DeepSeek đã phát hành mô hình lý luận đa phương thức và báo cáo kỹ thuật trên GitHub, có tiêu đề "Suy nghĩ bằng Visual Primitives (Suy nghĩ bằng Visual Primitives)". Mô hình này được xây dựng dựa trên DeepSeek V4-Flash (tổng tham số 284B, kiến trúc 13B MoE được kích hoạt trong quá trình suy luận) và đề xuất mô hình lý luận đa phương thức mới.

Bài viết chỉ ra rằng có một điểm nghẽn cơ bản trong các mô hình lớn đa phương thức hiện có đã bị bỏ qua: "khoảng cách tham chiếu" (Reference Gap), tức là mô hình có thể "nhìn thấy" nội dung của hình ảnh, nhưng khi sử dụng ngôn ngữ tự nhiên để xây dựng Một chuỗi suy nghĩ trong quá trình suy luận, những mô tả mơ hồ như vật thể lớn màu đỏ ở bên trái gần trung tâm không thể định vị chính xác vật thể thị giác trong một khung cảnh dày đặc, khiến sự chú ý bị trôi đi và đưa ra kết luận sai lầm.
Trước đây, hướng phản ứng chủ đạo trong cộng đồng học thuật là cải thiện độ phân giải nhận thức, nhưng bài báo tin rằng việc nhìn thấy và có thể nói rõ ràng những gì đang được nói là hai việc khác nhau.
Sự đổi mới cốt lõi của mô hình này là nhúng tọa độ điểm và các hộp giới hạn vào chính quá trình suy luận, biến chúng thành đơn vị cơ bản của chuỗi tư duy. Mỗi lần mô hình đề cập đến một đối tượng trực quan trong quá trình suy luận, tọa độ của nó sẽ được xuất ra một cách đồng bộ.
Ví dụ: "Tìm một con gấu [452, 23, 804, 411], trèo lên cây, loại trừ nó, sau đó nhìn xuống bên trái và tìm một con gấu khác [50, 447, 647, 771], đứng trên mép đá, đáp ứng các điều kiện." Tọa độ không còn là những câu trả lời được đánh dấu sau thực tế mà là những điểm neo không gian để loại bỏ sự mơ hồ trong quá trình suy luận.

Ở cấp độ kiến trúc, mô hình đạt được độ nén hình ảnh 7056 lần, hình ảnh 756×756 Sau khi xử lý ViT, 2916 mã thông báo khối hình ảnh đã được tạo, được hợp nhất thành 324 mã thông báo thông qua nén không gian 3×3. Bộ đệm KV đã được nén thêm 4 lần thông qua cơ chế Chú ý thưa thớt nén (CSA) và cuối cùng chỉ còn lại 81 mục nhập KV trực quan.
Để tham khảo, bức tranh cùng kích thước Claude Sonnet 4.6 cần khoảng 870 mảnh và Gemini-3-Flash yêu cầu khoảng 1100 mảnh.
Về dữ liệu đào tạo, nhóm đã sàng lọc khoảng 31.700 nguồn dữ liệu chất lượng cao từ gần 100.000 bộ dữ liệu phát hiện mục tiêu và tạo ra hơn 40 triệu mẫu đào tạo, bao gồm bốn loại nhiệm vụ: đếm, suy luận không gian, điều hướng mê cung và theo dõi đường đi.
Đào tạo sau áp dụng chiến lược chuyên môn hóa trước rồi mới thống nhất. Hai mô hình chuyên gia, hộp giới hạn và tọa độ điểm, được đào tạo riêng. Sau khi tối ưu hóa học tập tăng cường, chúng được hợp nhất thành một mô hình thống nhất thông qua việc chắt lọc chính sách trực tuyến.
Kết quả thử nghiệm được so sánh với các mẫu phổ thông như Gemini-3-Flash, GPT-5.4 và Claude Sonnet 4.6 trong 11 bài kiểm tra điểm chuẩn.
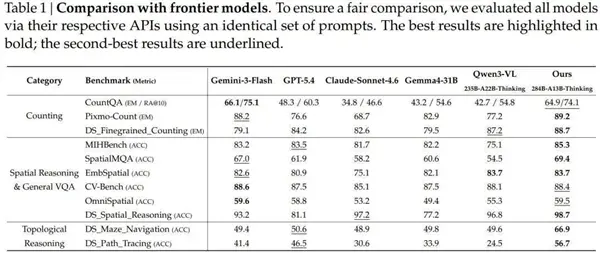
Về nhiệm vụ đếm, điểm đối sánh chính xác của Pixmo-Count là 89,2%, vượt quá 88,2% của Gemini-3-Flash và vượt xa đáng kể 76,6% của GPT-5.4 và 68,7% của Sonnet 4.6.
Khoảng cách tiêu biểu nhất xuất hiện trong lý luận tôpô: điểm điều hướng mê cung 66,9%, GPT-5.4 50,6%, Gemini-3-Flash 49,4%, Claude Sonnet 4,6 là 48,9%, tăng khoảng 17 điểm phần trăm; điểm theo dõi đường dẫn là 56,7% và GPT-5.4 là 46,5%.
Tuy nhiên, bài báo cũng chỉ ra những hạn chế hiện tại: mô hình cần kích hoạt rõ ràng các từ để kích hoạt cơ chế trực quan nguyên thủy, độ chính xác tọa độ trong các cảnh cực kỳ chi tiết còn hạn chế và vẫn còn chỗ để cải thiện khả năng khái quát hóa xuyên cảnh.
