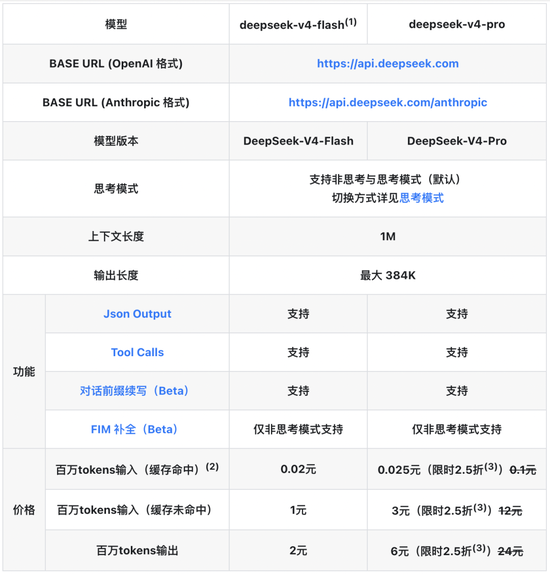
DeepSeek đang xác định lại ranh giới của việc đưa vào mô hình lớn. Ngày 26/4, DeepSeek chính thức đưa ra thông báo điều chỉnh giá API. Giá của tất cả các lần truy cập bộ đệm đầu vào API đã giảm xuống còn 1/10 giá ban đầu. Bản nâng cấp V4‑Pro được giảm giá 25% trong thời gian giới hạn và số lần truy cập bộ nhớ đệm đầu vào của một triệu Token chỉ ở mức 0,025 nhân dân tệ, thiết lập mức giá thấp mới cho các mẫu xe lớn trên thế giới.

Theo thông báo trên trang định giá API chính thức của DeepSeek, việc giảm giá này áp dụng cho tất cả các mẫu thuộc dòng V4 và các điều chỉnh cốt lõi tập trung vào các tình huống chạm vào bộ nhớ đệm đầu vào. Trong số đó, giá thành công của bộ nhớ đệm đầu vào DeepSeek-V4-Flash đã giảm từ 0,2 nhân dân tệ/triệu Token xuống 0,02 nhân dân tệ/triệu Token.
DeepSeek-V4-Pro dành cho người dùng cấp doanh nghiệp thậm chí còn được giảm giá nhiều hơn. Giá ban đầu của 1 nhân dân tệ/triệu Token giảm xuống còn 0,1 nhân dân tệ cho đầu vào bộ đệm. Ưu đãi đặc biệt giảm giá 25% trong thời gian giới hạn sẽ được thêm vào trước ngày 5 tháng 5 năm 2026. Giá thực tế chỉ là 0,025 nhân dân tệ/triệu token. Đầu vào bị thiếu bộ nhớ đệm giảm từ 12 nhân dân tệ xuống còn 3 nhân dân tệ và đầu ra giảm từ 24 nhân dân tệ xuống còn 6 nhân dân tệ.
Nguồn hình ảnh: Trang web chính thức của DeepSeekT AGPH60
DeepSeek đã đề cập rằng hai tên model DeepSeek-Chat và DeepSeek-Reasoner sẽ là không được dùng nữa trong tương lai. Vì lý do tương thích, cả hai đều tương ứng với chế độ không suy nghĩ và suy nghĩ của DeepSeek-V4-Flash.
So sánh giá trước và sau khi điều chỉnh giá, không khó để nhận thấy rằng chi phí cho các cuộc gọi tần suất cao và các kịch bản xử lý văn bản dài đã giảm hơn 90%. Các ứng dụng có tỷ lệ truy cập bộ đệm cao như cơ sở kiến thức RAG, dịch vụ khách hàng thông minh và phân tích tài liệu có thể trực tiếp đạt được mức giảm chi phí thương mại như vách đá, giúp phá vỡ xiềng xích chi phí khi triển khai AI trên quy mô lớn.
Việc giảm giá đáng kể của DeepSeek có liên quan đến việc nâng cấp công nghệ của DeepSeek‑V4 và sự hợp tác sâu sắc với hệ sinh thái Ascend.
Vào ngày 24 tháng 4, phiên bản xem trước của DeepSeek‑V4 đã chính thức được phát hành. Cả hai mẫu Pro và Flash mã nguồn mở đều hỗ trợ bối cảnh siêu dài 1 triệu mã thông báo. Kiến trúc chú ý thưa thớt tự phát triển giúp giảm đáng kể mức tiêu thụ sức mạnh tính toán suy luận. Sức mạnh tính toán của một mã thông báo của phiên bản Pro chỉ bằng 27% so với V3.2 và bộ nhớ đệm KV giảm xuống 10%, giúp tối ưu hóa chi phí từ lớp dưới cùng.
Các thông số do DeepSeek công bố cho thấy DeepSeek‑V4‑Pro có 49B thông số kích hoạt và 33T dữ liệu đào tạo trước, định vị nó là một chiếc đầu tàu hiệu suất cao; DeepSeek‑V4‑Flash có tham số kích hoạt 13B và dữ liệu huấn luyện trước 32T, tập trung vào tốc độ cao và chi phí thấp.
