GPT Image2 làm mới toàn bộ mạng nhưng tại sao hiệu quả lại tốt đến vậy? Trưởng nhóm nghiên cứu Chen Boyuan tiết lộ: Kiến trúc cơ bản đã được xây dựng lại hoàn toàn. Nhưng anh ta từ chối trả lời liệu anh ta sử dụng mô hình khuếch tán hay công nghệ tự hồi quy, và chỉ mô tả nó một cách bí ẩn là "mô hình phổ quát" hay "GPT trong trường hình ảnh".


Một tweet của Chen Boyuan cũng tiết lộ điều đó từ Hình ảnh GPT vào cuối tháng 12 năm ngoái Bắt đầu từ 1.5, chỉ mất bốn tháng để đạt được sự cải tiến lớn như vậy.

Thành tích đột phá như vậy có đội ngũ nòng cốt chỉ có 13 người.
Gabriel Goh, trưởng nhóm của toàn đội, đã đăng ảnh gia đình của các thành viên trong nhóm AI.

Một số cư dân mạng trong khu vực bình luận đã than thở: Tại sao họ đều là người châu Á?

Chen Boyuan: Từ không biết Python đến Trưởng nhóm nghiên cứu
Chính xác thì điều gì là kiến trúc của GPT Image 2?
OpenAI có thể không được công bố trong một thời gian dài, nhưng có thể thấy một số dấu vết từ kinh nghiệm học tập của các thành viên nhóm nòng cốt.
Chen Boyuan là trưởng nhóm nghiên cứu của nhóm. Anh và một thành viên khác Kiwhan Song có cùng người cố vấn Vincent Sitzmann khi họ đang học Tiến sĩ. tại MIT.

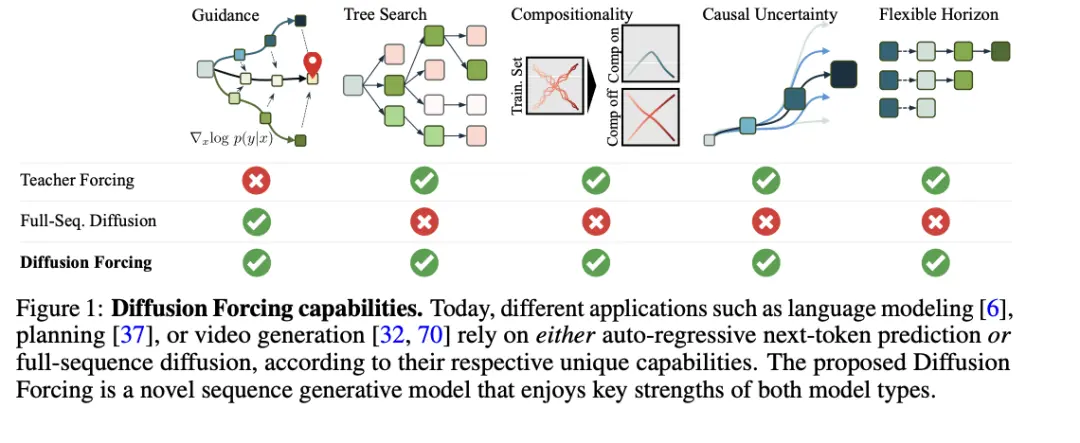
Kiệt tác của anh ấy là Lực khuếch tán: Dự đoán mã thông báo tiếp theo đáp ứng Khuếch tán toàn chuỗi trong quá trình tiến sĩ của anh ấy đã được chọn cho NeurIPS 2024.
Nghiên cứu này đề xuất Cưỡng bức khuếch tán, một mô hình đào tạo tạo chuỗi mới, kết hợp khuếch tán mức nhiễu độc lập theo từng mã thông báo với dự đoán mã thông báo tiếp theo theo nguyên nhân, tích hợp khả năng tạo độ dài thay đổi của mô hình tự hồi quy và các ưu điểm hướng dẫn tầm xa của mô hình khuếch tán chuỗi đầy đủ.
Trong thời gian thực tập tại Google, anh cũng đã xuất bản SpatialVLM với tư cách là đồng tác giả.
Bằng cách tự động xây dựng bộ dữ liệu VQA suy luận không gian 3D trên quy mô Internet (10 triệu hình ảnh, 2 tỷ cặp QA), mô hình ngôn ngữ hình ảnh được trang bị khả năng suy luận không gian định lượng/định tính, có thể xuất ra các giá trị chính xác như khoảng cách hệ mét, kích thước và hướng từ một hình ảnh 2D duy nhất.
Nghiên cứu này áp dụng lý luận không gian chuỗi tư duy vào lĩnh vực trí tuệ hiện thân.

