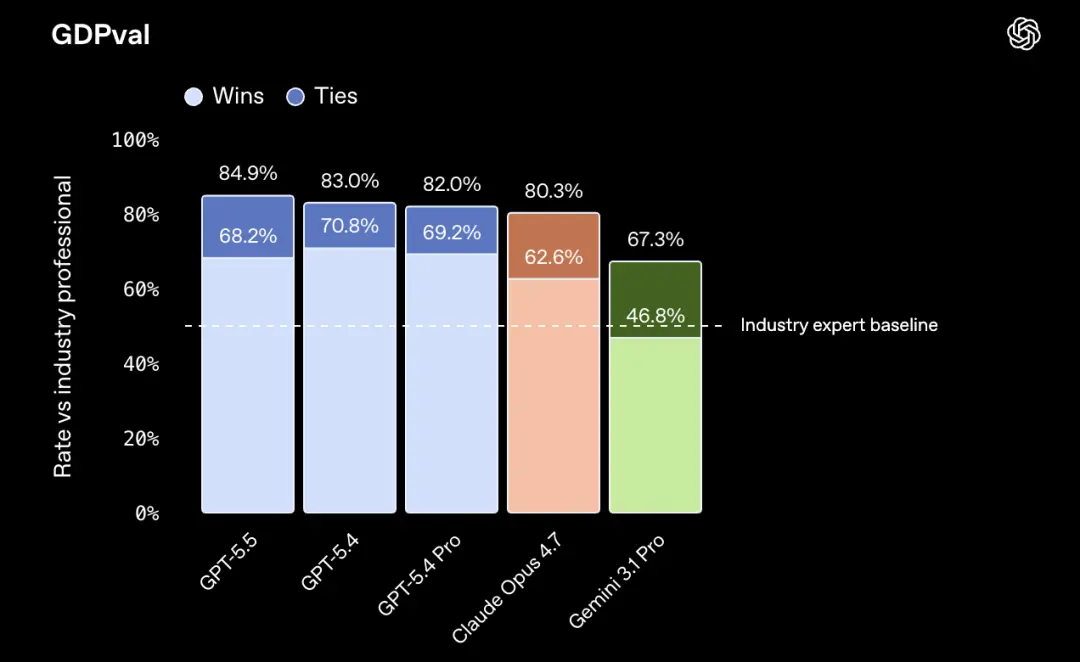
Trên điểm chuẩn công việc tri thức GDPval, GPT-5.5 đạt 84,9%, cao hơn 4,6 điểm phần trăm so với Claude Opus 4.7.
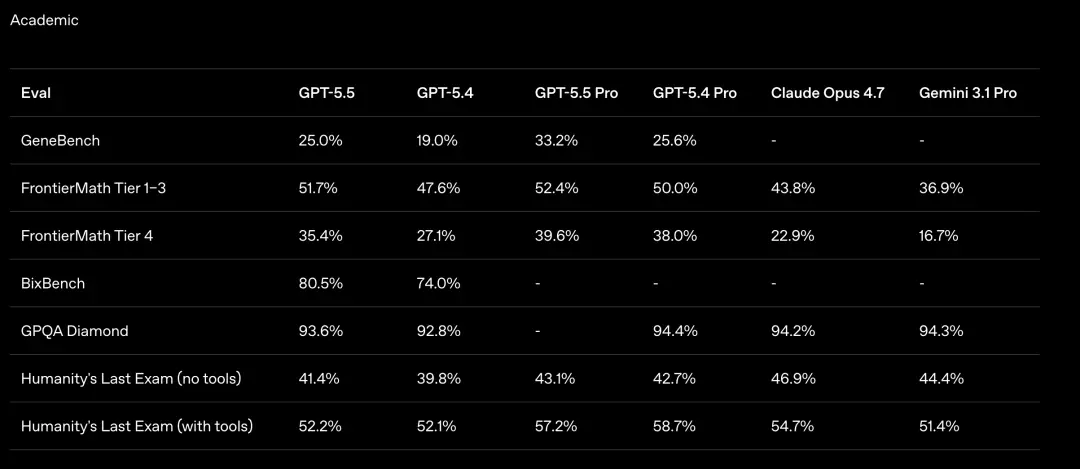
FrontierMath Cấp 4. Một trong những điểm chuẩn toán học khó nhất hiện nay, các câu hỏi đến từ các bài báo chưa được xuất bản và các bài toán mở từ các nhà nghiên cứu hàng đầu.
GPT-5.5 Pro đạt 39,6% trong bài kiểm tra này. Claude Opus 4.7 là 22,9%, khoảng cách gần gấp đôi.
Điều thực sự thú vị là cách các nhà khoa học sử dụng nó.
Bartosz Naskręcki là Trợ lý Giáo sư Toán học tại Đại học Adam Mickiewicz, Ba Lan. Anh ấy viết một câu vào Codex và 11 phút sau, một ứng dụng trực quan hóa hình học đại số đang chạy.
Ứng dụng này có thể vẽ đường giao nhau của hai mặt bậc hai được đánh dấu màu đỏ và cũng có thể sử dụng định lý Riemann-Roch để chuyển đường giao nhau thành dạng chuẩn của đường cong Weierstrass. Sau đó, ông đã mở rộng nó với khả năng hình dung điểm kỳ dị ổn định hơn.
Một câu, 11 phút. Trước đây, chỉ cần thiết lập khung dự án sẽ mất nửa ngày.