So với mẫu thế hệ trước, khả năng của Tác nhân DeepSeek-V4-Pro được nâng cao đáng kể. Trong đánh giá Agentic Coding, V4-Pro đã đạt mức tốt nhất trong các mô hình nguồn mở hiện tại và cũng hoạt động tốt trong các đánh giá khác liên quan đến Agent. Được biết, DeepSeek-V4 đã trở thành mô hình Mã hóa tác nhân được các nhân viên nội bộ của DeepSeek sử dụng. Theo phản hồi đánh giá, trải nghiệm sử dụng tốt hơn Sonnet 4.5 và chất lượng phân phối gần với chế độ không suy nghĩ của Claude Opus 4.6, nhưng vẫn có một khoảng cách nhất định với chế độ suy nghĩ của Opus 4.6.
Trong đánh giá tri thức thế giới, DeepSeek-V4-Pro vượt trội đáng kể so với các mẫu mã nguồn mở khác, thua kém một chút so với mẫu mã nguồn đóng hàng đầu Gemini-Pro-3.1. Trong đánh giá về toán học, STEM và mã cạnh tranh, DeepSeek-V4-Pro đã vượt qua tất cả các mô hình nguồn mở được đánh giá công khai hiện nay và có thể so sánh với các mô hình nguồn đóng hàng đầu thế giới.
So với DeepSeek-V4-Pro, DeepSeek-V4-Flash thua kém một chút về kho tàng kiến thức thế giới nhưng lại cho thấy khả năng suy luận chặt chẽ. Do các tham số mô hình và kích hoạt nhỏ hơn nên V4-Flash có thể cung cấp các dịch vụ API nhanh hơn và tiết kiệm hơn.
DeepSeek-V4 cũng đi tiên phong trong cơ chế chú ý mới nén theo chiều mã thông báo và kết hợp nó với chú ý thưa thớt DSA (Chú ý thưa thớt DeepSeek) để đạt được khả năng ngữ cảnh dài hàng đầu thế giới và giảm đáng kể yêu cầu về bộ nhớ điện toán và video so với các phương pháp truyền thống.
Điều đáng chú ý hơn nữa là toàn bộ dòng sản phẩm siêu nút Ascend đều hỗ trợ các mẫu dòng DeepSeek V4. Điều này cũng có nghĩa là DeepSeek phát hành nhiều tín hiệu bản địa hóa hơn.
DeepSeek-V4 đã đề cập trong một báo cáo kỹ thuật, "Lược đồ EP (Expert Parallel) chi tiết đã được xác minh trên hai nền tảng, GPU NVIDIA và NPU Huawei Ascend. So với đường cơ sở không hợp nhất mạnh mẽ, lược đồ này đã đạt được khả năng tăng tốc 1,50-1,73 lần trong các tác vụ suy luận chung; trong các tình huống nhạy cảm với độ trễ như triển khai học tăng cường (RL) và Dịch vụ đại lý tốc độ cao), lên tới Tăng tốc gấp 1,96 lần "
DeepSeek nhấn mạnh rằng với việc toàn bộ loạt sản phẩm siêu nút Ascend được ra mắt theo đợt vào nửa cuối năm nay, giá của phiên bản Pro dự kiến sẽ giảm đáng kể.
Sau khi phát hành DeepSeek-V4, Goldman Sachs đã công bố một báo cáo phân tích chỉ ra rằng tầm quan trọng cốt lõi của DeepSeek V4 là hỗ trợ triển khai các ứng dụng tác nhân phức tạp hơn với chi phí thấp hơn, từ đó mở ra một không gian mới cho quy mô ứng dụng AI. Về việc bao gồm các siêu nút Ascend, Goldman Sachs tin rằng khả năng cạnh tranh về chi phí của DeepSeek sẽ được tăng cường hơn nữa, tạo điều kiện cho nhiều ứng dụng hơn. Ngoài ra, trong bối cảnh chip tiếp tục bị thắt chặt, xu hướng chuyển các mô hình AI hàng đầu của Trung Quốc sang sức mạnh tính toán trong nước đã được các hãng hàng đầu xác nhận rõ ràng.
Báo cáo của Goldman Sachs cũng trích dẫn tin tức cho biết Tencent và Alibaba đang đàm phán để đầu tư vào DeepSeek với mức định giá hơn 20 tỷ USD. Giá trị thị trường mới nhất của Zhipu và MiniMax lần lượt là khoảng 53 tỷ USD và 31 tỷ USD. Giao dịch tiềm năng này phản ánh logic của những gã khổng lồ trong việc cạnh tranh để có được khả năng AI cấp cao khan hiếm.
Huatai Securities tin rằng thị trường dễ hiểu V4 là "giảm chi phí và giảm sức mạnh tính toán cũng như yêu cầu lưu trữ", nhưng thay đổi cận biên quan trọng hơn là sau khi giảm chi phí cho bối cảnh dài, tính khả dụng của các Tác nhân phức tạp, phân tích nhiều tài liệu, nhiệm vụ dài hạn, học tập trực tuyến và các tình huống khác sẽ được cải thiện, đồng thời số lượng cuộc gọi suy luận và tần suất truy cập lưu trữ dự kiến sẽ tăng lên.