Trong thời gian thực tập tại Google, công nghệ tinh chỉnh hướng dẫn mà anh phát triển sau đó đã được Gemini 2.0 áp dụng.
Khi tham gia trại hè nghiên cứu khoa học ở trường trung học, anh ấy không hiểu cú pháp cơ bản của Python. Xia Fei, một nhà nghiên cứu cấp cao tại Google DeepMind mà anh đã gặp vào thời điểm đó, đã giới thiệu anh với thế giới AI.
Xia Fei đã hai lần mời anh ấy tham gia khóa thực tập chất lượng cao tại DeepMind. Những kinh nghiệm này đã giúp Chen Boyuan tích lũy kinh nghiệm kỹ thuật trong đào tạo mô hình quy mô lớn, đồng thời cung cấp cho anh góc nhìn có giá trị để hiểu các yêu cầu dữ liệu của hệ thống đa phương thức.
Sau khi tốt nghiệp Tiến sĩ, Chen Boyuan gia nhập OpenAI vào tháng 6 năm 2025 và nhanh chóng trở thành một trong năm thành viên cốt lõi của thế hệ hình ảnh GPT. Anh chịu trách nhiệm đào tạo toàn bộ mô hình tạo hình ảnh GPT và cũng là thành viên của nhóm tạo video Sora.
Trong cuộc biểu tình, anh đã làm một tấm áp phích cho quê hương Vô Tích của mình. Sau đó, tôi làm áp phích tiếng Hàn cho các đồng đội của mình ở Seoul và áp phích tiếng Bengali cho các đồng đội của tôi ở Bangladesh. Việc hiển thị văn bản trong mỗi cái là chính xác.

Jianfeng, Đại học Khoa học và Công nghệ Trung Quốc Wang: Hãy để Shengtu AI hiểu kiến thức thế giới
Jianfeng Wang, bằng tiến sĩ. tốt nghiệp Đại học Khoa học và Công nghệ Trung Quốc, chịu trách nhiệm về một khả năng đáng kinh ngạc khác trong nhóm GPT Image 2: làm theo hướng dẫn và hiểu biết về thế giới.

Đồng hồ vĩnh cửu được vẽ bởi mẫu cũ luôn chỉ 10:10. Nó bắt nguồn từ những hình ảnh quảng cáo đồng hồ trên Internet. Hầu như tất cả đều là 10:10.
Điều này là do các nhà sản xuất đồng hồ đã yêu cầu các nhà tâm lý học tiến hành các thí nghiệm vì tin rằng điều này sẽ giúp kích thích sự sẵn lòng mua đồng hồ của người tiêu dùng.

Anh ấy đã vẽ mô hình mới 2:25, 3:30, 9:10, 7:45, tất cả đều chính xác.

Đây chỉ là món khai vị thôi.
Bố cục không gian phức tạp hơn, quả táo ở giữa, cốc ở bên phải, sách ở trên cùng, camera ở bên trái, bóng rổ ở phía dưới. Các mô hình đều được thực hiện chính xác.