Derya Unutmaz là Giáo sư Miễn dịch học tại Phòng thí nghiệm Y học Gen Jackson. Anh đã sử dụng GPT-5.5 Pro để phân tích bộ dữ liệu biểu hiện gen: 62 mẫu, gần 28.000 gen. Cuối cùng, một báo cáo nghiên cứu hoàn chỉnh đã được thực hiện.
Ông ấy nói rằng nhóm sẽ phải mất vài tháng.
Định vị GPT-5.5 của OpenAI trong nghiên cứu khoa học có thể được tóm tắt chính xác trong một câu. Nó không còn giống như một công cụ trả lời một lần nữa mà giống như một "đối tác nghiên cứu" hơn.
Những người thử nghiệm ban đầu sử dụng nó để làm nhiều việc hơn là chỉ tra cứu thông tin. Nhiều vòng sửa bài, lần lượt xác định những sơ hở trong lập luận và đề xuất phương án phân tích mới. Nó ghi nhớ toàn bộ bối cảnh nghiên cứu của bạn và mỗi cuộc trò chuyện được xây dựng dựa trên cuộc trò chuyện trước đó.
GPT-5.5 đã làm được một điều lớn lao trong lĩnh vực toán học.
Số Ramsey , một trong những bài toán cốt lõi của toán học tổ hợp.
Theo thuật ngữ thông thường, nó nghiên cứu: Mạng phải lớn đến mức nào để đảm bảo rằng một trật tự nhất định chắc chắn sẽ xuất hiện?
Ví dụ: ba trong số sáu người phải biết nhau hoặc ba người không được biết nhau. Đây là định lý Ramsey đơn giản nhất.
Nó đã là một vấn đề khó hiểu trong lĩnh vực toán học trong nhiều thập kỷ và tính chất tiệm cận của số Ramsey ngoài đường chéo vẫn chưa được giải quyết trong một thời gian dài.
GPT-5.5 tìm thấy đường dẫn chứng minh mới. Thay vì sao chép lại một phương pháp đã biết, chúng tôi đã khám phá ra một con đường mới. Sau đó, bằng chứng này đã được xác nhận bởi Lean, một trong những công cụ xác minh hình thức nghiêm ngặt nhất trong toán học.

Một AI đã có những đóng góp ban đầu được xác minh bằng các công cụ chính thức trong lĩnh vực cốt lõi của toán học thuần túy.
Một năm trước, điều này là không thể tưởng tượng được.
Bí quyết để mạnh hơn nhưng không nhanh hơn
Làm thế nào để đạt được "mạnh hơn nhưng nhanh hơn"?
Câu trả lời không phải là tối ưu hóa một liên kết nhất định. OpenAI đã đảo ngược toàn bộ hệ thống lý luận và bắt đầu lại.
Như đã đề cập trước đó, các hệ thống GPT-5.5 và NVIDIA GB200 và GB300 NVL72 được thiết kế chung. Kết quả là, trong cùng một độ trễ, mức độ tình báo đã tăng vọt đáng kể.
Nhưng còn một câu chuyện khác.
Hệ thống Codex điều khiển GPT-5.5 đã phân tích dữ liệu lưu lượng truy cập sản xuất trong vài tuần và sau đó viết thuật toán heuristic phân vùng cân bằng tải. Trước
, các yêu cầu được chia thành một số phần cố định và được phân phối tới bộ tăng tốc để xử lý. Tuy nhiên, chiến lược phân đoạn cố định không phải lúc nào cũng tối ưu trong các mô hình lưu lượng truy cập khác nhau. Đôi khi các khối được chia quá thô, đôi khi quá mỏng và tỷ lệ sử dụng tài nguyên cao và thấp.
Codex đã xem xét dữ liệu lưu lượng truy cập thực tế trong vài tuần và viết một bộ thuật toán phân vùng thích ứng. Tự động điều chỉnh chiến lược chặn dựa trên mô hình lưu lượng truy cập thực tế.
Tốc độ tạo mã thông báo đã tăng hơn 20%.
Mô hình này tối ưu hóa cơ sở hạ tầng để tự chạy và AI đang khiến bản thân chạy nhanh hơn.
Việc tái thiết tổng thể hệ thống suy luận, cùng với sự tham gia của mô hình vào quá trình tối ưu hóa của chính nó, hai điều này đã chồng chéo lên nhau để mang lại kết quả như vậy.

OpenAI cho biết đây là "một bước hướng tới một cách mới để hoàn thành công việc với máy tính".
Nhưng khi mô hình đã bắt đầu tối ưu hóa cơ sở hạ tầng cho hoạt động của chính mình -
Nó đã đi được bao xa?
Một điều nữa
Với GPT-5.5, OpenAI kỳ vọng rằng dữ liệu phát hành mô hình sẽ được tăng tốc trong tương lai.
Chúng tôi nhận thấy tiến bộ khá đáng kể trong ngắn hạn và tiến bộ cực kỳ đáng kể trong trung hạn.
Tôi nghĩ rằng tiến độ đã chậm lại một cách đáng kinh ngạc trong vài năm qua.
Nhà khoa học trưởng Jakub Pachocki đã nói điều này trong cuộc gọi hội nghị với các phóng viên.