Trước khi gia nhập OpenAI, ông đã làm việc tại Microsoft gần 9 năm. Khi ở Microsoft, tôi đã cộng tác với nhóm OpenAI trên DALLE-3.
Ông đã xuất bản một số bài báo học thuật trong lĩnh vực thị giác máy tính. Nội dung nghiên cứu của ông có thể bao gồm phân loại hình ảnh, phát hiện mục tiêu, phân đoạn ngữ nghĩa và học cách trình bày hình ảnh.
Cải thiện đáng kể về hiểu biết kiến thức thế giới, nội dung ngữ nghĩa và cấu trúc chức năng của các đối tượng Có hiểu biết chính xác
JianFeng Wang đã nói ở cuối video trình diễn: GPT Image 2 đang xóa bỏ khoảng cách giữa ý định của bạn và đầu ra mô hình.
Hãy thực sự làm những gì bạn muốn, người mẫu sẽ cho bạn những gì bạn muốn.
Yuguang Yang: Tạo đồ họa thông tin phức tạp có độ chính xác cao
Yuguang Yang đã trình diễn cách tạo đồ họa thông tin và PPT tại sự kiện ra mắt GPT Image 2.

Kéo toàn bộ bài báo GPT-3 dài 75 trang vào ChatGPT và tự động tạo 7 slide.
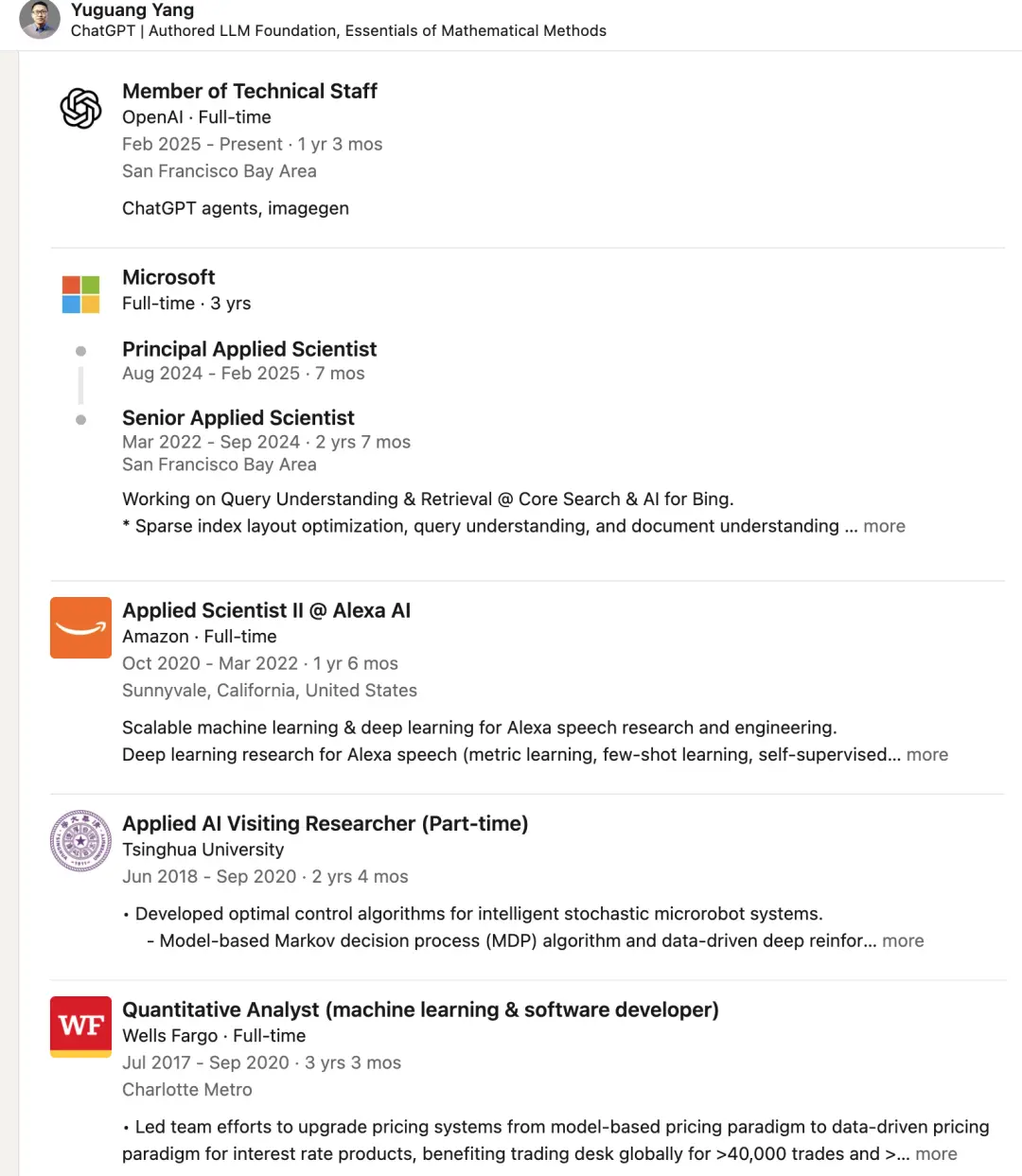
Kinh nghiệm của anh ấy có thể nói là phong phú nhất trong số các thành viên trong nhóm. Mọi công việc anh đảm nhận đều là công việc xuyên biên giới, nhưng tất cả đều tập trung vào học máy.
Anh ấy học kỹ thuật tại Cao đẳng Zhu Kezhen thuộc Đại học Chiết Giang để lấy bằng đại học và nghiên cứu vật lý hóa học tính toán và học máy trong thời gian lấy bằng Tiến sĩ. tại Đại học Johns Hopkins.
Công việc toàn thời gian đầu tiên của anh ấy là nhà phân tích định lượng. Trong thời gian làm nhà nghiên cứu thỉnh giảng tại Đại học Thanh Hoa, Ya Niu đang nghiên cứu các thuật toán điều khiển và học tập tăng cường cho robot nano.
Sau đó, anh ấy đã nghiên cứu giọng nói của Alexa tại Amazon.
Tôi cũng đã làm việc về hiểu và truy xuất truy vấn tìm kiếm Bing cũng như hiểu tài liệu tại Microsoft.
Sau khi gia nhập OpenAI vào đầu năm 2025, ngoài việc tạo hình ảnh, anh còn tham gia vào dự án đại lý ChatGPT.
Anh ấy đã giới thiệu khả năng tạo đồ họa thông tin của GPT Image 2 trên tài khoản cá nhân của mình, điều này có thể tiết kiệm rất nhiều thời gian cho các nhà nghiên cứu khoa học.
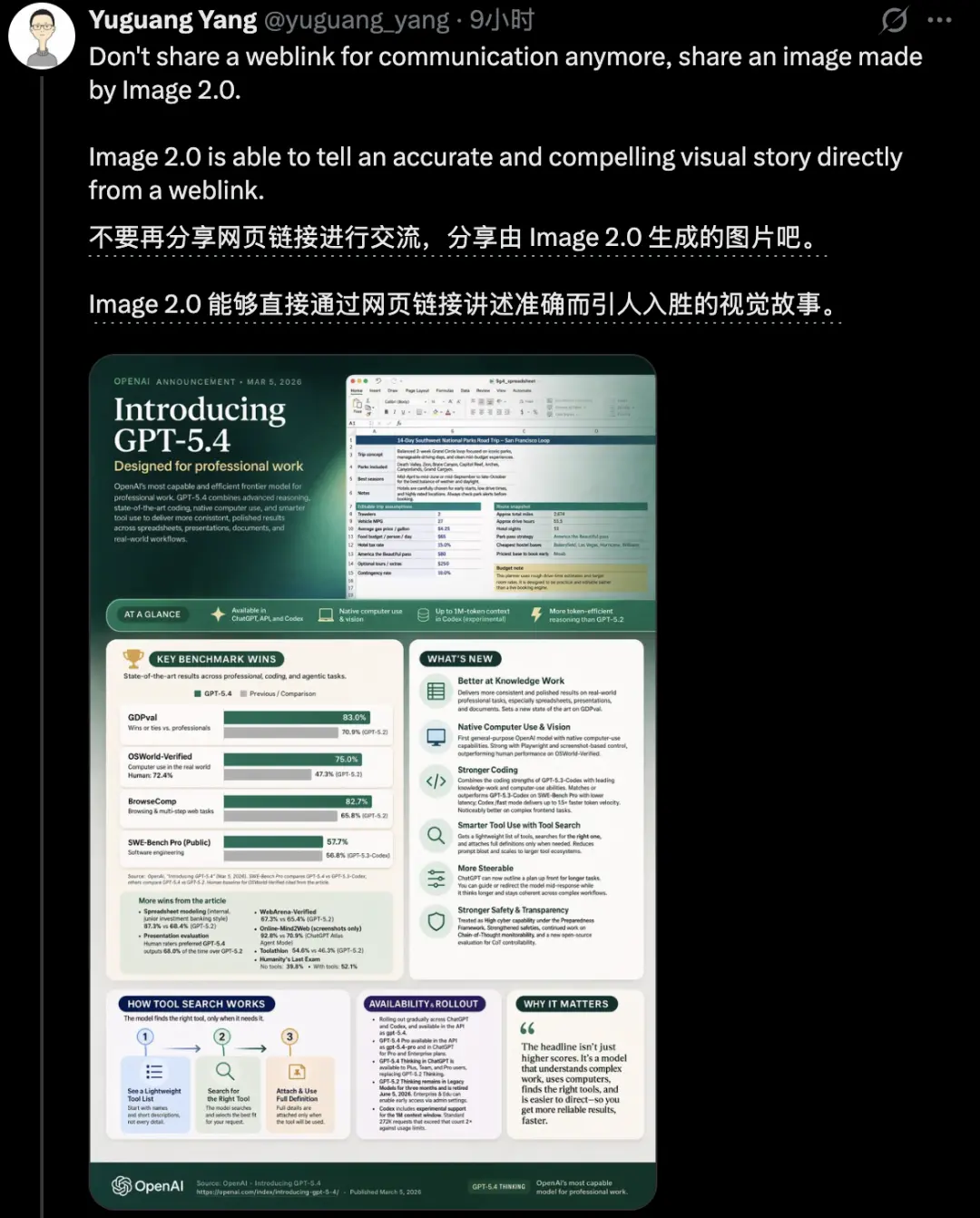
Tôi cũng nhiều lần nhắc nhở mọi người đừng quên chọn chế độ tư duy khi làm đồ họa thông tin.
Từ DALL-E đến Hình ảnh GPT 2.0
Từ thành viên nhóm Kenji Từ phần tự giới thiệu của Hata, chúng tôi đã biết được rằng Hình ảnh GPT 1.0 là phần tạo hình ảnh của GPT-4o.
Có một người đã tham gia vào toàn bộ loạt nghiên cứu đa phương thức OpenAI kể từ DALL-E.
Anh ấy là Gabriel Goh, trưởng nhóm GPT Image 2.0.
Gia nhập OpenAI vào năm 2019. Nghiên cứu ban đầu của anh thiên về lý thuyết hơn, tập trung vào khả năng diễn giải và tối ưu hóa lồi, v.v.
Bắt đầu từ DALL-E, dần dần chuyển sang tạo hình ảnh.

Nhìn thấy sơ yếu lý lịch nghiên cứu của một thành viên khác trong nhóm Weixin Liang, nền tảng kỹ thuật của GPT Image 2 đã được tiết lộ.
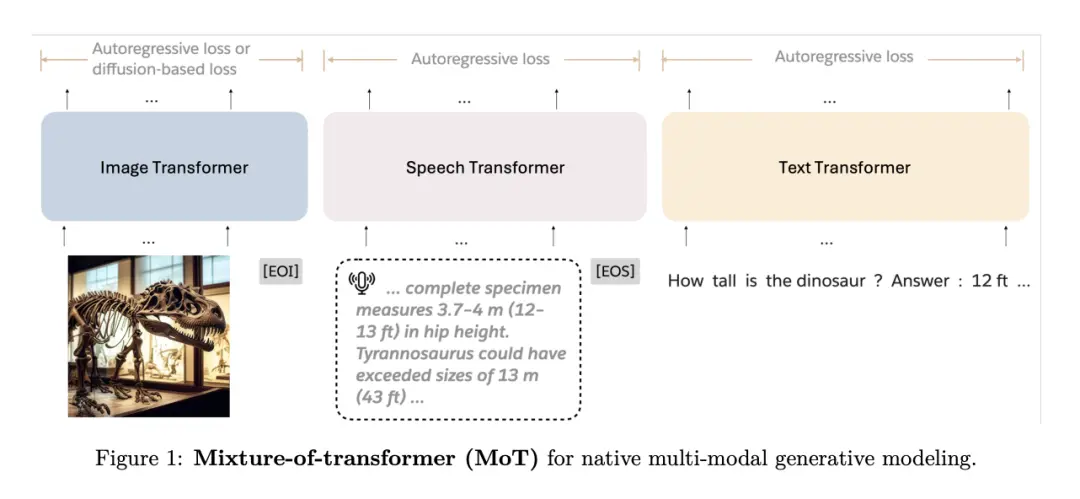
Công việc tiêu biểu của anh ấy trong thời gian thực tập tại Meta, Mixture-of-Transformers, đã giới thiệu MoE tách rời phương thức và sự chú ý tách rời, giảm đáng kể chi phí tính toán của quá trình đào tạo trước mô hình đa phương thức.
Anh ấy tốt nghiệp Stanford với bằng tiến sĩ và bằng đại học tại Đại học Zhukezhen của Đại học Chiết Giang, nhưng anh ấy muộn hơn Yuguang Yang vài năm.
Weixin Liang, giống như Chen Boyuan, đã gia nhập OpenAI ngay sau khi tốt nghiệp Tiến sĩ. sau 25 năm và nhanh chóng trở thành thành viên cốt lõi của đội.
Các thành viên khác của nhóm GPT Image 2.0 bao gồm:
Ayaan Haque, trước đây ở Luma AI Tại nơi làm việc, tôi đã tham gia đào tạo Dream Machine, Mô hình tạo video cơ bản của Luma.
Bing Liang đã làm việc tại Google hơn 5 năm, tham gia Imagen3, Veo và Gemini Multimodal. Năm 2025, anh chuyển sang OpenAI để thực hiện nghiên cứu về tạo hình ảnh.
Mengchao Zhong, cựu sinh viên Đại học Giao thông Thượng Hải với bằng cử nhân và bằng thạc sĩ của Đại học Texas A&M. Anh từng làm kỹ sư phần mềm tại Pinterest và Airtable, đồng thời chịu trách nhiệm phát triển các sản phẩm đa phương thức tại OpenAI.
Dibya Bhattacharjee, Đại học Yale, Huy chương Đồng IPhO năm 2015, điểm cao nhất thế giới ở môn Toán và Sinh học CIE A-Level.
Kiwhan Song là người cuối cùng tham gia vào tháng 10 năm 2025. Ngoài việc nghiên cứu, anh ấy còn là người nhanh nhẹn trong nhóm. Nhiều hình ảnh trình diễn chính thức mà bạn nhìn thấy là của anh ấy.
……
Từ DALL-E đầu tiên đến GPT Image 2.0 ngày nay, nhóm này đã giải quyết hết vấn đề này đến vấn đề khác. Bạn có thể vẽ rõ ràng, vẽ đẹp và vẽ chính xác.

Mặc dù OpenAI đã chứng kiến một lượng lớn nhân tài trong những năm gần đây, OpenAI vẫn là công ty có thể tiếp tục thu hút nhân tài với nhiều tính cách khác nhau, không giới hạn chuyên ngành, hoan nghênh nghiên cứu xuyên biên giới và tin tưởng vào nghiên cứu mới nổi từ dưới lên.
Bắt đầu từ một nhóm nhỏ. Sau bước đột phá, công ty dành nhiều nguồn lực hơn cho đến khi thay đổi được thế giới.
Thêm một điều nữa
Ngày xửa ngày xưa, thế hệ hình ảnh GPT-4o đã gây bão trên toàn thế giới bằng cách bắt chước các hình đại diện theo phong cách Ghibli.
Hiện nay các thành viên trong nhóm GPT Image 2.0 đã thay đổi hình đại diện của mình sang kiểu cổ lạ này.
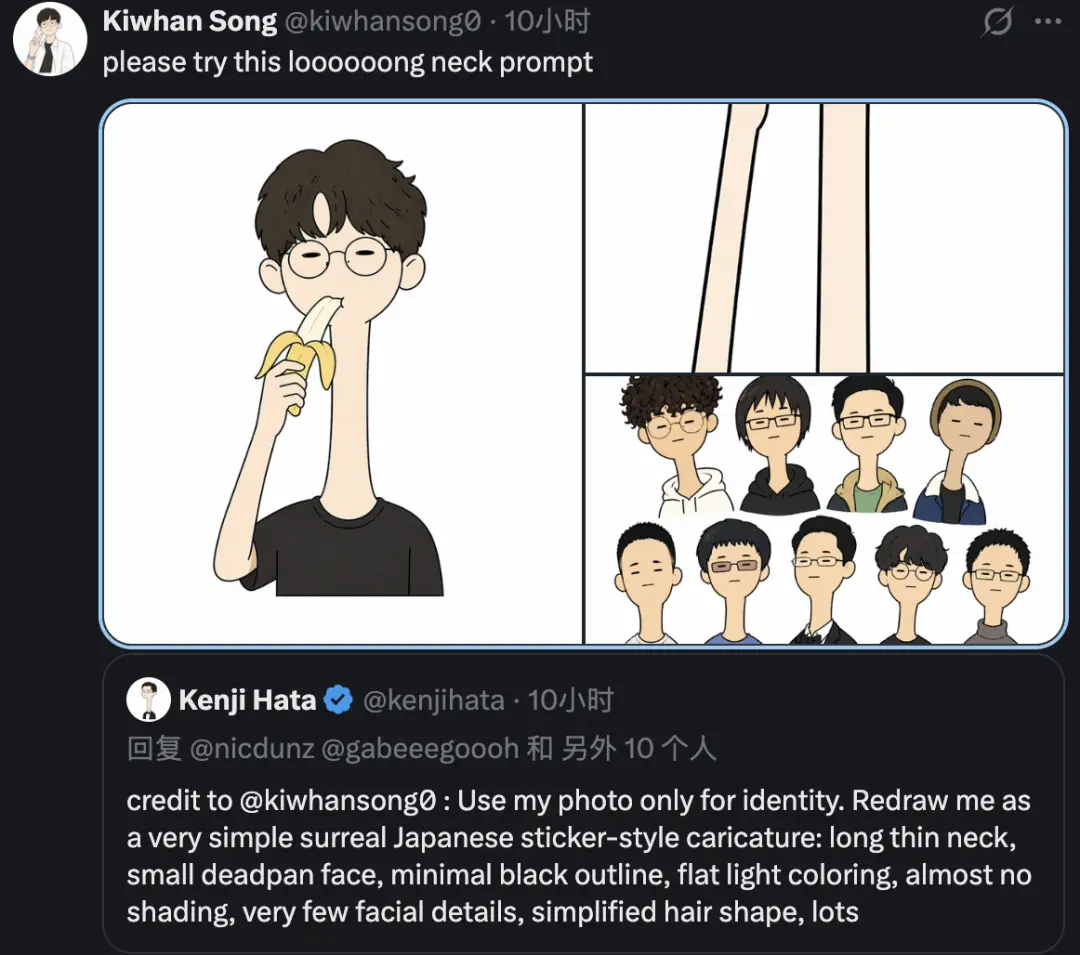
Vậy đâu là manh mối cho phong cách vẽ tranh này? Các thành viên trong nhóm cũng đã được công bố
Chỉ sử dụng ảnh của tôi để nhận dạng. Vẽ lại tôi như một bức tranh biếm họa kiểu nhãn dán siêu thực rất đơn giản của Nhật Bản: cổ dài gầy, khuôn mặt nhỏ nhắn, đường viền màu đen tối thiểu, màu sáng phẳng, hầu như không có bóng, rất ít chi tiết trên khuôn mặt, hình dạng tóc đơn giản, nhiều khoảng trắng, nền trắng trơn, hơi lúng túng và hài hước. Hình ảnh siêu cao 1:3.
Link tham khảo:
[1]https://x.com/gab eeegoooh/status/2046674385407512687?s=20
[2]https://ventureb eat.com/technology/openais-chatgpt-images-2-0-is-here-and-it-does-multilingual-text-full-infographics-slides-maps-even-manga-seemingly-hoàn hảo